硬件专题,每一章解读一个AI芯片,主要从硬件架构,软件栈等角度进行解读,查漏补缺。同时关注到今年的MICRO25的一篇PytorchSim的NPU仿真工作,在拓展部分也会结合这篇文章开展更详尽的讨论。
NPU基础架构
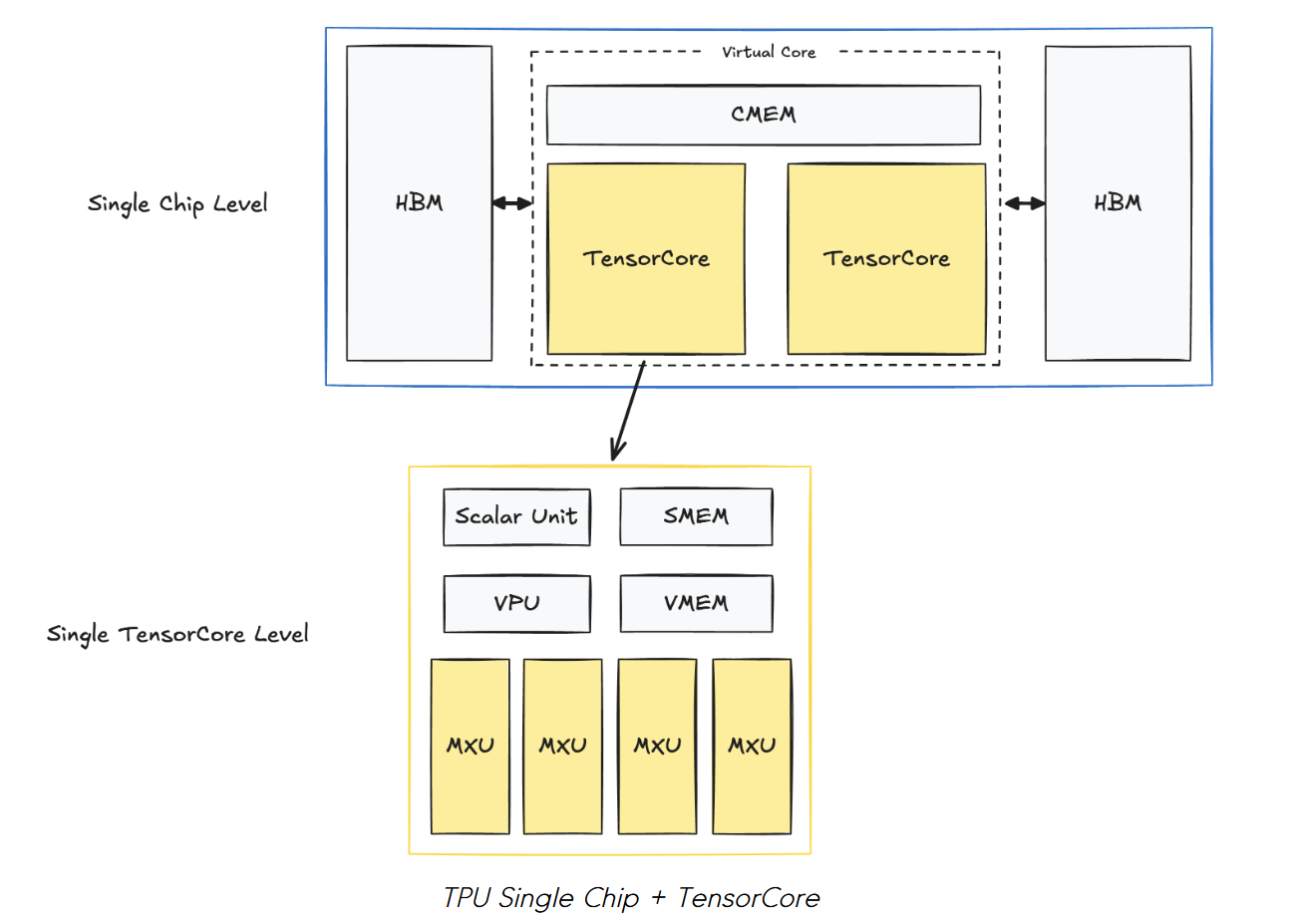
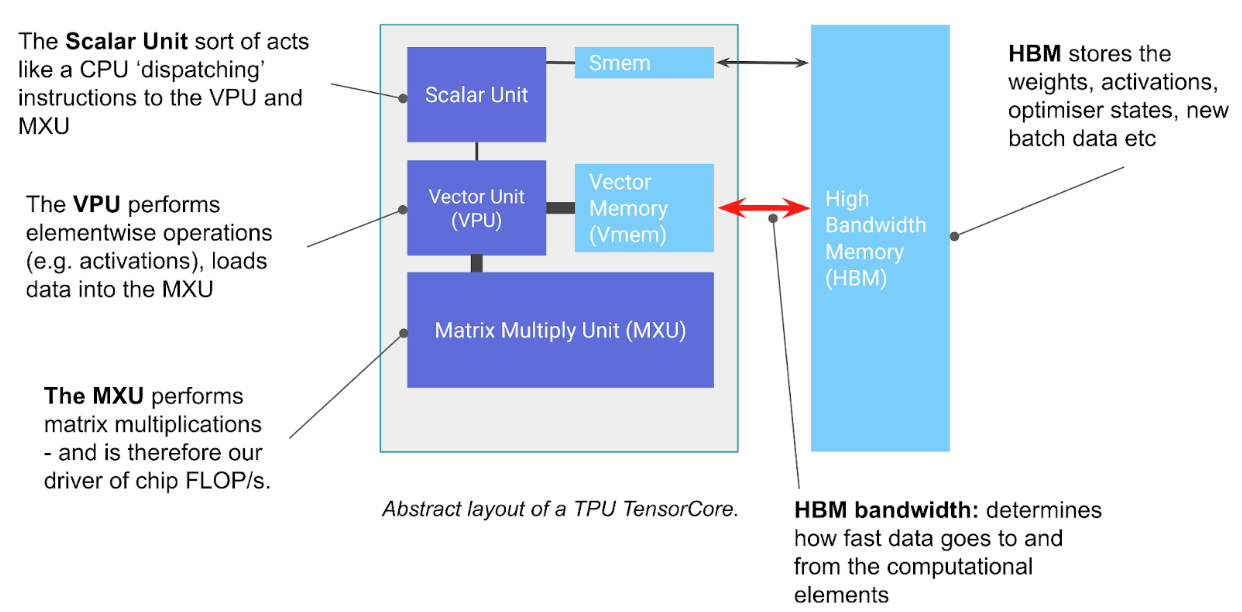
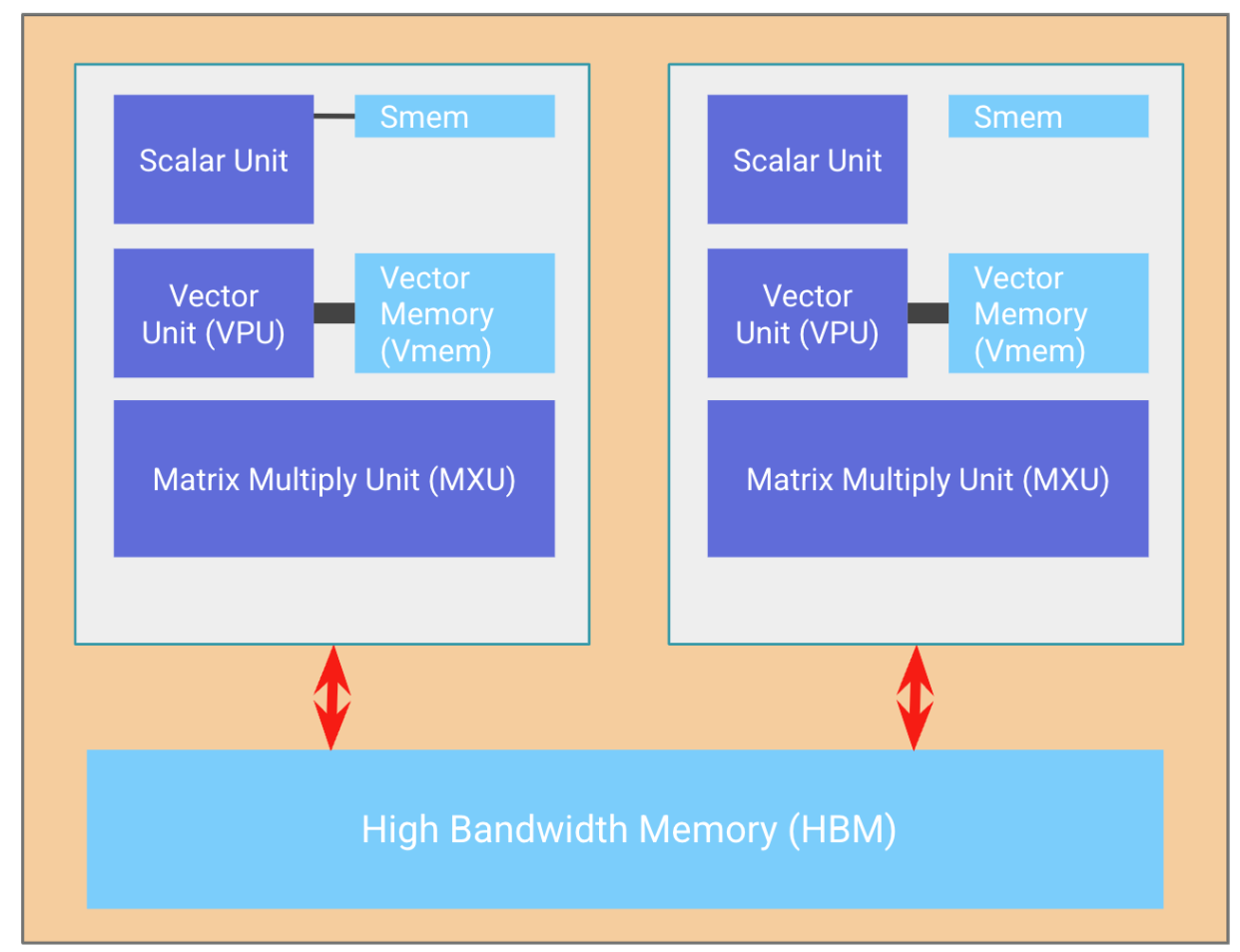
上图是NPUv2的架构图,仅仅支持推理。整个架构的存储体系结构分为三级别:
- HMB:片外存储空间(32GiB)
- CMEM:片上存储空间,两个tensor core共享区域(128MiB)
- VMEM和SMEM:每个tensor core的local存储空间,一个是向量存储(32MiB),一个是标量存储(10MiB)
对比GPU的存储体系结构,CMEM、VMEM和SMEM都比GPU的L1、L2 cache大,但是HBM比GPU的小
计算单元上,主要分为三类:
- MXU:矩阵乘处理单元,是tensor core的核心。内部是128x128的脉动阵列。
- VPU:向量处理单元,主要处理诸如Relu,Reduction等操作。
- Scalar Unit:标量处理单元。
:question:TPU相比GPU,其处理核心远少于GPU的处理核心,所以TPU是如何达到高吞吐同时低功耗的?
NPU的魔法
NPU为什么高效,主要源自于其两个结构+模型的一个特征:
- NPU的脉动阵列 + 流水技术
- NPU的AOT编译技术(:key:google的XLA编译器很强大)
- DL模型大多是矩阵乘加运算,比较规整,极其适配脉动阵列
脉动阵列
下图比较清楚地展示了脉动阵列的原理:
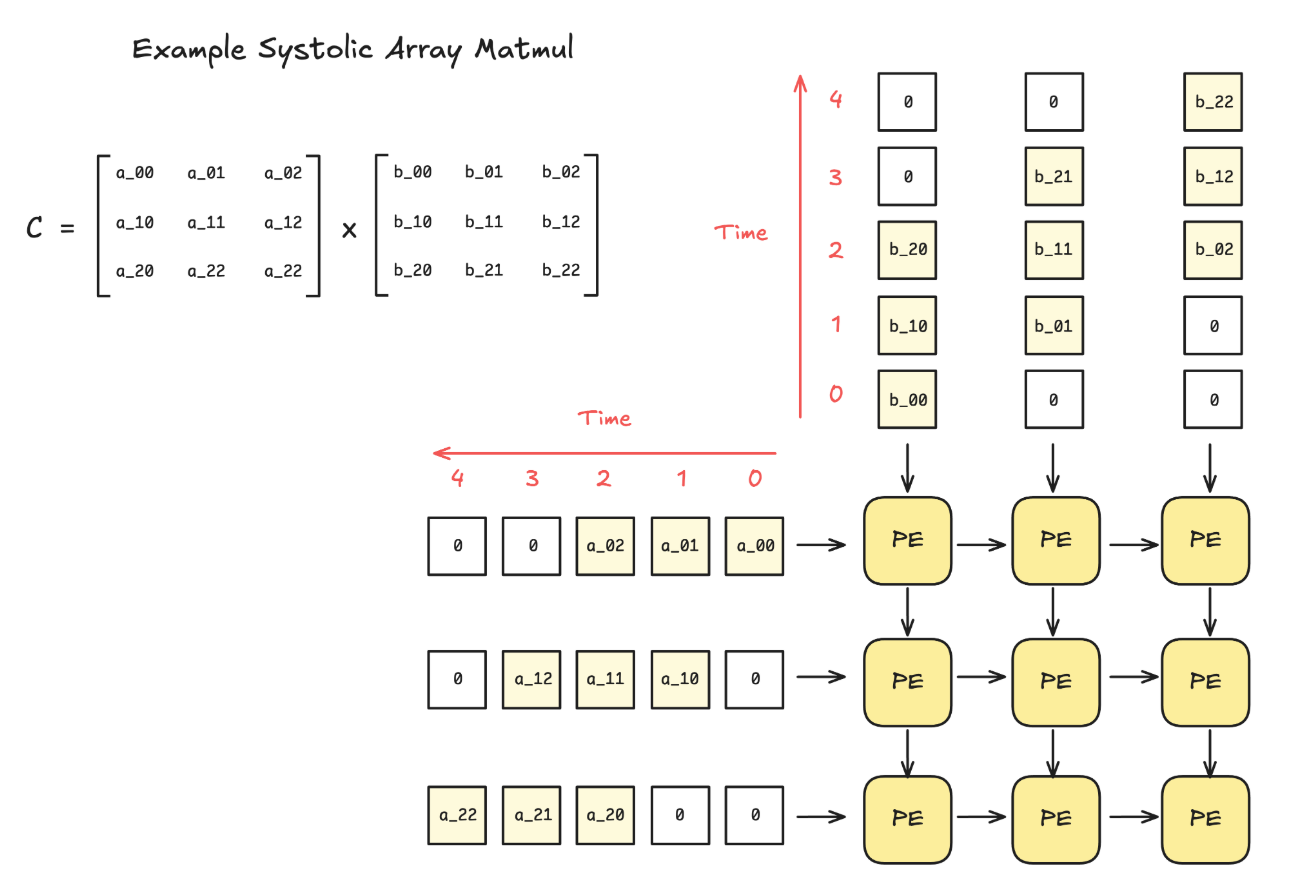
更详细的介绍,参考CMU arch课程
:question:如何对于脉动阵列做overlap?Scale book中给出了答案:
这种架构的优点很明确:
- 节省memory,节省memory bandwith
- 效率高,多pe互联
缺点也很明确:
- 需要计算任务完美适配脉动阵列,比如稀疏计算对于Systolic Array就是灾难。
编译-硬件 co-design
脉动阵列的另一个大优势是没有cache缓存结构。面对DL任务,编译器需要将模型的每一层静态编译map到脉动阵列上,所以所有内存模型也是编译可确定的。这导致的结果就是编译器可以机制的优化内存复用,传统架构的cache机制在TPU中可以被scratchpad所替代。
这一部分具体内容十分复杂,google主要研制了XLA编译器,支持AOT/JIT混合编译,即AOT编译子图,JIT的方式调用运行。感兴趣读者自行参考XLA官方文档。
TPU集群
为了满足google的云推理服务需求(google最早是为了语音ai启动TPU项目,目前主要业务是广告推荐等应用场景),TPU的设计一大核心特点就是易于扩展(scale)。
下表按层次结构组织了TPU的各个核心概念,并概括了其定义、关键技术特性和设计优势。
| 架构层级/概念 | 描述与定义 | 关键技术/拓扑 | 关键特性与设计优势 |
|---|---|---|---|
| 芯片 | 计算的基本单元,专为线性代数计算的ASIC。一般包含两个chip | - | 包含矩阵乘单元等核心计算部件。 |
| Tray | 基础物理封装单元,通常包含4个TPU芯片。 | ICI | 芯片间通过高带宽的ICI互联,形成一个紧密的计算模块。配备主机CPU通过PCIe连接。 |
| Rack | 物理机架,包含多个Tray(如TPUv4 Rack含4x4x4个芯片)。 | 3D Torus (TPUv4) 2D Torus (v2, v3, v5e) |
通过ICI和OCS连接芯片,形成立方体结构。OCS提供环绕连接,减少通信跳数。 |
| Pod (SuperPod) | 通过ICI/OCS互联的最大TPU集群单元(如TPUv4 Pod含4096芯片)。 | 3D Torus of Racks | 代表单一大规模机器学习训练任务所能使用的最大、最快的计算单元。 |
| Slice | 在一个Pod内,通过OCS动态划分出的TPU子集。 | 可配置(立方体、雪茄形等) | 核心灵活性: • 拓扑即超参数 • 非连续分配 • 可重构拓扑(支持扭曲环面) |
| Multi-Pod | 多个Pod通过数据中心网络联合工作。 | DCN | 用于超大规模训练,Pod间通信带宽低于ICI。 |
| ICI | 芯片间互联,TPU专用的高速内部网络。 | 2D/3D Torus | 提供极高带宽和低延迟,使TPU芯片能像统一内存系统一样工作。 |
| OCS | 光电路交换,用于灵活的芯片连接。 | - | 三大优势: • 环绕连接优化网络 • 实现非连续切片 • 支持拓扑重构 |
Chip
chip结构如下:两个TPU core,搭配一个共享的HBM。
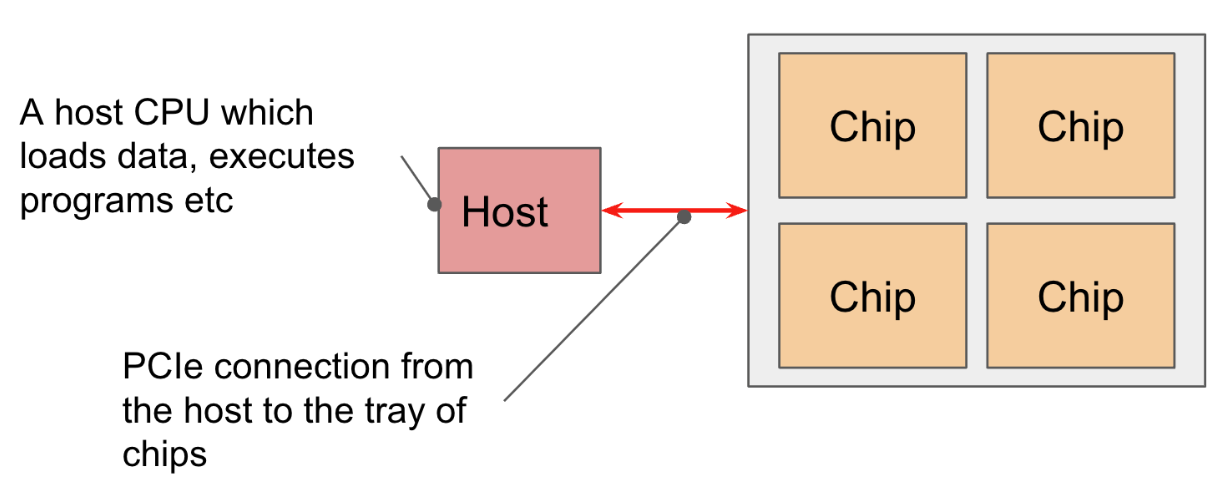
Tray
一个Tray一般有4个Chip,并有host通过PCIe总线连接控制。
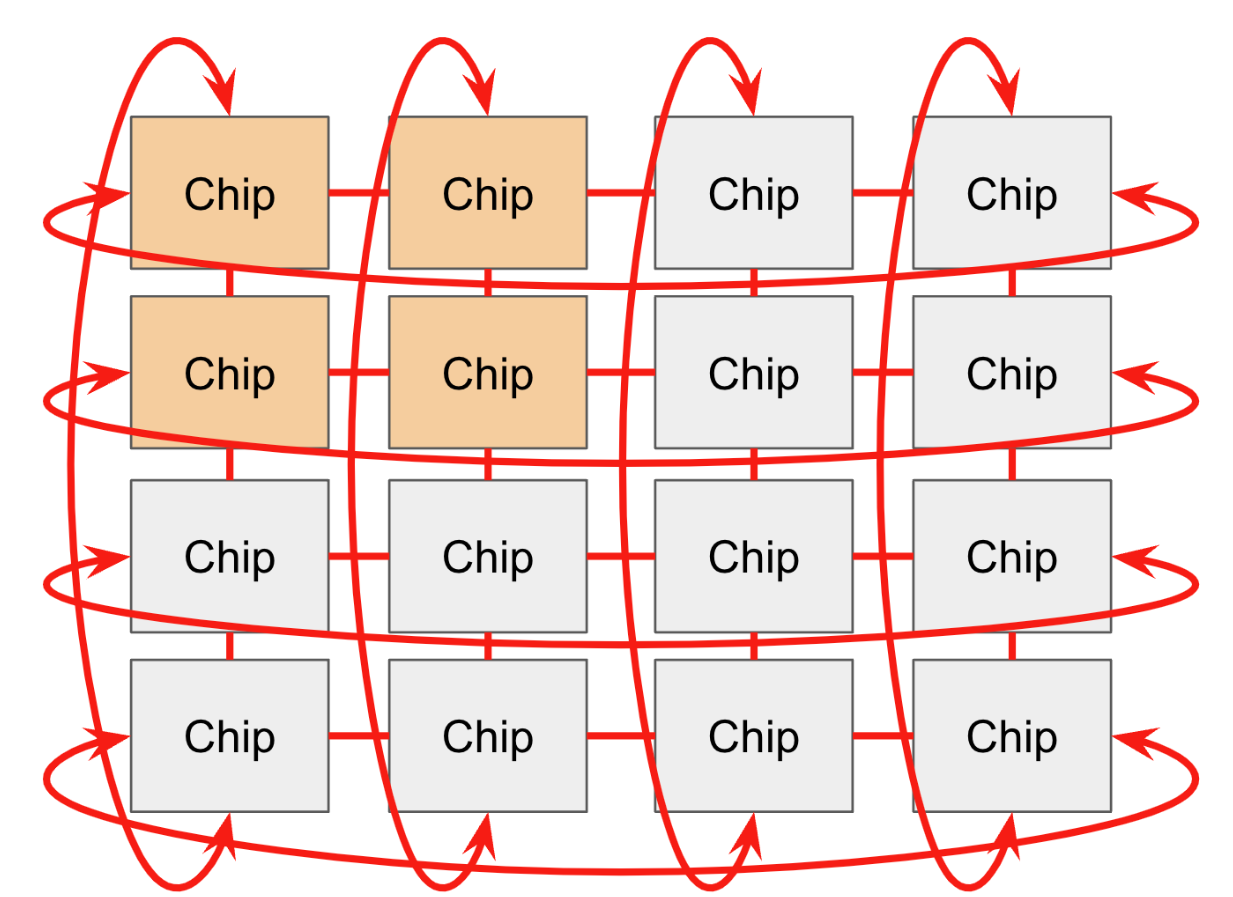
Pod
在一个pod中,每个chip可以和邻居4个方向或6个方向(3D 拓扑网络,专业名称ICI)互联。
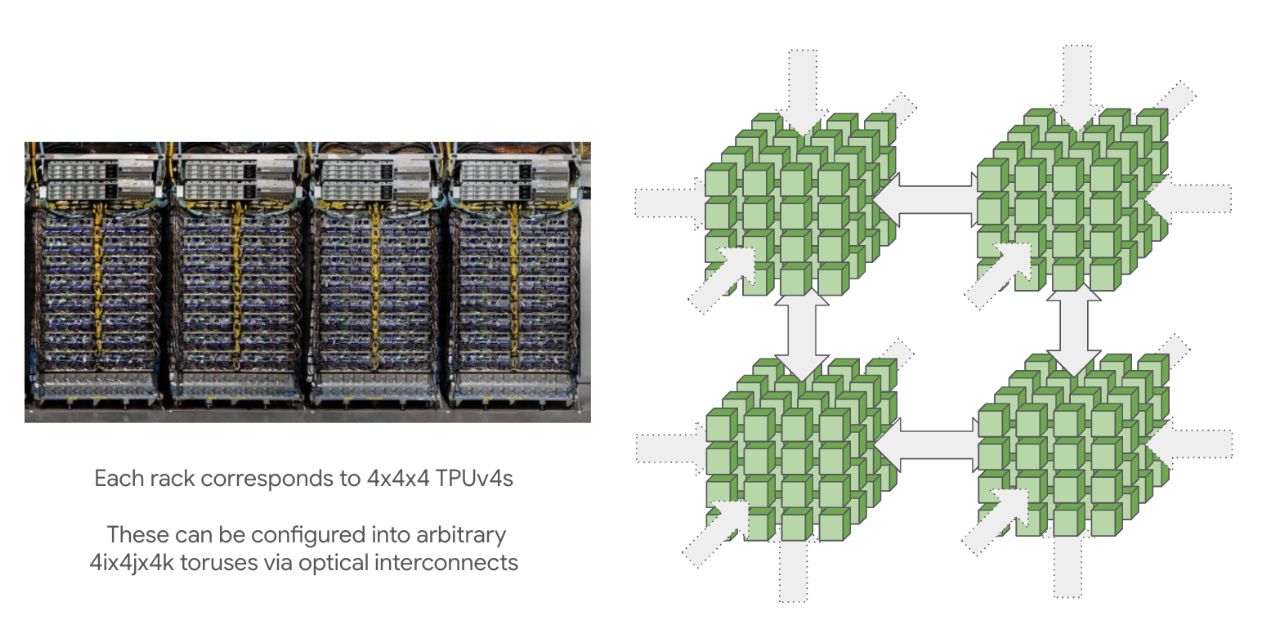
MultiPod
Pod里面的chip数可以很大,最大的(superpod)可以达到16x16x16(TPU v4)以及16x20x28(TPU v5P)。一个可重构cube是4x4x4,每个pod都是由这些cube组成,通过 optical wraparound links互联(是可重构的)。
对于TPU和GPU互联机制,书中的一些思考:
This nearest-neighbor connectivity is a key difference between TPUs and GPUs. GPUs are connected with a hierarchy of switches that approximate a point-to-point connection between every GPU, rather than using local connections like a TPU. Typically, GPUs within a node (8 GPUs for H100 or as many as 72 for B200 NVL72) are directly connected, while larger topologies require O(log(N)) hops between each GPU. On the one hand, that means GPUs can send arbitrary data within a small number of hops. On the other hand, TPUs are dramatically cheaper (since NVLink switches are expensive), simpler to wire together, and can scale to much larger topologies because the number of links per device and the bandwidth per device is constant. Read more here.
提炼一下:
- GPU有平均最好的P2P互联hop数
- GPU的NVLink带宽高,速度快,但是昂贵(主要是NVLink的交换机贵)
- TPU的互联数对于每个点是恒定的,可扩展性极强
- TPU互联有明显的空间特性(邻居特性),完美适配AI任务
对这块感兴趣的读者,可进一步深入Scaling Book: all about TPUs 和TPU vs. GPU