这一专题主要是记录我的paper阅读过程,按照不同前沿方向进行整理,以求理清不同前沿方向基本概念框架,目前进展和局限瓶颈,促进自己的编译研究工作。
引言:粗粒度可重构阵列(CGRA)
什么是CGRA?
CGRA是一种介于通用处理器(CPU)和专用加速器(TPU)的新型计算架构。其核心优势是:
- 具有像ASIC专用加速器一样的并行能力,通过硬件并行化和定制数据流优化实现。
- 具有像CPU一样的灵活性,支持运行时重构已适配不同任务。
CGRA架构特点
CGRA的架构思想主要是将计算和传输都做了空间层面的分配,总结下来是如下两点:
- 相比传统的冯诺依曼架构,CGRA通过其空间-时间并行性,支持将数据流图中的不同操作静态映射到不同的处理单元(PE)上执行。这种架构极大地减少了传统指令流水线中指令取指/译码、集中式寄存器访问和流水线寄存器所带来的开销,从而在能效上具有显著优势。
- 相比传统架构的寄存器存取,CGRA直接通过NoC在互联的PE上传输数据。
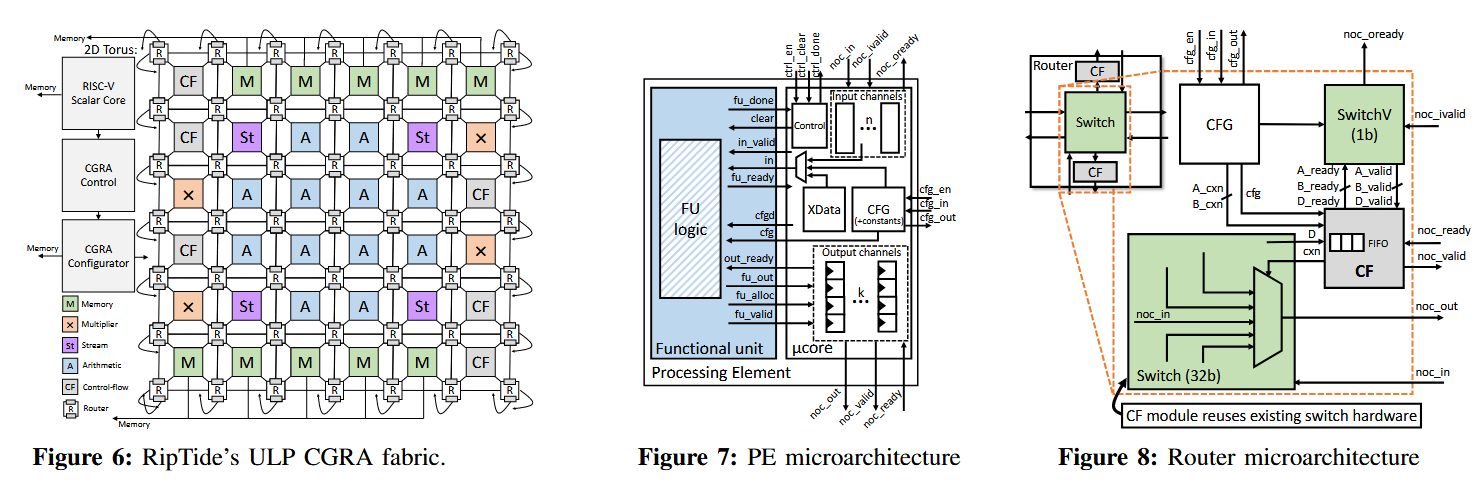
如图所示是RipTide论文中设计的CGRA架构,后续章节会详细解读RipTide论文,这里只是借用架构图讲解CGRA架构的一些特点和细节。
- CGRA架构的核心是2D的PE阵列。一个PE一般包含FU(功能单元)做基本运算和内存访问操作,并有register file存储临时变量。PE中一般还包含config mem,用于存储配置单个PE的FU和reigster的配置序列。
- PE阵列通过NoC高速互连。每个PE都通过switch连接到其邻居PE,并且可以把计算结果传输到指定的邻居上来进行下一个cycle的计算。每个单独的PE执行的计算以及通过互连将数据路由到邻居都可以按周期为基准进行配置(config mem配置序列控制)。
- PE阵列可以在空间上(不同PE独立配置序列),时间(配置序列按照周期控制单个PE)上两个维度进行配置。
- CGRA是可重构的,即可以重新给整个PE阵列新的配置序列(从外部存储load进CGRA),但存在初始设置时间开销。
为什么CGRA高效且低功耗?
CGRA同时具有低功耗,灵活性和不错的性能,主要依赖于如下几个架构特点:
规避冯诺依曼体系的指令overhead和集中式寄存器机制开销
更充分的并行性挖掘
对比DSP/GPU,这两种硬件面对计算任务中可向量化部分均比较高效。比如
A[i] = B[i] + C[i],GPU上可以用N个thread来分别计算[1: N]个加法操作,在DSP上则依赖SIMD指令完成。但如果计算存在依赖,比如A[i+1] = A[i] + B[i] + C[i],这两种硬件则无能为力了。而对于CGRA,其可以在时间上进行流水并行,并行能力可以得到一定保障。
粗粒度兼具灵活性与频率功耗性能
和CGRA相对的是FPGA,是一种细粒度可重构硬件。其基本单元是比特级的查找表,配置比特流庞大,布线资源消耗多,导致频率低、功耗高(特别是静态功耗)。而CGRA的基本单元是字级的处理单元(如整个ALU、乘法器)。这种粗粒度特性使得其配置信息更精简,互连网络更高效,从而能够实现更高的运行频率和更低的功耗。
时空两个维度可配置,更强的资源利用率
这是CGRA独有的强大特性。
- 空间映射:将操作映射到不同的PE上,实现空间并行。
- 时间复用:同一个PE可以在不同周期执行不同的操作。这允许一个小规模的PE阵列通过时分复用来执行一个大规模的数据流图,极大地提高了硬件资源的利用率,用更少的芯片面积实现更复杂的计算。
理想很丰满,现实很骨干
But,如此强大的CGRA架构,目前却并没有什么基于CGRA的商用芯片出现(可能的例子:SambaNova的DPU,AMD的AIE,但均偏向学术试验品,或是在支持不断变化的大模型架构,周期过长,参见SambaNova支持deepseek R1的过程,极其耗时)。本质上,是其时间-空间配置性,将原本众多硬件设计的复杂性,转移到了编译器。编译器需要分析任务的依赖关系,需要做阵列布局,需要针对每个pe做时间序列分析并schedule,so harsh for compiler。
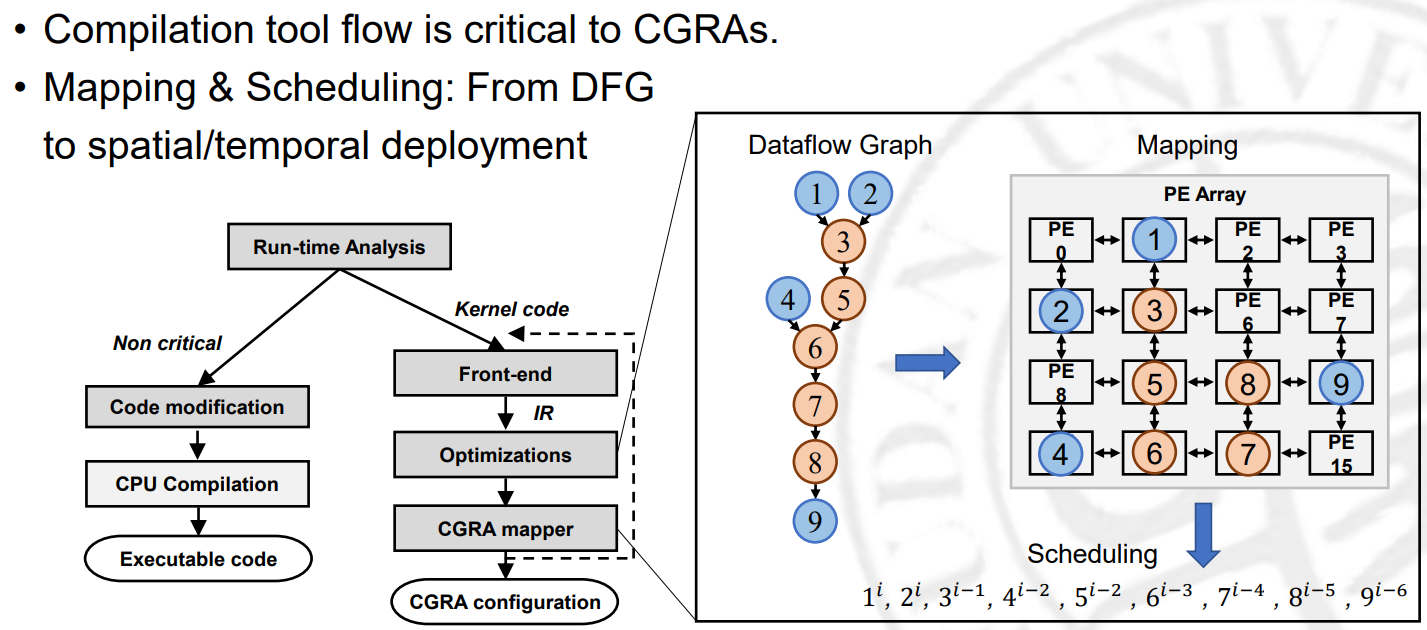
CGRA目前的困境
数据流图映射十分困难
数据流图映射困难可以分为如下几点:
- 需要同时考虑最大资源利用和最小启动时间
- 操作占用时间不一样,复杂控制逻辑增加分析难度
- 路由路线的约束多
以上几点导致利用DSE搜索收敛缓慢。
复杂的控制流无法支持
Memory Ordering开销大
内存操作顺序的正确性对于CGRA一直是一个关键挑战。传统CGRA及数据流架构通常依赖于严格的内存顺序保障策略,例如完全内存顺序或线程内顺序,以确保程序执行的正确性。然而,这种保守的策略往往带来显著的性能开销,限制了计算效率的进一步提升。尽管已有研究尝试通过硬件解耦等技术支持小规模无环数据流图(DFG)上的顺序优化,但对任意拓扑结构——尤其是普遍存在的带环数据流——仍缺乏有效的编译期顺序优化手段。
Paper Reading List
有了引言的铺垫,对于CGRA架构特点,优势以及困境都有了基本了解。更深入理解这一架构技术需要调研paper。本博客暂定解读如下论文:
- RipTide:这篇paper主要针对低功耗端侧需求,既做了CGRA微架构层面设计工作和CGRA编译器工作。以这篇工作入手,递归学习,可以理解CGRA架构层面和编译层面分别需要考虑的问题和可能解决手段,是HW&SW codesign很好的例子。
- Sambanova:目前商业化的基于CGRA的LLM加速器。
- StreamTensor:这严格意义上不属于CGRA工作,是面向数据流架构的编译优化工作。但CGRA和数据流架构有诸多相通之处,对于后续编译研究也值得借鉴。