这一专题主要是记录我的paper阅读过程,按照不同前沿方向进行整理,以求理清不同前沿方向基本概念框架,目前进展和局限瓶颈,促进自己的编译研究工作。
本次分享AStitch: Enabling a New Multi-dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures,是阿里PAI部分工作。
TLDR
TLDR章节尝试用最简的话阐述清楚paper的动机,方法与贡献。
动机
Astitch的动机十分简单,基于作者的如下两个observation:
- 现有的XLA,tensor-rt等编译加速技术无法针对访存密集算子做高效融合。
- 大模型时代(transformer based),访存密集算子在整个模型计算图中数量占比高,性能占比也很高,逐渐成为训练推理的性能瓶颈。
进一步深入分析XLA/Tensor-RT等编译器,论文中总结出了如下几个核心问题:
- 访存密集算子的依赖关系是two-level的(element-level和operator-level),fusion更加困难。XLA/TVM等编译器往往引入大量重复计算开销,或是干脆直接不融合,性能提升很小。
- AI编译器服务一个模型必须是JIT模式,前期大量的AOT优化工作没有实际生产意义。
- tensor有大量非常规形状,XLA/TVM的代码生成往往没法自适应shape形状生成高效的线程映射代码。
方法
基于上述动机和核心问题,Astitch做了如下尝试:
- 整个编译器是JIT模式。即TensorFlow/Pytorch自动圈图,Astitch编译优化后再由TensorFlow/Pytorch的runtime发射运行。
- Astitch提出的Stitch访存密集优化:
- 针对不同类型operators,提出四类融合策略。
- 多层级的数据重用技术。具体有thread reg,shared memory和global memory三个层级。
- 自适应thread mapping技术。解决cuda blocks数量过少,或单个block计算量太小没法打满threads两种情况。
- 最终的Astitch,支持训练+推理优化。
本篇paper提供docker环境,经测试是可复现的。Astitch技术也应用于阿里的BladeDISC开源编译器项目。对BladeDISC项目感兴趣的可以参考BladeDISC github以及BladeDISC paper。
Deep Dive
从四个小节来详细解读Astitch paper:
- 背景
- 瓶颈分析
- Astitch的关键技术
- 工程实现框架与细节
背景
Astitch部分的背景其实十分简单,整个叙事如下:
访存密集算子值得关注!!!
transfomer时代下,模型往往有大量的访存密集算子。对于GPU这样的硬件加速器,访问存储算子逐渐成为主要的开销,原因如下:
- 相比访存算子,计算密集算子往往有高效的手写算子库,或是大量前期算子融合编译工作,性能上有保障。
- 访存密集算子涉及大量的off-chip存储访问。(:key:Astitch的核心关注点)
- 访存密集算子量大且不好融合,带来巨大的kernel launch以及context switch开销。(:ghost:微软的Rammer等工作关注这些非计算开销)
论文中进一步给访存密集算子分类,分为(1)逐元素算子(2)规约算子。其中逐元素算子又进一步分为light-weight(add / sub这种硬件上实现简单的计算)和heavy-weight(tanh这种复合计算)。值得注意的是,broadcast算子算作逐元素算子。

论文对Bert等模型做了perf,得出截图中的结论,可以看到reduce算子,broadcast算子的占比相当高,表明论文研究的问题是有意义的。
XLA/TVM等SOTA编译器算子融合能力十分局限
论文中一个很有意思的观点:算子融合能力取决于后端代码生成能力。只有在编译器后端能够针对特定pattern生成高效的代码(比如面向GPU生成GPU IR),前端融合才有价值。
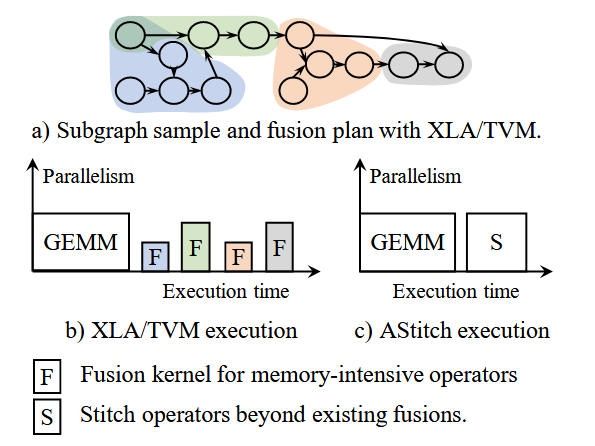
目前XLA/TVM的代码生成,只支持将producer元素one to one inline到consumer,大量潜在的访存密集融合难以支持。如下图所示,XLA的融合可以归结为kLoop和kInput融合,条件比较苛刻。对于XLA融合感兴趣读者建议参考Operator Fusion in XLA: Analysis and Evaluation。

瓶颈分析
这一部分强烈建议读者阅读paper的section2.3,对于理解算子融合和算子生成瓶颈大有帮助。论文中总结处两大瓶颈
瓶颈1:算子间存在两层依赖关系,高效融合很困难
该瓶颈依赖于如下观察:
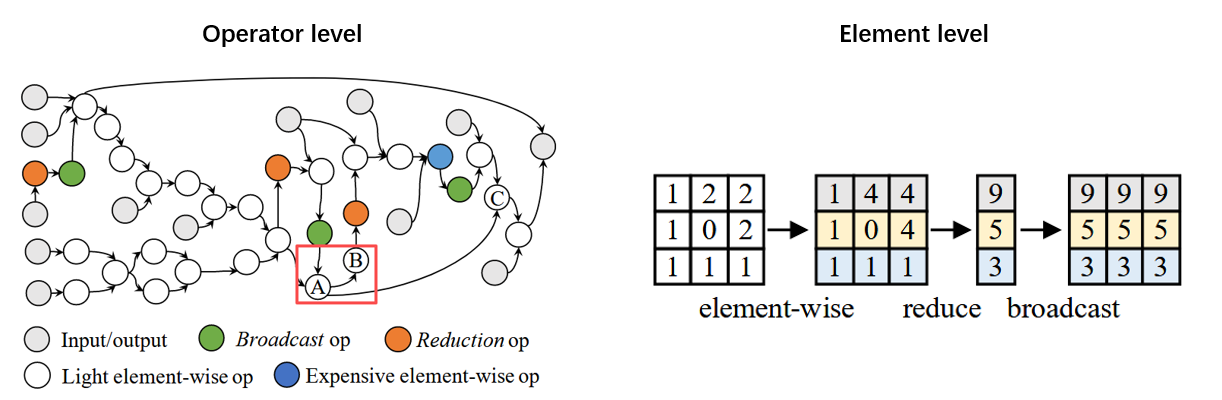
上图展示了一个计算图中的两个不同层级的依赖关系。A->B这种依赖是operator层级的依赖。而右图中element-wise->reduce->broadcast出了operator层级依赖,还存在element层级依赖,即一个element元素会被broadcast(one to many),也会被reduce(many to one)。operator依赖和element依赖同时存在,使得编译分析优化异常棘手。
接下来分别针对两个level,分析TVM和XLA在融合上的瓶颈。
Element level融合缺陷
XLA/TVM对于两种典型的element依赖pattern,无法做到高效融合:(1)reduce op -> consumer融合(2)计算量大的逐元素 -> broadcast。
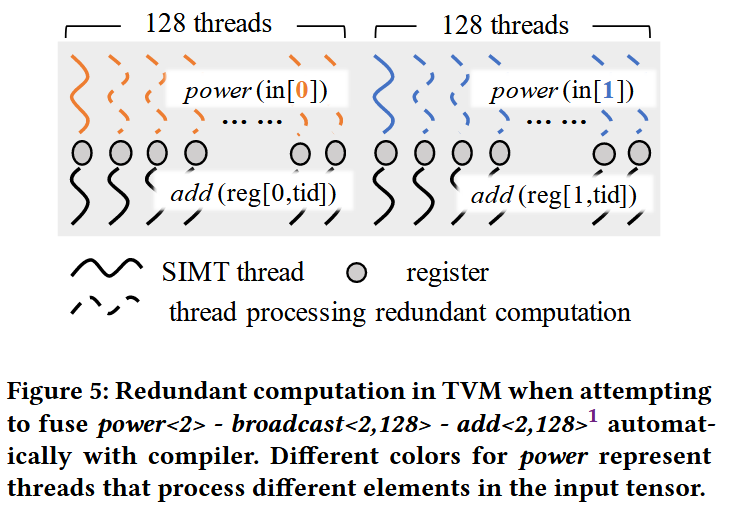
上图是论文中的case,其结构很简单:逐元素(light-weight) -> 广播 -> 逐元素(heavy-weight)。如果你是GPU kernel开发专家,你一定会把逐元素的结果存到shared memory,使得广播的每个thread能够高效获取结果。可惜的是,XLA/TVM仅仅支持per thread register共享数据,这种one-to-many通过shared memory的方式对于目前SOTA编译器是out of scope的。
因此,XLA/TVM有两种策略:
- duplicate计算然后融合。即add算子操作的每个element,都需要经过power处理,直接选择每个线程重复做一遍power计算。power计算是heavy-weight,开销无法忽略。而大模型中时常出现的一个场景是reduce后接broadcast(layer norm!!!),reduce极其占计算时间,这种duplicate操作根本无法接受。
- 单纯跳过。这种方案导致碎片化的kernel launch,大量的non-computation overhead!!!。
operator level,和element-level的fusion一样,会导致重复计算问题。
瓶颈2:动态shape,不规则shape导致低效代码生成
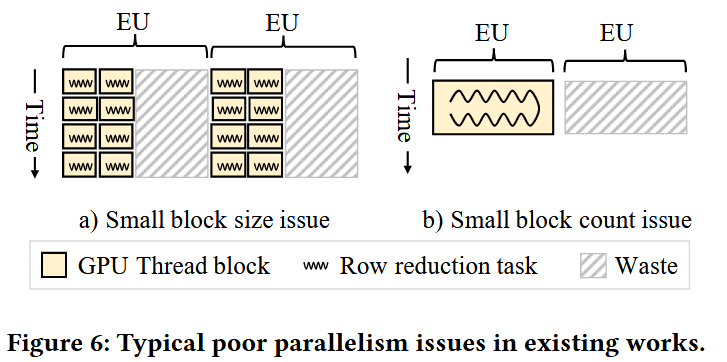
如上是论文中的case,主要分为两个问题:(1)block块过小(2)block数过少。
对于问题1,一个例子是DIEN模型中出现的将一个<750000,32> 归约到<750000>这样的pattern。关键问题是:
- 太多blocks,750000个。但是GPU能够并行运行的block数目是受限的,并行性很差。
- 每个block里的threads总共完成32个数据规约,计算任务过于小,block内部资源也无法打满。
对于问题2,transfomer模型中的极端case是对<64,30000>做行规约。以V100gpu为例,关键问题是:
- 编译自动生成64个threadblocks,每个block 1024 threads。
- V100gpu支持160blocks并行,硬件资源利用极低。
Astitch关键技术
详细剖析目前算子融合瓶颈后,Astitch给出了它的解决方案:多层级数据重用策略(应对瓶颈1) + 自适应线程映射(应对瓶颈2)。
多层级数据重用策略
Astitch首先定义了operator-stitch抽象,用来给每个operator做归类:
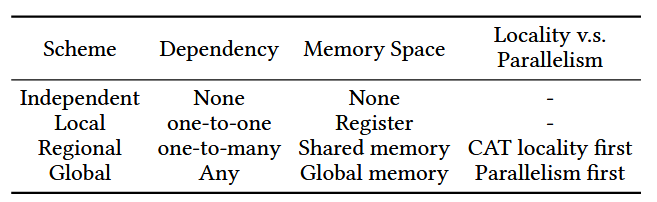
- independent:operator间无依赖,怎么融合都行
- local scheme:逐元素依赖,consumer直接用producer生成的每个thread的寄存器即可 (至此XLA/TVM均支持)
- Region scheme:适用于一个算子的某个元素输出会被 多个后续算子的元素使用这一情景。该策略支持一个 thread block内算出来的中间数据被block内多个线程复用。强制producer和consumer使用同一个thread block,即thread block 局部性。
- Global scheme:所有中间结果写入全局内存,不强制要求producer和consumer使用同一个thread block。任何算子可用此策略进行缝合。
后两个策略涉及tradeoff:并行度 vs. 局部性。如果使用Region策略,需要将相关线程装入一个block,可能无法打满GPU资源(原本可以用更多的thread blocks来获取更好地并行性)。因此针对不同场景,编译器需要能够自动做出选择(工程实践章节会重点展开论述)。
上述四个策略,使得Astitch在面对Operator-level/Element-level的数据重用场景,都能高效融合(借助于shared memory和global memory做缓存)。如下是论文中的case,论文没有对每个op如何选取策略做详细解释,仅做演示例子:
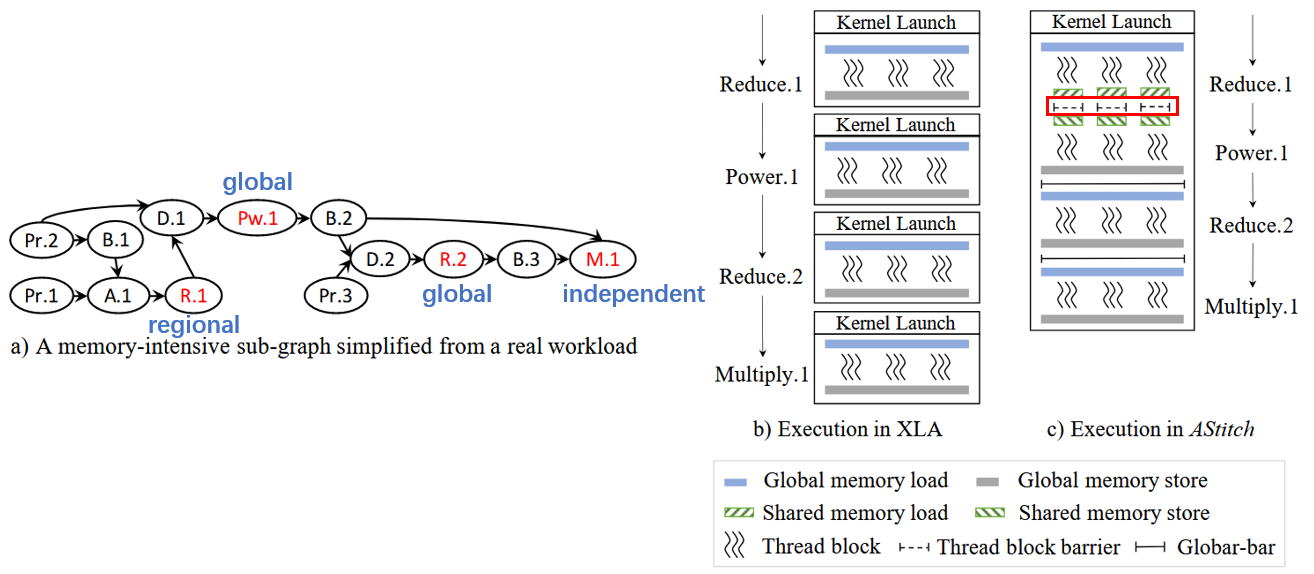
具体的收益如下:
- XLA 4次kernel launch,TVM 3次kernel launch(TVM能够融合R.1和Pw.1),而Astitch仅需1次kernel launch。降低kernel launch overhead,降低context switch overhead。
- R.1和Pw.1的融合,Astitch采用regional scheme,而TVM采用duplicate computation,显著的计算开销。
overhead如下:
- 融合R.1和Pw.1用的shared memory,需要在thread block内做线程级别同步。
- 其他global scheme,需要做thread blocks间同步。注意,这对于thread blocks个数有明确限制,超过GPU上限(160 for V100),会引入死锁。
自适应线程映射技术
这一块Astitch做的工作很好理解,提出Task-packing和Task-splitting策略,解决瓶颈2的两个问题。
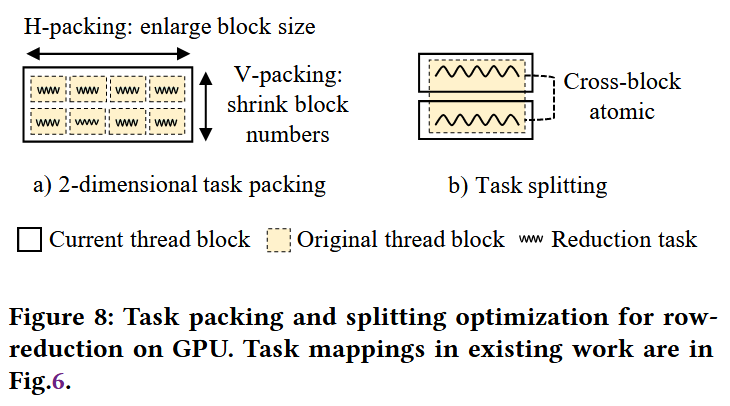
packing分为两个维度:横向和纵向。
横向packing解决block size过小问题。
例子是将<750000, 32>数据块,原本是一个thread block处理一行32个元素,做横向打包,变成<? , 32x32>,即一个thread block现在处理1024个元素。映射到线程上,32个线程处理一行数据(<750000,32>数据块shape不变,变的是thread映射),共处理32行(即<750000, 32> 变成 <750000/32块, 32行, 32列>)。一个warp处理一行,做reduction是极其高效的。
1
2
3
4
5
6
7Thread block (1024 threads)
│
├── threads 0–31 → row 0
├── threads 32–63 → row 1
├── threads 64–95 → row 2
...
├── threads 992–1023 → row 31:cry:文笔不行,写的很乱,勿喷。
纵向packing解决block数太多的问题。block太多的问题是如果一批thread blocks没法在同一wave上完成,则没法做thread blocks同步。解决方案是将多个block的任务变成一个block内顺序执行的任务。
Task-splitting解决的问题是block数目太少。以<64,30000>行规约为例,可以变成<128,150000>,即launch128个block做行规约,然后block之间还需要做跨block规约。
:question:思考一下为啥这种是划算的:
- block数目过少,则很多SM是空置的,而调度的SM计算量很大,需要做30000 partial sum。
- task-splitting后,产生的overhead是跨block做规约,只需要算两个数相加,整体计算overhead相比每个block算30000 partial sum还是划算的。
- 具体问题具体分析,如何界定reduction列数是否值得split?后续需深入CUDA reduction算子性能分析。
工程实现
Astitch提出的各种技术,面临和其他算子融合编译器(TASO?)一样的工程困境:
优化plan组合爆炸,导致编译确定plan pipeline时间巨长。搜索一小时获取极致优化,纯学术产物,没有任何实际生产价值。Astitch针对这个问题做了大量观察和思考,得以工程上平衡编译速度是实际性能。
工程实现环节主要解答如下几个问题:
- 如何决定哪些operators组成一个stitch region?
- thread mapping具体如何实现?
- 融合出的kernel如何确定launch时候的grid size和block size?
- 如何做成编译器的pass pipeline?如何工程化?
划分stitch区域
这一部分重点是:
- 确定哪些operators组成访存密集子图,即stitch区域。
- 确定stitch区域中的dominant operator,后续整个stitich区域的thread mapping完全取决于该dominant operator。
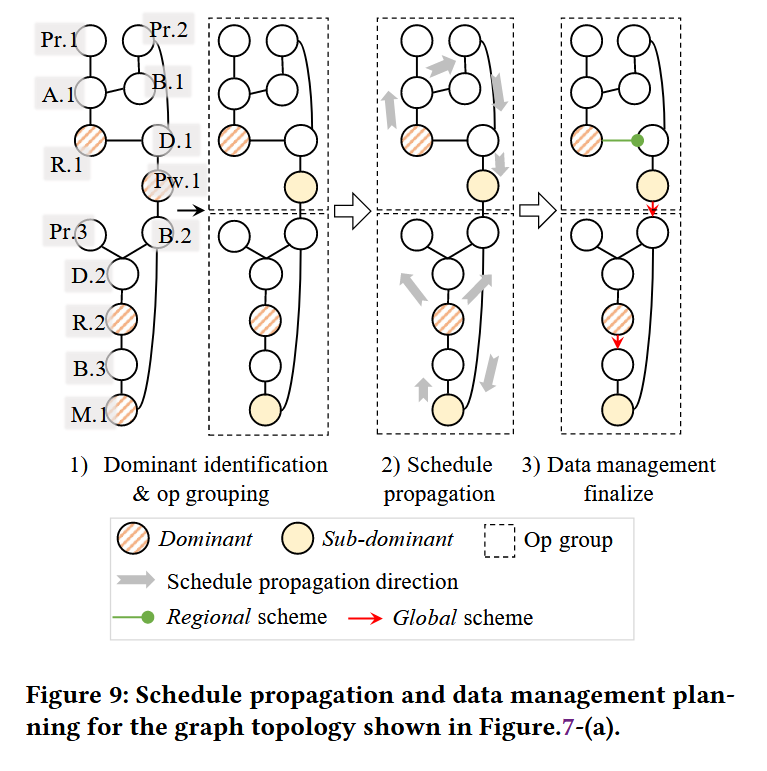
具体步骤如下:
用BFS做图遍历得到访存密集子图 ,并表示成一个stitch op。
做子图合并。遍历stitch op,如果两个stitich op没有依赖,则可以合并成一个大的stitch op。注意合并的另一条件是不能形成环。一个stitch op最终就是一个cuda kernel。
确定dominant op。
论文中选择reduce op以及heavy-weight逐元素+broadcast为潜在dominant操作。
- 因为逐个元素,或是light-weight逐元素+broadcast(duplicate是合适的),可以用local策略,local策略的thread mapping可以传播的,没必要做dominant。
- 倾向于reduce为dominant op,因为reduce需要高并行度,thread mapping应该优先考虑reduce的需求。
dominant 融合
当两个dominant op之间全是element-wise op,则一个dominant op的thread mapping确定,另一个也确定。退化选择方面,优先确保reduce op是dominant。
dominant op当做锚点,生成stitch region
:key:takeaway:
- dominant op/sub dominant op需要后续选择是regional/global,其他op都是local策略。
Thread Mapping实现
这一块也涉及两个发现:
**thread mapping存在传播机制:**和stich策略分配一样,作者发现只需对dominant op做好线程映射,同一stitch区域其他operator的线程mapping存在传播机制。
对于dominant op的thread mapping,以reduction op为例,Astitch使用如下机制:
- 如果行数(rows)< 每 wave 允许的 block,并且每行数据很多(>1024),做task splitting。
- 反之task packing,尽量打满每个thread block处理的数据(生成尽量大的block)。
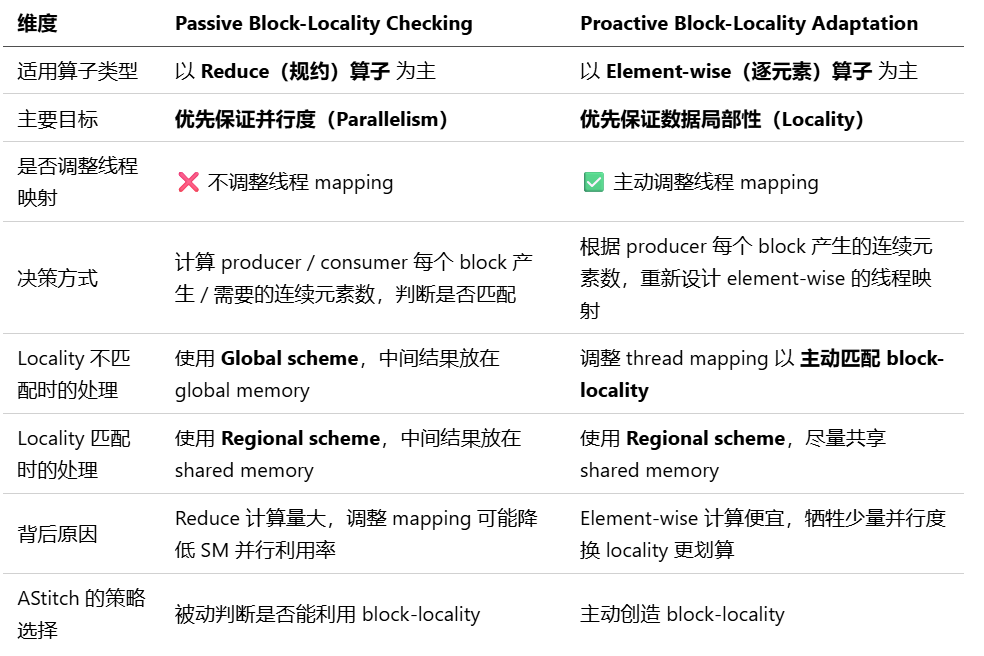
thread mapping传播过程中,可以同步完成对每个operator的stitch策略的选取:这一点基于一个共识:是thread register fusion,还是shared memory fusion亦或是global memory fusion,都依赖于两个operator的线程映射是哪种match。Astitch针对shared memory stitch策略,还引入两种机制:(1)被动的block局部性检查;(2)主动的block局部性自适应。
资源感知的 GPU Kernel 启动配置
这一块比较有趣。首选是Astitch的大尺寸stitch融合面临的一个重要难题:
AStitch 要求 GPU kernel 的启动配置必须满足一个关键约束:同一 wave 中活跃的 thread-block 数量不能超过硬件允许的最大值,记为:C-blocks-per-wave。这是因为 AStitch 在 stitch 后的 kernel 内部使用了 global barrier(全局同步),而全局同步对并发 block 数量有严格限制。
但现实中,存在一个“先有鸡还是先有蛋”的问题:C_blocks-per-wave 依赖于:
- 寄存器使用量
- 共享内存使用量
- block size
而而这些信息 只有在编译完成后才能准确得到。因此,AStitch 无法在优化阶段直接获取准确的 C_blocks-per-wave。
:question:如何解决
- AStitch 采用一种“假设–放松–应用”的寄存器约束策略:先假设一个很小的寄存器使用上限(如 32),据此结合共享内存使用和最大 block size(如 1024)计算
C_blocks-per-wave,以降低全局同步开销; - 然后判断并行度是否主要受共享内存而非寄存器限制,若是则反推出允许的最大寄存器使用量并放松约束;最后在生成 GPU IR 时通过编译器注解施加该寄存器上限。
- 在AStitch实验中未观察到寄存器溢出问题。
这一块值得更加深入地探讨和研究。具体如下:
- 启发算法背后原理?
- 启发算法如何保证soundness?
- 是否可以形式化?
工程上pipeline组建细节
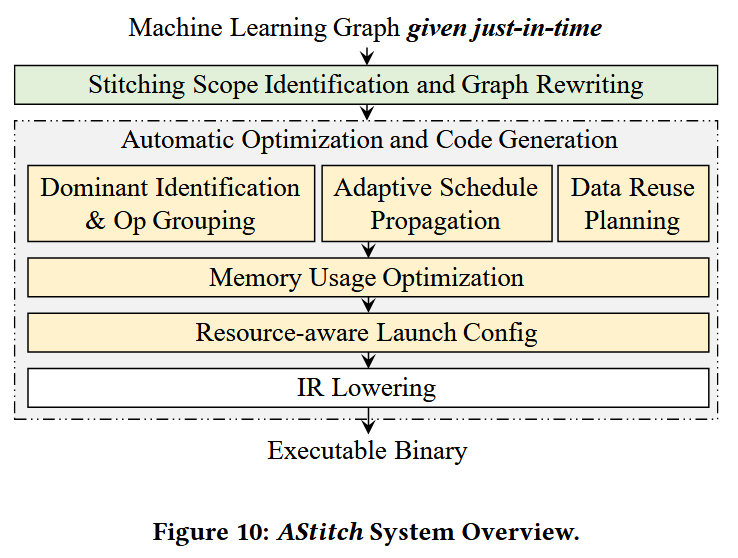
上述图十分清晰的展示了整个pipeline的布局。大多数passes我们都详细解读过,内存优化没有详细讨论,因为比较朴素:
- 借助于支配树,在数据流模型上做memory的live range分析。Astitch能够追求最大程度的operators间内存复用。
- 如果一个regional的operators需要的共享内存超出GPU限制,则在这一阶段退化成global策略。
我的一些疑问
- BladeDISC是阿里PAI后续的延伸工作,主要针对动态shape进行了更深入的研究(动态shape + Stitch融合)。后续结合BladeDISC开源源码进行分析。目前有如下疑点:
- 似乎GPU 生成默认没有开启Stitch,why?
- 编译算子融合,推理端和训练端需要考虑的因素差异是哪些?