
通过阅读Effective C++一书,对C++知识进行查漏补缺。
C++是什么?
- 以C为基础,包含内置数据类型,数组,指针,预处理器
- Object-Oriented C++
- Template C++
- STL库
条款2: 尽量以const,enum,inline替换#define
对于单纯常量,最好以const对象或enums替换#defines
why?
首先define会在预处理阶段替换,因此记号不会进入符号表
- debug带来不方便,用户可能会看到一串数字,但是不知道追踪到哪
- 代码存储空间变大,盲目将名称替换为数字可能导致目标码变大
需要注意的点
定义常量指针
class专属常量,这个点有两个要求:1
- 常量受到class作用域的限制 -> 是成员
- 一个class的常量最多只有一个实体 -> 是static 成员
.h文件1
2
3
4
5class GamePlayer {
private:
static const int NumTurns = 5;
int scores[NumTurns];
};.cpp文件1
const int GamePlayer::NumTurns;
注意:如果编译器不允许在编译时对static赋值,可以用
enum hack的做法。1
2
3
4
5
6class GamePlayer {
private:
enum { NumTurns = 5 };
int scores[NumTurns];
};根据书中解释,enum hack的好处是阻止用户获得某个整数常量的地址或引用。
对于形似函数的宏,最好改用inline函数替换#defines
#define 可能导致行为不可预料:
1
比如如下测试case:
1
2
3int a = 5, b = 0;
CALL_WITH_MAX(++a, b);
CALL_WITH_MAX(++a, b+10);这里面a++几次,完全取决于a和b的大小,这是十分讨厌的。
解决方案是:template inline函数,可以同时兼顾宏函数的性能(节省function call)+可预料行为+类型安全。
1
2
3
4template <typename T>
inline void callWithMax(const T& a, const T& b) {
f(a > b ? a : b);
}什么样的宏仍旧被需要?
- #include
- #ifdef/#ifndef
条款3:尽可能使用const
Const的含义
首先,const修饰符比较容易混淆的是其具体修饰的是指针本身还是指针所指的对象。有如下口诀:如果关键字const出现在星号左边,表示被指物是常量,如果出现在星号右边,表示指针自身是常量。通过下面的例子来加深理解:
1 | char greeting[] = "Hello"; |
接下来我们将目光从指针引向迭代器。迭代器的作用就是T*指针,所以其const修饰也有讲究,具体如下:
1 | std::vector<int> vec; |
Const搭配函数
const的一个最具威的用法是在函数声明时使用。const可以和(1)函数返回值(2)各参数(3)函数自身(如果是成员函数)产生关联。
函数返回常量值
例子如下:
1 | class Rational { ... }; |
函数参数的const作用是防止修改传入的lhs,后续会讲解pass by reference to const,这种写法也是比较推荐替代pass by value的方案。
返回值const的作用,则是用来预防用户可能的使用错误。比如用户可能如下使用:
1 | if (a * b = c) // 应该是==但是写成=了 |
如果添加const修饰,则上述用法会直接报错。
const成员函数
书中总结const成员函数两大作用:
- 使得class接口比较容易被理解
- 使操作const对象成为可能
接下来我们通过一个例子解析const成员函数的相关用法:
1 |
|
这段代码的要点是,函数可以只有const属性不一样,也是一种重载。对于不同的对象,使用不同的重载函数,得到不同的处理。这里有一个要点,operator返回的是pass by reference to char,不是value。如果是pass by value,则其逻辑是改变一个副本。
Bit wise constness和Logical constness
对于constness的界定分为两个派别:
Bit wise constness:不更改对象内的任何一个bit
优点:编译器特别容易分析违反的点,只用追踪assign操作
缺点:对于一个指针是对象,如果修改其所指内容,破坏constness,但是却没有违背bit wise constness
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
using namespace std;
class TextBook {
public:
TextBook(const char* title) {
this->title = new char[strlen(title) + 1];
strcpy(this->title, title);
}
~TextBook() {
delete[] title;
}
void printTitle() const {
cout << "Title: " << title << endl;
}
char& operator[](size_t index) const {
return title[index];
}
char& operator[](size_t index) {
return title[index];
}
private:
char* title;
};
int main() {
TextBook book("C++ Programming");
book.printTitle();
cout << "First character: " << book[0] << endl;
book[0] = 'c'; // 修改第一个字符
cout << "Modified first character: " << book[0] << endl;
book.printTitle();
const TextBook ctb("World");
ctb.printTitle();
char* pc = &ctb[0];
*pc = 'w'; // 修改 const 对象的字符
cout << "First character of const TextBook: " << ctb[0] << endl;
// ctb[0] = 'w'; // 错误,不能修改 const
return 0;
}上述写法通过在const成员函数返回非常量引用,打破了const约束,要杜绝这种写法。
logical constness
其思想很简单,用户觉得什么是可变的,什么就是可变的,什么该是const,就是const。通过mutable关键字来决定哪些成员变量可以被更改。
Const和non-const成员函数冗余问题
如果对于const和non-const,有大量重复逻辑,那么会带来巨大的冗余开销。一种设计办法是做常量转移(转移方向是将const转移成无const语义,反过来是不安全的)。具体代码示例如下:
1 | class TextBook { |
上述代码有两处转型:
- static_cast是将this变成const语义,因为non-const要调用const的成员函数,给先转型,否则会触发递归调用。
- 获得const返回值,需要cast away const语义,用const_cast
方向问题:如果是const调用non-const,就有问题,因为const承诺不改变成员变量,导致语义冲突。
条款4:确定对象被使用前已先被初始化
C++语言在初始化方面是比较trickey的。比如array(属于C part of C++部分语法)不保证被初始化,而vector(来自STL part of C++)则保证初始化。是否保证初始化比较难以记忆,最佳方法就是无论何时都初始化。初始化有两条准则:
- 内置类型,手工完成
- 非内置,构造函数初始化
对于非内置,需要明晰两个概念:初始化和赋值。
初始化和赋值
以下面代码为例:
1 | ABEntry::ABEntry(const std::string& name, const std::string& address, |
这段代码比较有意思的点是,均是赋值而非初始化。因为C++有如下规定:**对象的成员变量的初始化动作发生在进入构造函数本体之前。**即,对象的初始化发生在default构造函数被调用之时,在ABEntry::ABEntry()构造函数调用之前。其底层逻辑是,现在default构造函数做一遍初始化,然后调用我们定义的构造函数再赋值一遍,造成显著浪费。正确解法是通过初始化列表来更新:
1 | ABEntry::ABEntry() : theName(), theAddress(), thePhones(), numTimesConsulted(0) { } |
什么情况下一定要初始化列表?
- 对于内置类型,如果是const或references,要用初始化列表。
- 非内置类型
总结一下,保持初始化习惯,能够规避很多潜在bug。
初始化顺序,依据class成员变量的声明次序来初始化。
不同编译单元内non-local static对象初始化顺序
这一句话比较绕口,我们逐个拆解一下:
- 编译单元:产出单一目标文件的源码,单一源文件 + 包含的头文件
- static对象:其寿命周期从构造持续到程序结束,即析构函数在main()结束后才调用
现在有这样一个场景:两个源文件各自有static对象,并且non-local。一个的构造依赖另一个,由于C++对于不同编译单元内non—local static对象初始化没有特定规则,因此可能被依赖的static 对象还没有构造成功,导致问题。
对于这个问题,解决方法是将每个non-local static对象搬到自己的专属函数内,类似与singleton模式的实现方法。
下面的例子很好的解释了原理:
1 | class FileSystem { ... }; |
该原理很简单,在函数中定义一个静态变量,然后返回该local static。使用时候,唯一区别是原本直接用non-local static:tfs,现在给用tfs()函数。
写到这里,我们岔开一个话题,讲解一下单例模式这个知识点。对于单例模式感兴趣的读者可以参考单例模式教程。
单例模式
首先我们先从最简单基本的单例模式开始,该模式又称经典懒加载:
1 |
|
这段代码有几个要点需要注意:
构造函数为
private,防止外部直接实例化对象:Singleton类的构造函数被声明为private,这样外部代码无法直接通过new或者其他方式创建Singleton的实例,确保Singleton类只能通过其提供的静态方法访问。这是单例模式的核心机制之一,确保类的实例只能通过规定的途径获得。静态成员变量声明与定义:
在
Singleton类内部声明了静态成员变量static Singleton* instance;,这告诉编译器instance变量是该类的一个静态成员。然而,仅声明并不会为它分配内存。静态成员变量的内存分配和初始化必须在类外进行定义:Singleton* Singleton::instance = nullptr;。这确保了该变量有实际的内存空间,且其初始值被设置为nullptr。通过
getInstance静态方法实现单例特性:getInstance是一个公共的静态方法,负责返回Singleton类的唯一实例。方法内部通过instance == nullptr来判断是否已经创建了实例。如果实例尚未创建,则调用new Singleton()创建该实例。此方式确保了在整个程序生命周期中Singleton类只有一个实例,从而保证了单例特性。
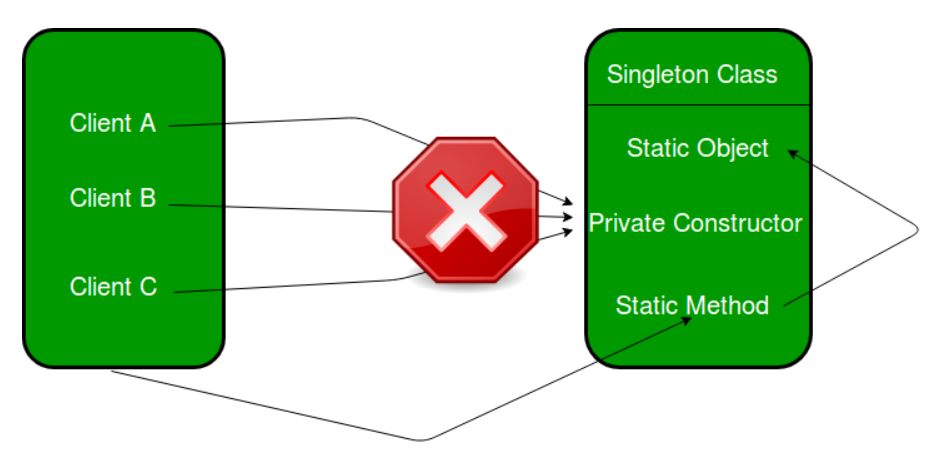
上图来源是单例模式教程,很好地阐述了单例模式的核心点。
讲解清楚单例的要点,我们罗列一些变种来学习:
线程安全版
1 |
|
饿汉式
1 |
|
条款5:确定对象被使用前已先初始化
这个条款是比较简单的一个条款,具体可以概括为一下几点:
编译器会为一个class自动声明一个copy构造函数,copy assignment操作符和一个析构函数。如果用户没有声明任何构造函数,则编译器自动声明一个default构造函数。所有这些函数是public + inline的。
什么时候编译器会拒绝生成拷贝赋值函数(operator=)?
如果类包含reference成员,编译器无法自动生成赋值操作
1
2
3
4
5
6
7
8template<typename T>
class NamedObject {
public:
NamedObject(std::string& name, const T& value);
private:
const T objectValue;
std::string& name;
};如果有如下使用:
1
2
3
4
5std::string name1("Leon Dou");
std::string name2("Dou Leon");
NameObject<int> p(name1, 1);
NameObject<int> q(name2, 2);
p = q;其主要违反了C++的一个核心准则:不允许让reference改指向不同对象。具体编译报错如下:

如果类包含const成员,编译器无法自动生成赋值操作
如果base class将赋值操作声明为private,编译器无法生成赋值操作
条款6:若不想使用编译器自动生成的函数,就应该明确拒绝
这个条款承接条款5,在一些case中,我们并不希望编译器为我们的类自动生成比如赋值或是拷贝构造函数。如下是一个典型case:
Case Study
中介卖房子,中介软件自然会用一个class描述待售房子信息。比如class HomeForSale { ... }。
对于中介而言,任何一个代售房子信息都是独一无二,因此拷贝构造或是赋值语句都是没有意义的:
1 | HomeForSale h1; |
对于普通的函数,不在public中声明定义即可。但是如条款5,拷贝构造函数和赋值函数编译器是会自动生成的。因此我们的首要任务是阻止两个函数自动创建。
Method
在C++11引入了delete关键字,很好地能够解决这个问题,如下操作即可:
1 | HomeForSale(const HomeForSale& h1) = delete; |
Effective C++在编写的时候C++还没有引入delete关键字,一下部分对于书中的方法也做简单介绍,该内容自行理解下即可。
private化 + 错误移至编译器
对于书中的方法,可以总结为私有化+错误移至编译阶段。初始方法很简单,将拷贝构造函数和赋值函数定位为private,这样外部无法访问。但是问题是member函数和friend函数还是可以调用的,只有到链接阶段才会报错未定义。
示例代码如下:
1 |
|
报错如下:

这个报错,我希望能够从编译期的错误移至链接期错误。书中通过专门设计一个阻止copying动作设计的base class,来达到这一目的。
1 | class Uncopyable { |
对于我们的HomeForSale类,单纯地继承Uncopyable类即可达到目的。具体原因分析如下:
通过member函数或是friend函数尝试拷贝HomeForSale类,编译器都会自动生成一个拷贝构造和拷贝赋值。由于有base class的存在,这两个函数会尝试调用base class的对应两个函数,两个函数是private,编译器会明确拒绝。
完整的示例代码如下:
1 |
|
条款7:为多态基类声明vritual析构函数
这个条款从标题看就比较清晰,理解清楚主要需要解决两个疑问:
- 为什么适用范围是多态基类?
- vritual析构函数的作用?
为什么要virtual析构?
还是以一个代码例子讲解:
1 |
|
上述代码是一个典型的工厂函数方法,由于返回的是指针,所以需要用户手动delete(手动delete这件事需要极力避免,但此场景没有办法)。这段代码有个核心问题,由于base class(TimeKeeper)的析构不是vritual的,所以delete tk1/tk2的时候只会调用base class的析构,而不会对derived 部分析构,造成资源浪费。
解决办法很简单,给~TimeKeeper()添加上vritual关键字。原理如下:对于最深层派生的那个class,其析构函数最先调用,然后是其每一个base class的析构函数。
至此,我们理清了为什么要析构函数的问题。
适用场景
前一小节的例子就是多态基类,很好理解。这里理解为什么其他场景不适合。
class不含vritual,表明非base
1
2
3
4
5
6
7class Point {
public:
Point(int xCoord, int yCoord);
~Point();
private:
int x, y;
};上述Point类,一个int占32bits情况下正好可以放在一个64bits的缓冲中。如果存在虚函数,则该class需要存储一个vptr指向vtbl(虚函数表),一个指针至少32bits,造成不必要的内存占用。
STL的类,凡是没有虚析构函数,都不能做基类
纯虚函数
一个class带有pure virtual析构函数,会导致该类不能被实例化,可能有便利性。具体解法如下:
1 | class AWOV{ |
这里有个易错点,就是纯虚析构函数,在类内声明,但是类外仍旧需要自行定义,否则链接报错。参考前文提到的原理:
对于最深层派生的那个class,其析构函数最先调用,然后是其每一个base class的析构函数。言外之意,派生class的析构函数会调用base class的析构,所以如果base class的析构纯虚,也要有定义
1 |
|
报错:

条款8:别让异常逃离析构函数
这个条款比较简单,所以直接简单罗列一下即可:
- 析构函数绝对不要吐出异常。如果一个被析构函数调用的函数可能吐出异常,析构函数应该捕捉任何异常。
条款9:绝不在构造和析构过程中调用virtual函数
此条款比较简单,在此略过
条款10:令operator=返回一个reference to *this
这个条款也比较简单,有几个要点要提一下:
我们期望的
+=,=等运算,都要能够形成连锁,即1
2int x, y, z;
x = y = z = 18;在类的设计中,对于operator=这类的运算重载,返回reference即可,以下是代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
using namespace std;
class Complex {
public:
Complex(double r = 0.0, double i = 0.0) : real(r), imag(i) {}
Complex operator+(const Complex& other) const {
return Complex(real + other.real, imag + other.imag);
}
Complex operator-(const Complex& other) const {
return Complex(real - other.real, imag - other.imag);
}
Complex& operator+=(const Complex& other) {
real += other.real;
imag += other.imag;
return *this;
}
Complex& operator-=(const Complex& other) {
real -= other.real;
imag -= other.imag;
return *this;
}
void display() const {
cout << real << " + " << imag << "i" << endl;
}
private:
double real;
double imag;
};
int main() {
Complex c1(3.0, 4.0);
Complex c2(1.0, 2.0);
Complex c3 = c1 + c2;
c3.display(); // 输出: 4.0 + 6.0i
Complex c4 = c1 - c2;
c4.display(); // 输出: 2.0 + 2.0i
c1 += c2 += c2 += c2; // 等同于 c1 = c1 + c2
c1.display(); // 输出: 4.0 + 6.0i
c1 -= c2; // 等同于 c1 = c1 - c2
c1.display(); // 输出: 3.0 + 4.0i
return 0;
}
条款11:在operator=中处理自我赋值
这个条款是针对用户潜在的误操作:自我赋值而做的针对性保护条款。最常见的自我复制场景是别名情况下的误操作,比如如下代码:
1 | for (int i = 0; i < N; i++) { |
这种操作可能的潜在危险是,可能会出现释放资源后自我赋值,从而使得指针指向已释放资源,伪代码如下:
1 | class Bitmap { ... }; |
针对上述场景,最简单的解决方法就是做一个等同判断:
1 | Widget& |
但仔细分析,发现还是会引发问题。如果pb = new Bitmap(*rhs.pb)因为heap空间不够而抛出异常,则原本this的指向空间已经释放,新的又没有成功开辟,则仍旧存在安全问题。针对这个问题,有一个发现:通过调整代码顺序,可以有效解决异常安全问题,同时也一并解决了自我赋值安全。伪代码如下:
1 | Widget& |
上述代码能够保障自我赋值安全,但是不够简洁,一种替代方案是使用copy swap技术,这里简要提一下:
1 | Widget& |
条款12:复制对象时勿忘其每一个成分
这个条款总体是比较简单的,其背后深层原理是用户自行定义copy 函数(构造函数或是赋值),编译器就不会对遗赋值做出警告了。因此整个条款可以总结成两条准则:
- Copying函数应该确保复制对象内的所有成员变量以及所有base class成分。
- 不要尝试copying函数中实现另一个copying函数。应该提炼出
init函数。
条款13:以对象管理资源
从条款13开始讨论资源管理的技术细节,这部分是比较重要的。这一章节主要围绕一个关键技术:RAII(Resource Acquisition is Initialization)展开。首先先明晰不使用RAII技术可能的问题。
如下是一个资源管理示例:
1 | class Investment{ ... }; |
主要有如下问题:
- 本身工厂方法返回指针,容易导致开发过程中遗漏delete操作
- delete之前可能有异常,或是提前return,造成资源泄露。
解决方法也很简单:将资源放入对象内,资源释放通过析构函数自动释放。这就是大名鼎鼎的RAII结束。接下来通过两个演示例子来展示C++对RAII机制的支持:
auto_ptr智能指针,自动对所指对象调用delete。其特点是,调用copy构造函数或是copy assignment操作符复制,会变成null,转移控制权。即只有唯一的控制权,同时注意,
auto_ptr已经被替换成unique_ptr了。shared_ptr引入引用计数,多个对象可以共享资源。只有所有对象都删除了,才最终释放资源。相比java等语言的垃圾回收机制,
shared_ptr无法解决循环引用的问题。