硬件专题第二章,讲解AI芯片的数据编排。主要参考《Efficient processing of DNN》一书,强烈推荐。申明,本文大量引用《Data Orchestration 的设计哲学与演进》一文。
数据编排重要性
数据编排(Data Orchestration)是一门关于如何精确、高效地在存储层次结构中移动数据的艺术与科学。
数据编排指在编译期就静态配置好数据的传输网络(时间和空间两个维度均要确定好,即传给谁,什么时候传)。对于面向AI应用的Dataflow芯片,由于上层任务的规整性,设计良好的数据编排模型是十分有收益的(减少/合理化数据搬运,大幅降低能耗成本)。
一个好的数据编排要满足如下要点:
- 高效地且及时地传输消费者恰好需要的数据。
- 将未来所需数据的接收与当前所用数据的使用在时间上重叠起来。
- 在数据不再需要时将其立即移除。
- 并以精确且低开销的同步机制完成以上所有操作。
:key: 一个优秀的数据编排系统,必须在设计层面回答一系列根本性问题:数据应被置于何处(Placement Strategy)?何时进行传输(Timing)?数据的访问模式(Access Pattern)和生命周期如何 ?以及,当存在多个数据消费者时,它们之间如何协调与同步(Coordination and Synchronization)?
数据编排分类
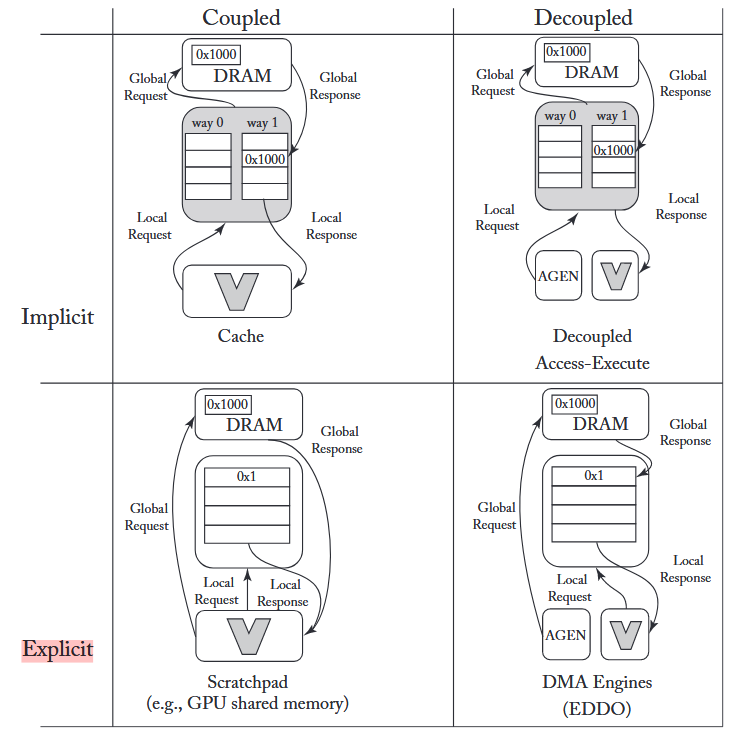
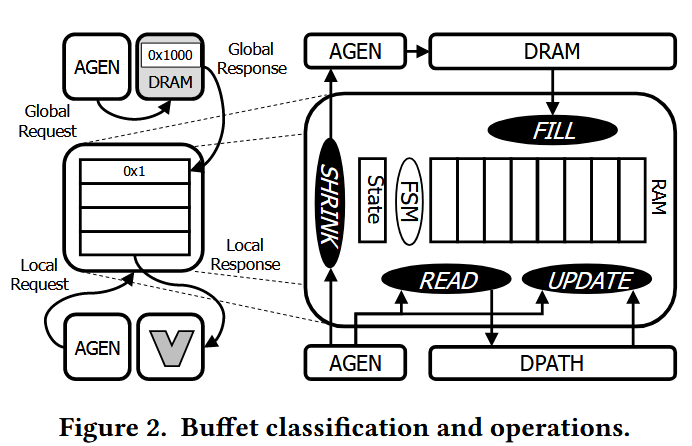
上图是数据编排的分类图,总共有两个象限(implicit/explicit以及coupled/decoupled)。下表是目前常用数据编排方案的分类划分:
对于AI加速器,其有如下要求以及特性:
- 高性能,低延迟,低功耗
- 计算任务比较规整,静态可确定
因此explicit + decoupled是比较合适的数据重排方案,原因如下:
explicit要求编译器显示控制数据的每一步传输,可以在编译期做极致的buffer优化,降低传输延迟以及功耗。相对的,implicit需要硬件控制,会占用一部分硬件area并带来更高的能耗。
对于AI-Core,由于是针对特定领域,结合领域信息,显示控制数据相比通用处理器(CPU)要可行。
decoupled通过解耦load指令发出者和接收者的方式,overlap计算和传输并减少memory占用。
接下来详细解读这几个分类:
显示 vs. 隐式
该维度定义了请求者在发起请求时,对数据物理位置的感知程度 。在隐式系统中,请求者对数据位于何级存储(如L1/L2 Cache或DRAM)一无所知,硬件会自动处理地址转换和数据迁移 。这种方式对上层软件屏蔽了底层复杂性,易于编程 。然而,其代价是高昂的硬件开销,例如用于追踪数据状态的标签(tags)和比较器逻辑 。相对地,在显式系统中,请求者(通常是软件或编译器)必须明确指定数据在存储层次间的移动路径和目标地址 。这种方式硬件开销极低 ,但对编程和编译器的要求极为严苛 。
补充一点,隐式还有一个大问题:landing zone问题。即发出request后,需要开辟一个存储区域用来填充回复的数据,这块存储区在整个回环(发出request,到接受数据)的过程中都要保留,造成内存资源浪费。
非解耦 vs. 解耦
该维度关注数据请求者(Requestor)与消费者(Consumer)是否为同一实体 。在耦合系统中,请求与消费由同一个处理核心执行,其优点是同步机制直观简单 ,但代价是消费者在等待数据时可能会陷入停顿(stall),从而限制了流水线效率 。而在解耦系统中,请求者与消费者分离,例如由一个专门的地址生成单元提前发起访存请求 。这使得访存延迟得以被隐藏在计算过程中,但引入了两者间更为复杂的同步需求 。
比较典型的解耦方式是引入DMA,搭配以double buffer提高计算-传输overlap。
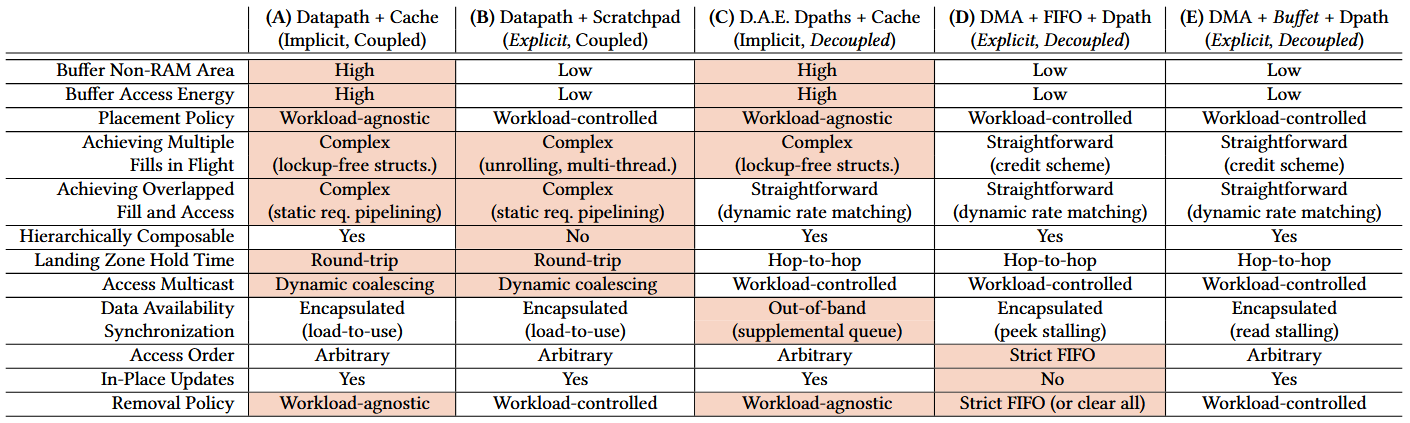
已有解决方案的对应分类以及pros & cons
- cache:implcit + coupled,其能耗对于AI芯片不可接受(tag标签和set associative极大电路空间资源占用)。
- scratchpad:explicit + coupled,可以显示的数据控制。比较典型的例子是GPU的SMEM。其问题是编程控制极其复杂且易出错,如果考虑性能,同步问题也很困难。GPU通过SIMT编程模型,巧妙规避了scratchpad同步的难题。 但在dataflow arch上,scratchpad是不可接受的。
- DAE:implicit + decoupled,DAE架构指的是两个processor通过hardware fifo通信,一个为生产者,一个为消费者。由于fifo队列的存在,两个processor可以有不同的timing。这里的producer相当于dma,DAE本质也是一种解耦机制。
- DMA+FIFO:dataflow芯片最常见的设计方式。fifo的好处是同步机制简单,坏处是AI任务通常是卷积操作,涉及partial sum。所以需要更新buffer里面的东西(读+update),fifo难以支持此类操作(读没法任意地址读,也没法in-buffer更新)。
EDDO
EEDO即explicit+decoupled。我们重点来解读Buffets论文,是目前最前沿的数据编排解决方案。
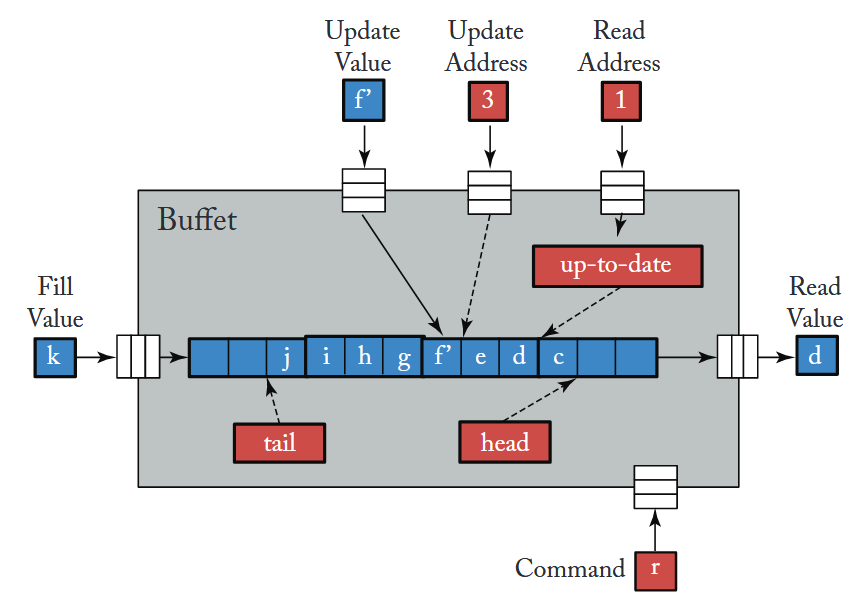
一种统一的数据编排框架:Buffets
其核心思想很简单,旨在融合FIFO的流式效率与Scratchpad的随机访问能力。