
Triton Deep Dive
In this doc, we will dive into triton internals, to show how our hand-written triton-lang is lowered into ptx/cubin and finally launched by cuda driver. This doc is organized into following parts:
- Overall framework
- Source code structure
- Dive into jit compilation (Python)
- Pybind gluer
- MLIR Lowering passes (C++)
Chapter1: Overall Framework
The Triton codes nowadays is actually quite different from the original paper. There are two major differences:
- Python DSL is introduced to make it easier for model developers. Pythonic is the trend nowadays in ML compiler world :key:.
- Passes are all rewritten in MLIR, making it more extendible.
So we can clearly see two different parts in this shift, a python wrapper for user end, and the actual code optimization and conversion realized in C++ with MLIR ecosystem, glued by pybind mechanism.
With this bluescript in mind, we now try to touch three important questions:
- What is the input?
- What are temporaries and final codes during Triton compilation?
- How are those compiled codes loaded by device driver?
Let’s explain these questions one by one.
:question: What is the input?
Input of triton source code merely contains three parts: (1) triton kernel (2) kernel wrapper that can easily replace counterpart operator in certain ml models (3) data preparation and kernel launch. Below is a basic code sample:
1 |
|
:question: What are the temporaries and the final codes?
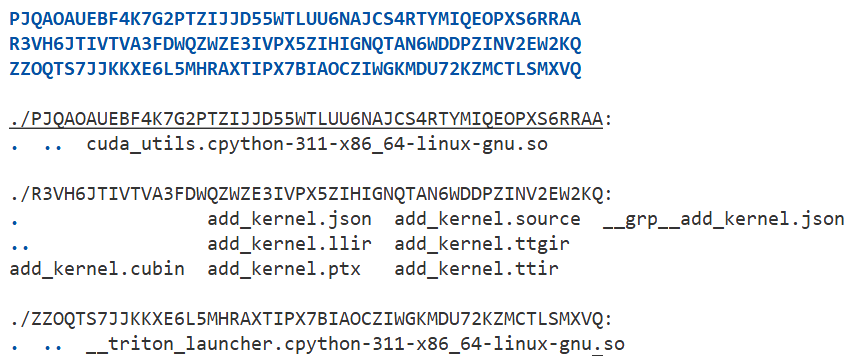
All temporaries are saved on disk, user can set TRITON_CACHE_DIR, or by default the dir path is ~/.triton/cache. Following figure shows files in the triton cache:
Here is a simple descriptions for those files:cuda_utils.socontains cuda helper functions for correct cuda launching.triton_launcher.sohelps launch cuda kernels..sourceis user-written triton dsl,.ttiris a one-to-one mapping ir,ttgiris gpu aware ir,lliris llvm ir converted fromttgir. Final result is.ptx, a cuda assembly..jsoncontains all the metadata of this kernel, which can help jit compile and launch(hash this compiled kernel for future use).
:question: How are ptx kernel launched by device driver?
Secrete lies in.sofile. This file contains wrapper forcuKernelLaunchfunction、grid configurations and parameters, which enable python to dynamically load this .so with importlib, and finally launch ptx/cubin kernels with control of device driver.
With these answers in mind, we can get a clearer roadmap of triton compiler. Then let’s touch source code to make it more solid. First let’s have a overall understanding of the codebase structure.
Chapter2: Source code structure
Triton Compiler project contains following directories:
/python/triton/tools/compile.py– The top-level compiler tool./python/triton/runtime/jit.py– The runtime utility, which includes kernel compilation cache, source data management, driver interaction, and kernel scheduling. :key:/python/triton/compiler/code_generator.py– Mainly handles the AST generated by the DSL, translating it into MLIR IR (i.e., Triton IR)./third_party/nvidia/backend/compiler.py– The compilation pipeline for specific hardware vendors, such as NVIDIA’s CUDA flow. Typically involves the transformation of TritonGPU IR and code generation for PTX and beyond. :key:triton/python/src/passes.cc– Glue layer(pybind) that organizes the various passes. :key:*/lib- cpp codebase, contains mlir source code for ir optimization, analysis and conversion. :key:*/include- header file for lib. :key:
Let’s first dive into python layer, to grasp how JIT compilation works in triton.
Chapter3: JIT compile
This part, we focus on python/triton/runtime/ repository, mainly jit.py , compile.py and build.py. First let’s see a flowgraph to have a general understanding of triton jit compilation: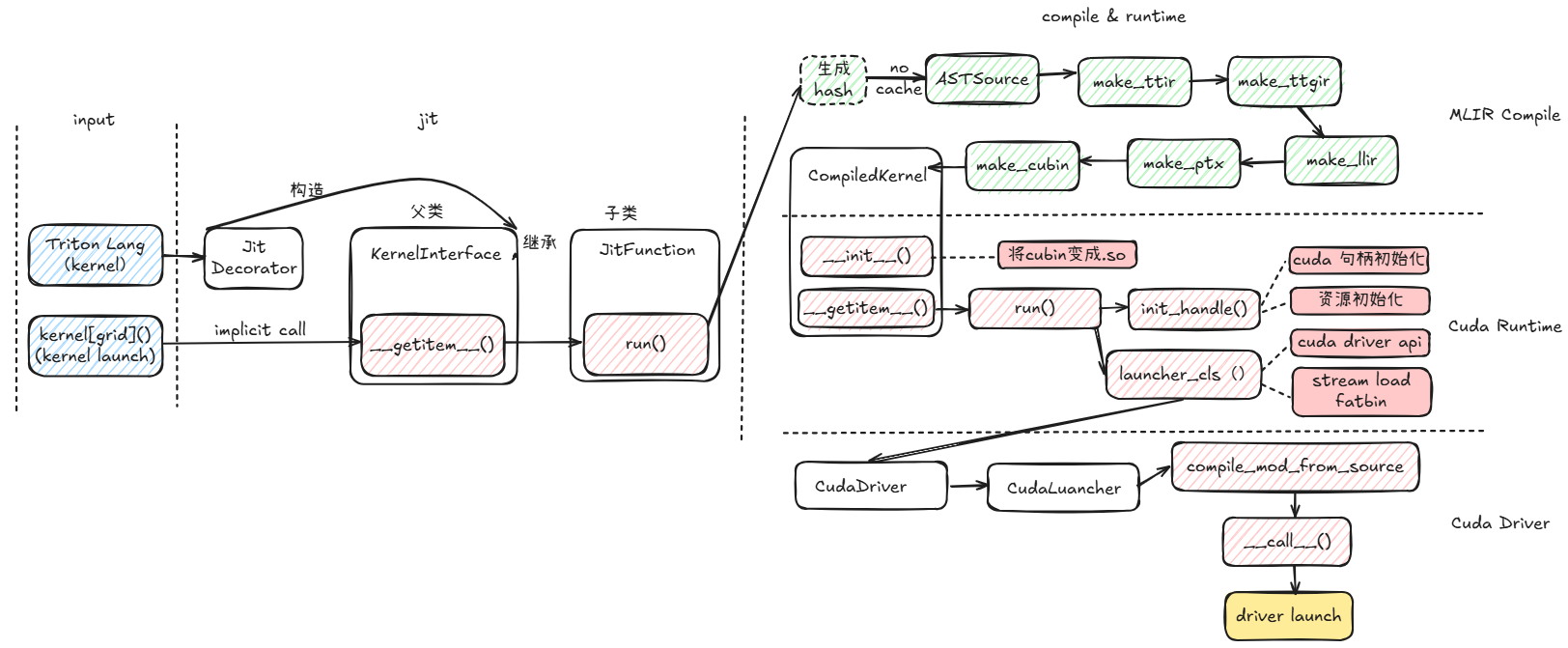
We can divide the whole jit compile workflow into three parts, and readers can refer to source code each part for further understanding:
- Jit Interface: this part mainly deal with user-written triton-lang kernel and kernel launch. Jit main function is here, and there are two main classes that we should pay attention with, JitFunction and its parent class KernelInterface. In KernelInterface, we should focus on
__getitem__()function, which is the entry ofkernel[grid](). And in JitFunction,run()function is quite essential. - Compilation: this part works when our kernel is firstly compiled, no previous cached kernel matched. This part is mainly written in mlir c++, turn to
make_ttir(),make_ttgir(),make_llir(),make_ptx()andmake_cubin()for further dive. This pipeline is the keypoint in next chapter.This pipeline is vendor specific. For Nvidia GPU, refer to cuda backend compiler.
- Runtime & Driver: this part first turn compiled cubin into
.solib, refer here. Then useinit_handle()to init a cuda stream and all metadata. Finally uselauncher_clsto evoke aCudaLuancherclass and finally launch a cuda kernel.
Hoping by following the flow graph and descriptions of each key part of JIT compilation, readers can get a clear picture of the whole python codebase and jit flow. Then comes the most exciting part to MLIR compilers, the actual code transformation and optimizations, proposing many interesting and advanced gpu compilation techniques such as: triton layout, coalesce opt, tensor core opt, etc.
Chapter4: MLIR Lowering Passes
This part, we enter the core optimization pipeline of Triton. The whole lowering pipeline is: triton-lang -> ttir -> ttgir -> llir -> ptx -> cubin. Refer to triton pipeline for detailed code transformation of a basic vector add triton-lang operator.
TTIR
1 |
|
In this doc, we only focus on Triton-specific optimizations, that are RewriteTensorPointer, Combine and ReorderBroadcast three passes. This part highly refer to OpenAI Triton 源码走读[transforms in ttir].
RewriteTensorPointer
The figure below shows all details on how this pass do to tl.make_block_ptr and tl.advance operations.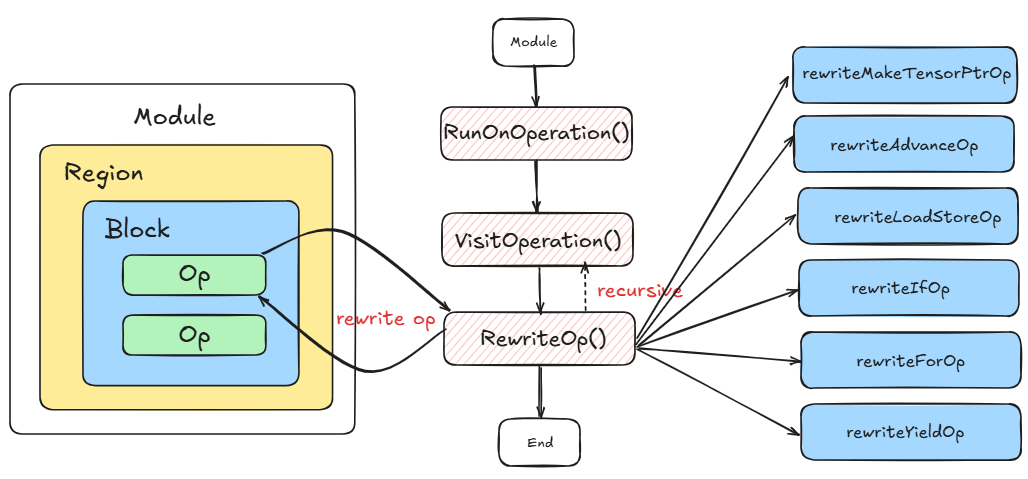
Refer to Before-pass-example and After-pass-example to see detailed effects of this pass.
A tip to help debug pattern rewrite in mlir: use
-debug-only=greedy-rewriter. Refer to Pattern Rewrite for further details.
Combine
The table below shows all combination rules that triton applied:
| Pattern Name | Match Rule | Rewrite Result | Optimization Purpose |
|---|---|---|---|
| CombineDotAddIPattern | AddIOp(d, DotOp(a, b, c=0)) |
DotOp(a, b, d) |
Merge dot with zero-init + add to eliminate redundant add. |
| CombineDotAddFPattern | AddFOp(d, DotOp(a, b, c=0, maxNumImpreciseAcc=0)) |
DotOp(a, b, d) |
Same as above, but for floating-point add, restricted to maxNumImpreciseAcc == 0. |
| CombineDotAddIRevPattern | AddIOp(DotOp(a, b, c=0), d) |
DotOp(a, b, d) |
Same as CombineDotAddIPattern, but with dot on the left-hand side. |
| CombineDotAddFRevPattern | AddFOp(DotOp(a, b, c=0, maxNumImpreciseAcc=0), d) |
DotOp(a, b, d) |
Same as CombineDotAddFPattern, but with dot on the left-hand side. |
| CombineAddPtrPattern | addptr(addptr(ptr, idx0), idx1) |
addptr(ptr, AddIOp(idx0, idx1)) |
Merge multi-level pointer offsets to avoid nested addptr; preserve optional attributes (div/cont/const). |
| CombineSelectMaskedLoadPattern | select(cond, load(ptrs, splat(cond), ?), other) |
load(ptrs, splat(cond), other) |
Merge select-wrapped masked load into a more concise load. |
| CombineBroadcastMulReducePattern | reduce(sum, broadcast(x[:, :, None]) * broadcast(y[None, :, :])) |
dot(x, y) |
Recognize matrix multiplication pattern (broadcast-mul-reduce) and replace with efficient dot. |
| CombineReshapeReducePatterns | reshape(tensor) (1D, allowReorder=false, user is reduce/histogram) |
set allowReorder=true |
Enable element reordering for 1D tensor reshape in reduction/histogram cases, improving optimization. |
| RankedReduceDescriptorLoads | reshape(descriptor_load(...)) with rank-reducing reshape |
absorb reshape into descriptor_load and modify result type |
Eliminate meaningless reshape by folding it into descriptor_load. |
ReorderBroadcast
The table below lists all broadcast + elementwise reorder rules that triton applied:
| Pattern Name | Original Form | Reordered Form | Conditions | Purpose |
|---|---|---|---|---|
| MoveSplatAfterElementwisePattern | elementwise(splat(a), splat(b), ...) |
splat(elementwise(a, b, ...)) |
- All operands are SplatOp or constant splats.- Operation is elementwise and has no side effects. |
Compute on scalars first, then splat once → avoids redundant tensor elementwise ops. |
| MoveBroadcastAfterElementwisePattern | elementwise(broadcast(a), splat(b), ...) |
broadcast(elementwise(a, b, ...)) |
- At most one broadcast operand. - All broadcasts must expand to the same shape. - Operation is elementwise and has no side effects. |
Compute on the smaller source tensor, then broadcast once → reduces duplicated computation. |
| Canonicalization (built-in) | e.g., broadcast(broadcast(a)), expand_dims(expand_dims(a)) |
Simplified canonical form | Provided by BroadcastOp and ExpandDimsOp. |
Normalizes IR to expose more rewrite opportunities and remove redundant ops. |
These three passes are all hardware-agnostic optimizations, to make further analysis and transformation more efficient.
TTIR -> TTGIR
This part highly refer to OpenAI Triton 源码走读[ttir-2-ttgir], Triton Linear Layout: Concept and Triton Axis Analysis. Let’s first see what this pass make changes to IR.
1 | IR before conversion |
The main difference is:
1 |
|
In conclusion, the main difference after ttir->ttgir conversion is the layout attribute attached to IR tensors, which defines how the data is parallelized and processed by threads. This layout attribute is propagated during the lowering process. In this doc, we are more interested in how TTIR is converted to TTGIR, and how Layout attrs are attatched and transformed. Readers should refer to TritonGPUAttr and Triton Layout docfor prior knowledge on triton layout.
TTGIR
Readers can refer to make_ttgir to view pass pipelines in TTGIR dialect.
In this part, triton do all critical GPU-specific optimizations, with the help fo Axis analysis. Let’s first dive into the design of Axis analysis, combined with previous layout information, which clearly shows how tensors are stored and distribute within threads.
Axis Analysis
Axis Analysis is like other standard analysis pass, gather detailed information to help guide further code transformation. This part highly refer to OpenAI Triton: Dive into Axis and Coalesce blog. To fully understand the detailed implementation behind, we need to understand an important concept: Dataflow Analysis and how it is implemented in Triton with the help of mlir infrastructure.
Below is a Flow graph shows the whole dataflow framework:
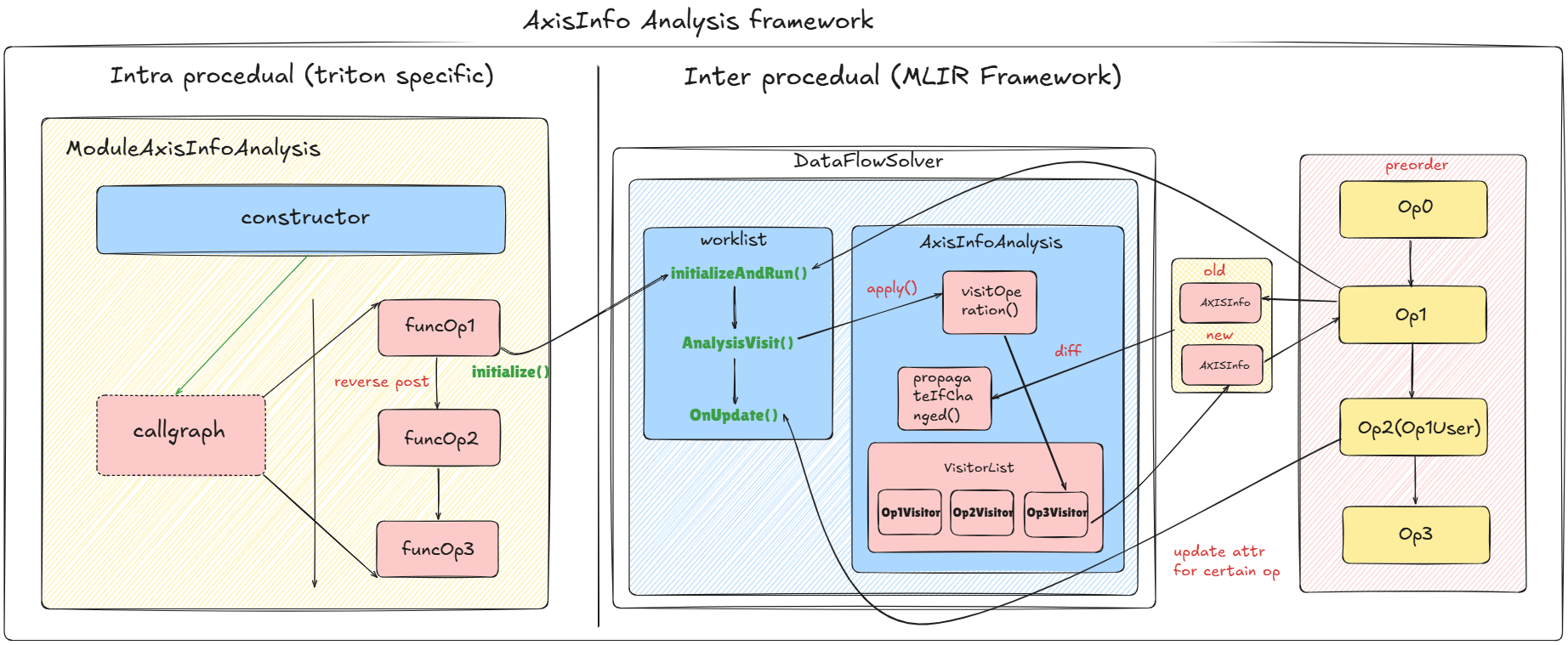
Refer to ModuleAxisInfoAnalysis for detailed implementation of intraprocedual info propagation, pay attention to its class construction and initialize(). Refer to AxisInfoAnalysis for AxisInfoAnalysis, where visitOperation() is essential. Also refer to AxisInfo.h for AxisInfo to see lattice define in dataflow analysis. To have a glance of Dataflow framework in MLIR, refer to Dataflow In MLIR and The Misssing Guide of Dataflow Analysis in MLIR.
After clarifying the whole AxisInfo analysis process, let’s focus on a certain op (pick triton::AddPtrOp here) to show how a certain op’s AxisInfo is updated. Below is the source code:
1 | template <typename OpTy> |
AxisInfo mainly consists of three new concepts:
- Divisibility
- Contiguity
- Constancy
Below are comments in source codes, which are clear to follow.
1 | Divisibility |
Coalesce Pass
After having a general galance of AxisInfo analysis, we first try to understand Coalesce Optimization, which enables consecutive memory access in triton.load or triton.store process. Refer to OpenAI Triton: Memory coalesce doc for further understanding.
Transpose case-study :key:
First let’s see a transpose test case to see how coalesce helps optimize:
1 | #blocked0 = |
To write a correct transpose triton-lang is quite easy, the key part lies in pointer calculation. That is, A[i, j] goes to A-prime[j][i], where the math should be converted from base_ptr + row_index * row_stride + col_index to base_ptr_out + col_index * output_row_stride + row_index.
The main tricks are layout config and layout . Let’s first analyze the origin layouts and potential optimizations that coalesce pass can make, see below:
#blocked1 = #ttg.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1]}>means
each thread only process one item, each warp has 32 threads and distributed among rows. That is a thread is responsible for a row, this layout is quite bad fortt.load.
So there are two potential optimizations: (1) each thread process continguous 4 items, that is 4 x 32 = 128bits, which fits a
vector operation length. (2) change layout fortt.loadto row manner, that is distribute threads in warp in a row / few rows.
Here is the optimized code:
1 |
|
Then let’s dive into how triton makes coalesce pass come true:
Coalesce Implementation
What coalesce does is quite simple, it only focus on following five operations that are global memory-related:
1 | Value getMemAccessPtr(Operation *op) { // coalesce优化只处理load/store/atomic/copy等涉及指针的操作 |
What it does to these five operations are:
- Create a coalesced memory layout L2 of the pointer operands (determined by Axisinfo analysis:key:)
- Convert all operands from layout L1 to layout L2 (
ttg.convert_layoutinserted:key:) - Create a new memory op that consumes these operands and produces a tensor with layout L2
- Convert the output of this new memory op back to L1
- Replace all the uses of the original memory op by the new one
From the five steps above, most important parts are:
- Layout Determination by AxisInfo Analysis
- Insertion of Layout conversion operation
First let’s have a view on Layout determination. Below is the AxisInfo dumped:
1 | [tritongpu-coalesce]: Considering op: %20 = tt.load %11, %cst, %cst_0 : tensor<64x64x!tt.ptr<f32>, |
Two key functions, one for order determination and another for elements/thread determination:
1 | SmallVector<unsigned, 4> |
Chapter5: Python Binding Layer
refer to python/src/passes.cpp and python/src/passes.h
References
- Triton Internal Talk
- Triton Fusing Talk
- A Practioner’s Guide to Triton
- Deep Dive into Triton 1&2&3
- Official Hacking for Triton
- Triton Developer Guide
- Triton Linear Layout: Concept
- OpenAI Triton: Why layout is important
- OpenAI Triton 源码走读[transforms in ttir]
- OpenAI Triton 源码走读[ttir-2-ttgir]
- Triton Axis Analysis