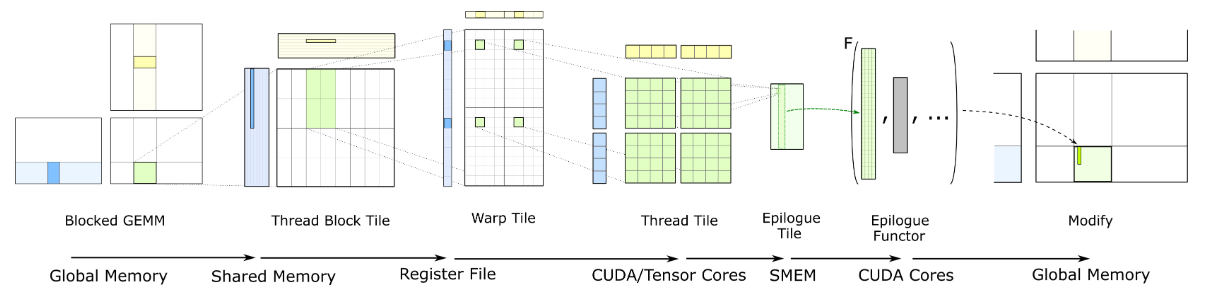
从sgemm算子入手,学习如何编写GPU算子kernel。
主要参考如下两个博客:(1)How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog;(2)Inside NVIDIA GPUs: Anatomy of high performance matmul kernels。
GPU必知必会
这一部分大量参考:https://www.aleksagordic.com/blog/matmul。**强烈建议阅读原文**。
GPU架构解读
GPU计算单元
GPU存储单元
- gmem
- smem,主要参考Notes About Nvidia GPU Shared Memory Banks一文。
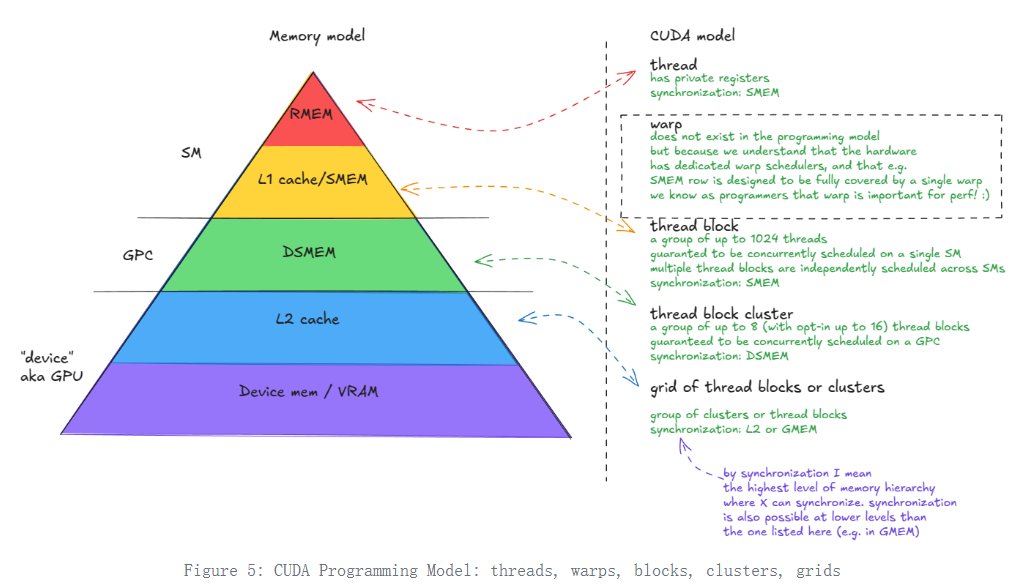
GPU编程抽象
GPU assembly:PTX & SASS
性能metrics
Occupancy
Wave occupancy
Warp occupancy
GPU算子优化路线(RoadMap)
初学者路线:同步算子实现
主要参考 How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog 以及 CUTLASS roadmap。
同步SOTA算子的主要技术点如下:
- 多层级tiling
- BlockTiling:利用SMEM缓存
- ThreadTiling:提高指令并行度,一般选择借助于寄存器做外积
- WarpTiling:减少bank conflict瓶颈 (warp broadcast技术?remain check)
- 用 warp broadcast 提升数据复用
- shared memory 访问模式规则化
- 让 bank conflict 可以“提前设计避免”
- 矩阵转置+向量化
- 借助于SMEM完成矩阵转置:牺牲store时候的bank conflict,大幅提升 load时候的向量化(load远比store多)
- 向量化,借助于LDS.128等intrinsic
进阶路线:引入异步
主要参考 Inside NVIDIA GPUs: Anatomy of high performance matmul kernels 和 Outperforming cublas on H100
- TensorCore单元
- TMA机制
参考资料
核心
- How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog
- Inside NVIDIA GPUs: Anatomy of high performance matmul kernels
- How CUTLASS do Efficient Matmul?