这是本系列的第二篇文章,主要结合印度理工学院搭建的面向GPU tensor core代码生成的论文,以及IREE开源项目,解读如何基于MLIR系统完成GPU的代码生成。
IREE Tensor Core代码生成
IREE是一个端到端的开源机器学习编译器,支持在边缘设备进行高效部署。本章节主要讲解IREE项目是如何做面向Nvidia GPU的代码生成的。
IREE 后端代码生成管线概览
详解matmul算子生成
注:这一部分解读主要参考IREE Codegen博客。
结合前一章节的论文解读,我们重点关注IREE的matmul代码生成部分。在compiler/src/iree/compiler/Codegen/LLVMGPU/LLVMGPULowerExecutableTarget.cpp代码中,有如下代码生成dispatch实现:
1 | // 根据translation info,选择对应的executable生成的dispatch lowering pipeline |
可以看到,结合不同的translation info,IREE针对每个可执行变种(IREE中叫execute.variant)派发不同的代码生成逻辑。这里我们重点关注LLVMGPUMatmulTensorCore,该管线是面向Nvidia gpu的tensor core硬件的适配编译流水线。
测试输入
1 | #compilation0 = #iree_codegen.compilation_info< |
这个测试例子是一个简单的矩阵乘运算,维度是<512x128xf16> x <128x512xf16> = <512x512xf16>。这段测试核心点事compiler配置attribute:
1 | #compilation0 = #iree_codegen.compilation_info< |
其中,定义了如下元数据:
- workgroup(即threadBlock)维度是[64, 2, 1]。
- tile分块的维度是[32, 32, 16]。
- 流水线深度为3,注意3是GPU最小流水线深度(存,取,执行)。
- storage_stage是1,这个具体含义尚不明晰。
针对这个测试,我们的测试脚本如下:
1 | iree-compile --iree-hal-target-backends=cuda \ |
Tensor Core verifier
现在我们有了输入和测试脚本,IREE在根据我们的代码和配置做tensor core转换之前,会先检查一下参数是否适配。具体地参考compiler/src/iree/compiler/Codegen/LLVMGPU/Verifiers.cpp中关于compilation_info和work_group等参数的约束判断逻辑。这里通过几张表格的方式简单解释下各个参数背后的具体意义和相应约束:
核心概念
| 概念 | 代码对应变量/参数 | 含义与作用 | 约束来源 |
|---|---|---|---|
| Workgroup Size | workgroup_size |
线程块(Thread Block)的维度配置(如[64,2,1]),总线程数 ≤ 1024 |
CUDA硬件限制 |
| Tile Size | tile_sizes |
矩阵分块尺寸(如[32,32,16]),决定每个线程块处理的数据块大小 |
算法优化需求 |
| Thread Block Shape | threadBlockShape |
线程块内各维度的分块尺寸(如[32,32,16]),与Tile Size直接相关 |
分块策略与硬件匹配 |
| Warp数量 | numWarps |
线程块内各维度的Warp数量(如[2,2,1]),由Workgroup Size除以Warp Size(32)计算 |
SM硬件架构 |
| Warp Shape | warpShape |
单个Warp处理的分块子矩阵尺寸(如[16,16,16]) |
线程调度与指令级并行 |
| Instruction Shape | instructionShape |
Tensor Core硬件指令支持的矩阵尺寸(如FP16→16x16x16,FP32→16x16x8) |
Tensor Core架构规范 |
TensorCore约束检测逻辑
| 验证项 | 验证条件 | 失败后果 |
|---|---|---|
| Workgroup总线程数 | workgroupSize[X] * Y * Z ≤ 1024 |
超过GPU线程块容量限制,无法执行 |
| Z维度线程数 | workgroupSize[Z] == 1 |
Tensor Core设计为二维计算,Z维度扩展会破坏数据局部性 |
| X维度线程数 | workgroupSize[X] % 32 == 0 |
Warp调度需要X维度为32的整数倍(每个Warp含32线程) |
| 验证项 | 验证条件 | 失败后果 |
|---|---|---|
| 矩阵尺寸对齐 | matmulShape[M/N/K] % threadBlockShape[M/N/K] == 0 |
分块无法均匀覆盖原矩阵,导致计算错误或性能下降 |
| Warp分块对齐 | warpShape[M/N/K] % instructionShape[M/N/K] == 0 |
Tensor Core指令无法覆盖Warp分块,硬件资源利用率不足 |
这里有两个关键点:
- tensor core的最小执行单元是一个warp,因此需要验证Warp是否分块对齐。
- workgroup就是threadblock。tiesize表示一个threadblock完成的计算任务量,而workgroup则表示一个threadblock有多少个线程,并可以根据warpsize(默认32)计算一个workgroup可以有多少warps。这两个概念要分辨清楚
整个tensor core verifier的逻辑比较复杂,需要详细阅读下面代码的注释以获得全面的了理解:
1 | // Number of warps in x, y, and z dim. |
矩阵乘tensor core生成流程概览
讲解完Tensor Core管线的verifier流程后,我们逐渐接触tensor core生成的主体管线流程,代码如下所示:
1 | void addGPUMatmulTensorCorePassPipeline(OpPassManager &funcPassManager, |
上述管线中,我们比较关心如下7个pass的流程:
LLVMGPUTileAndDistributeGPUMultiBufferingPassLLVMGPUTensorCoreVectorizationPassGPUDistributeSharedMemoryCopyPassGPUReduceBankConflictsPassLLVMGPUVectorToGPUGPUPipeliningPassLLVMGPUPackSharedMemoryAlloc
我们接下来结合代码,一个一个pass的解读。
LLVMGPUTileAndDistribute Pass
LLVMGPUTileAndDistribute 这个 pass 主要是根据 lower_config 中的 tile_sizes 和 compilation info 中的 workgroup size 进行 tiling,并且在此过程中,使用了 shared memory 用作缓存进行访存的优化。
我们的workload可以表征为如下:C<512x512> = A<512x128> x B<128x512>
具体的,可以拆解为下面几步:
- 初步tile,将计算workload分块为<32x128> x <128x32>
- Promote Memory1:将C矩阵放入shared_memory
- 持续tile化,化为指定的<32x16> x <16x32>
- Promote Memory2:如果workgroup比warp大,那么需要将一部分的A和B也放入sharedmemory
- 根据warp size继续tile化。我们的thread block是[64,2,1],warp size是32,所以可以拆成[2,2,1]个warp。针对此,我们的矩阵<32x16> x <16x32>可以进一步变成<32/2 x 16> x <16 x 32/2>
接下来分别在debug过程中dump每个步骤生成的中间表示代码。
Step1 i,j维度分块
1 | func.func @matmul_accumulate_512x128xf16_times_128x512xf16_into_512x512xf16_for_LLVMGPUMatmulTensorCore_32_32_16_64_2_1_dispatch_0_matmul_512x512x128_f16() attributes {translation_info = #iree_codegen.translation_info<pipeline = LLVMGPUMatmulTensorCore workgroup_size = [64, 2, 1], {pipeline_depth = 3 : i64, store_stage = 1 : i64}>} { |
这段代码在 GPU 上实现了高效的 512×512 半精度矩阵乘法,并进行了如下优化:
- 使用 Tensor Core 加速计算(
tile_sizes = [[32, 32, 16]])。 - 分块计算(Tile-based Computation)
- 将矩阵 A、B、C 分割成 32×128、128×32、32×32 子矩阵。
- 使用
workgroup_id_x/y进行索引计算,每个workgroup处理固定区域。
- 存储优化
- 存储对齐(alignment 64):提高 GPU 访存性能。
- 使用 Subview 提取矩阵块,减少数据移动,提升数据局部性。
Step2(做promotion优化)
1 | //========================================== LLVM GPU Tile And Distibute ======================================== |
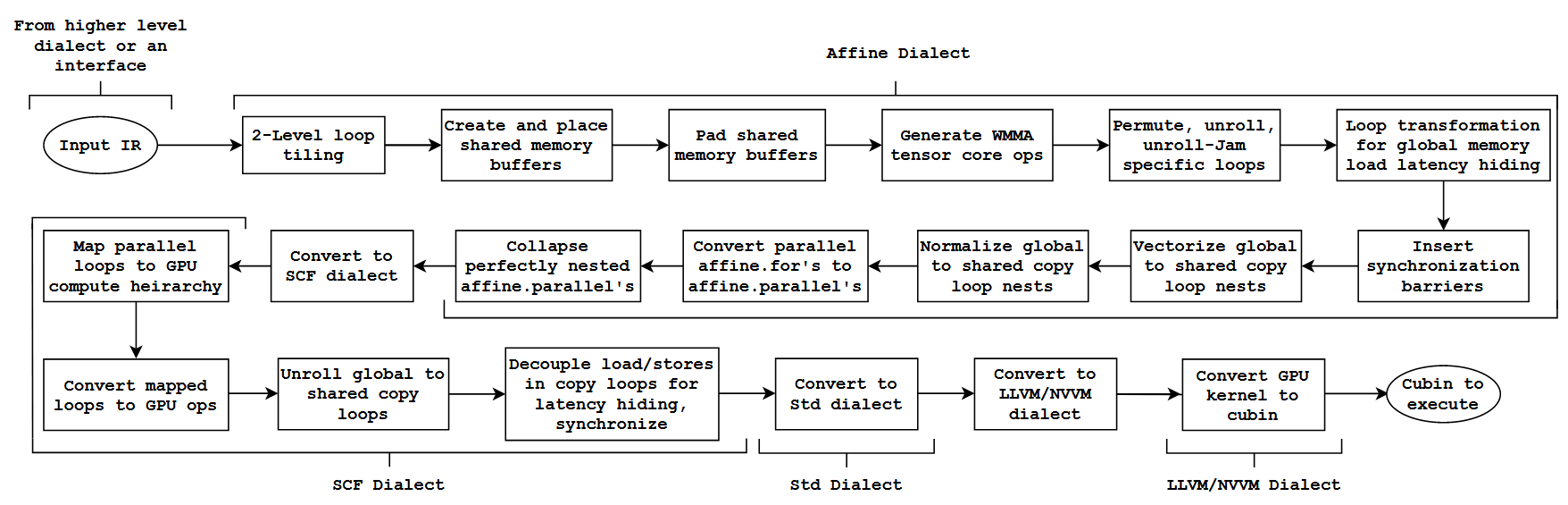
重点是:将C矩阵存储在workgroup memory中。

在上图的代码比对中,可以看到如下变化:
- 显示的
memref.alloc操作,并且address_space设置为workgroup。 - 由于shared memory而导致的memref.copy(从shared mem显示加载)和memref.subview操作。
为什么这一步仅仅提升C矩阵,而不提升A,B矩阵,具体原因参考MLIR GPU代码生成论文,这里截取一下论文的原文辅助理解:

Step3(继续tiling,将K从128降维成16)
1 | func.func @matmul_accumulate_512x128xf16_times_128x512xf16_into_512x512xf16_for_LLVMGPUMatmulTensorCore_32_32_16_64_2_1_dispatch_0_matmul_512x512x128_f16() attributes {translation_info = #iree_codegen.translation_info<pipeline = LLVMGPUMatmulTensorCore workgroup_size = [64, 2, 1], {pipeline_depth = 3 : i64, store_stage = 1 : i64}>} { |
继续完成k维度的tiling,从128变成16。
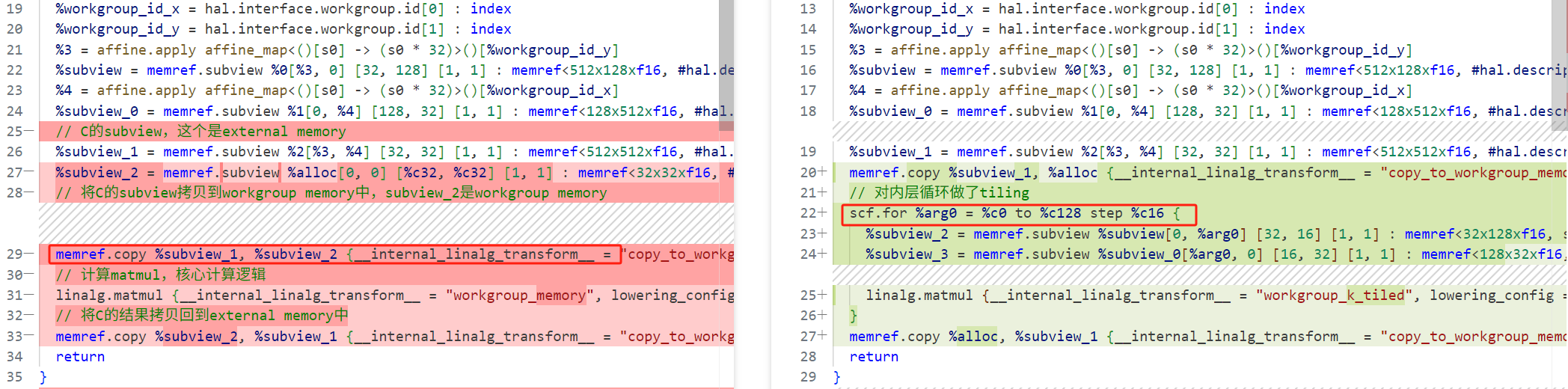
如上图所示,reduction维度变成显示的循环,以及删除冗余的memref.copy操作。
这个处理有趣的点是将linalg.matmul的workgroup_memory变成了workgroup_k_tiled,具体阅读源码中的tileReductionLoops函数:
1 | /// Tiles to workgroup level. Workgroup tiling is done at the flow level but we |
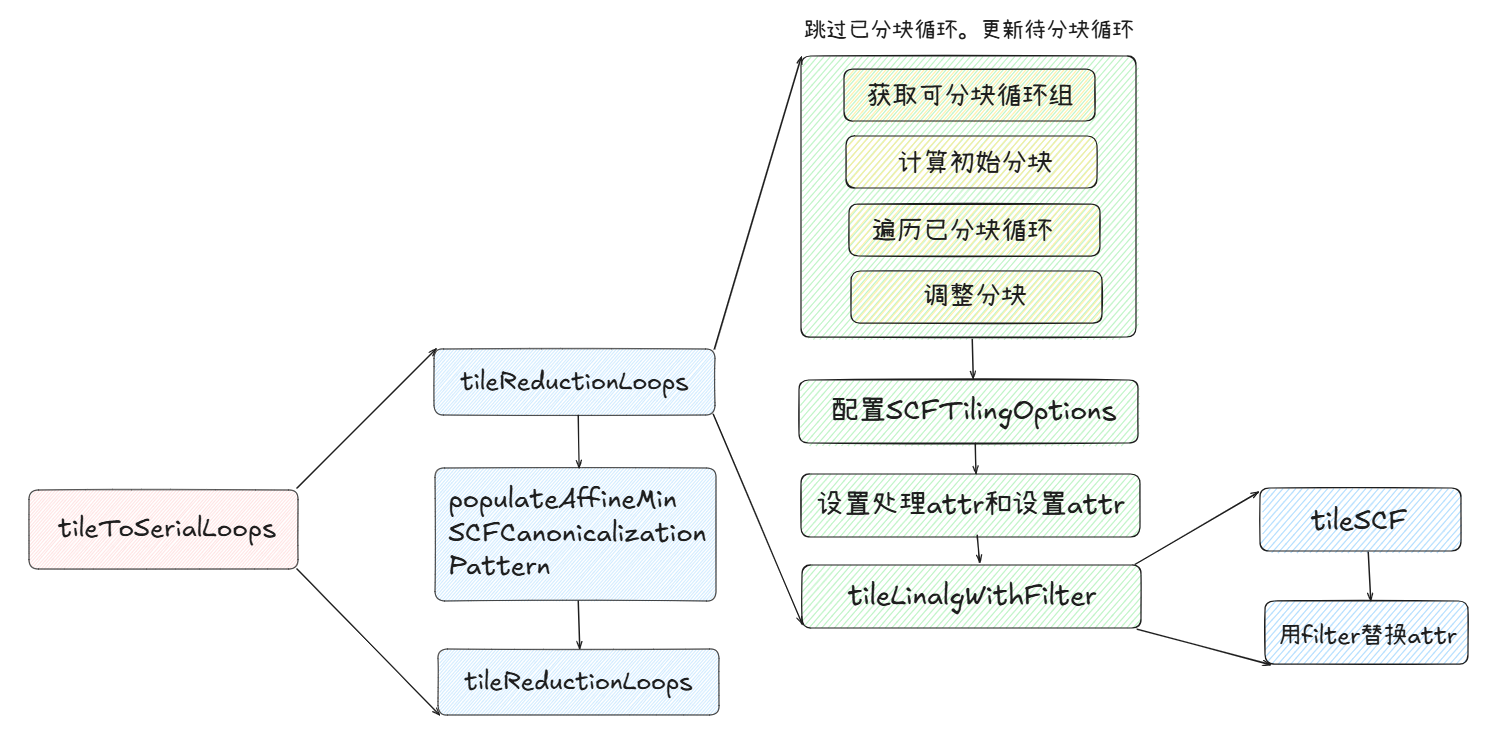
上图大体总结了一下tileToSerialLoops的调用链。这段代码比较重要的一个函数是tileSCF(),该函数底层调用tileUsingSCF()函数实现,感兴趣读者可以自行阅读mlir/lib/Dialect/SCF/Transforms/TileUsingInterface.cpp中的源码实现。
Step4(当workgroup中的线程数大于warp,则A和B也可以做提升)
这一步骤主要完成如下操作:
- 额外在 shared memory 中申请了两块儿 buffer,用来缓存 A ,B 矩阵
- 在所有涉及到 shared memory 读写的地方(memref.copy)前后加上
gpu.barrier。
接下来结合具体的代码逻辑进行解读:
1 | SmallVector<int64_t> workgroupSize = maybeWorkgroupSize.value(); |
这段代码的判断条件是workgroup的[0],[1],[2]相乘是否大于warp,大于说明workgroup内部也需要做warp的tiling。这也导致A和B会有重用的可能性,因此最好也存入shared memory中。这一步骤的逻辑具体参考populateContractPromotionPatterns():
1 | /// 这段代码是 MLIR(Multi-Level Intermediate Representation)中的一个 重写模式(Rewrite Pattern), |
这段代码很好地体现MLIR基础设施的可复用性的强大之处以及Google团队的良好封装。代码中最重要的点是LinalgPromotionPattern,这是IREE对于MLIR的RewritePattern的封装和扩展。具体的依赖关系如下所示:

我们先来解读第一层封装:LinalgBasePromotionPatter
1 | //===----------------------------------------------------------------------===// |
可以看到,在类的构造中,最重要的是LinalgTransformationFilter和LinalgPromotionOptions。这两个具体内容在patterns.insert中定义好了:
1 | patterns.insert<LinalgPromotionPattern<linalg::MatmulOp>, |
其中,LinalgTransformationFilter和我们之前遇到的作用一样,将WorkgroupKTiledMark变成WorkgroupMemoryMark。而LinalgPromotionOptions的定义特别有趣,显示指定了如何做内存释放,如何设置拷贝函数,要提升的操作数是哪个(0,1对应lianalg.xxOp的operand 0和1,在我们的case中是A和B)以及提升的维度。追溯LinalgPromotionOptions的定义,可以看到该类是LLVM公共class,通过回调的方式,允许用户自定义这些操作具体的执行逻辑。
讲解完这个类的构造,另一个重点就是matchAndRewrite实际的改写逻辑。阅读代码注释即可明白原理:
1 | LogicalResult matchAndRewrite(Operation *op, PatternRewriter &rewriter) const override { |
这段代码特别好的点是,这里的所有诸如promoteSubviewsPrecondition()函数均是Linalg Dialect的transform原生支持的。因此这段IREE的封装是很好的处理memory promotion问题的范例,可以直接移植入用在别的项目。
解读好第一层封装,我们来到最上层封装:LinalgPromotionPattern
1 | template <typename OpTy> |
这段代码唯一的trick是,第一个构造函数的模板参数typename ConcreateOpTy = OpTy配合OpTy::getOperationName()形成**SFINAE约束**。当OpTy不包含静态getOperationName()方法时,该构造函数被丢弃,不会导致编译错误,起到保护机制。
这一阶段生成的最终IR如下:
1 | func.func @matmul_accumulate_512x128xf16_times_128x512xf16_into_512x512xf16_for_LLVMGPUMatmulTensorCore_32_32_16_64_2_1_dispatch_0_matmul_512x512x128_f16() attributes {translation_info = #iree_codegen.translation_info<pipeline = LLVMGPUMatmulTensorCore workgroup_size = [64, 2, 1], {pipeline_depth = 3 : i64, store_stage = 1 : i64}>} { |
和上一阶段相比,其不同是显而易见的,具体为A和B 提升到共享内存,更多的显示copy,以及gpu.barrier同步shared memory拷贝。

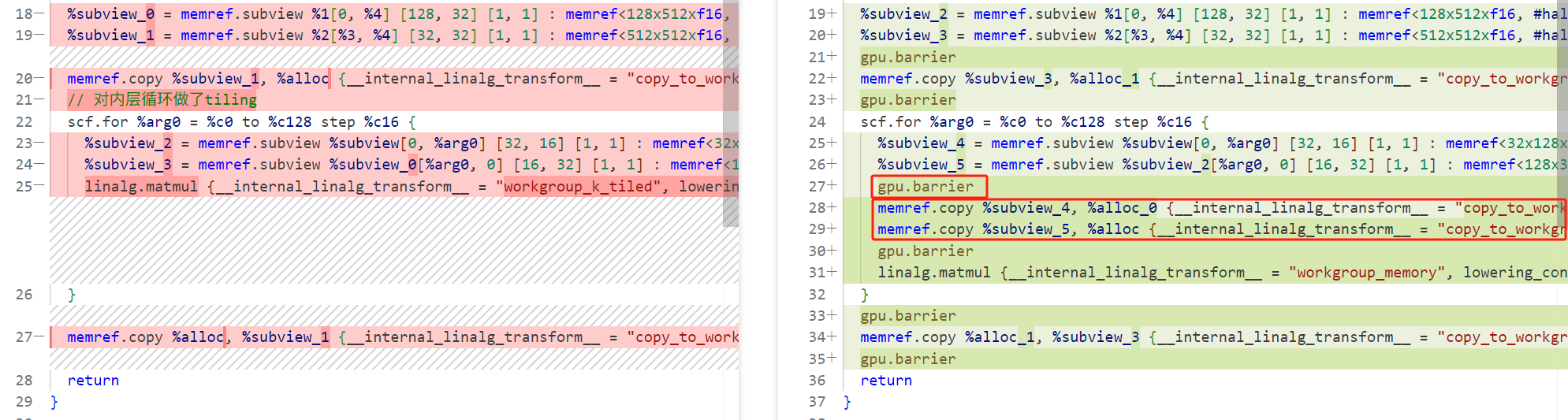
Step5(针对warp进一步分块)
1 | func.func @matmul_accumulate_512x128xf16_times_128x512xf16_into_512x512xf16_for_LLVMGPUMatmulTensorCore_32_32_16_64_2_1_dispatch_0_matmul_512x512x128_f16() attributes {translation_info = #iree_codegen.translation_info<pipeline = LLVMGPUMatmulTensorCore workgroup_size = [64, 2, 1], {pipeline_depth = 3 : i64, store_stage = 1 : i64}>} { |
这一步是为后续将linalg.matmul算子变成WMMA API做准备。workgroup size(表示有多少个线程) 以 warp 粒度(32个线程一个warp)对 thread block([32,32,16]) 进行进一步的 tiling分块。我们的workgroup size是[64,2,1],而warp是32,因此应该有[2,2,1]个warp。对thread blcok需要做[2,2,1]的tile拆分,为[32/2, 32/2, 16/1] = [16,16,16]。由于我们的代码是f16,根据compiler/src/iree/compiler/Codegen/LLVMGPU/Verifiers.cpp中的getInstructionShape()方法:
1 | /// Returns the shape of the math instruction for the given pipeline and input |
tensor core中的f16是[16,16,16] matmul矩阵运算。因此我们的尺寸正好匹配。这个warp tile步骤在源码中是tileToInvocation():
1 | /// Patterns for thread level tiling. |
这一块搭配注释阅读源码已经很清晰了。相比前一个k维度tile,整体结构都是一样的(再一次感叹Google团队和MLIR社区的良好封装,大大简化冗余代码)。
这一步骤得到的代码变化如下:

最重要的点完成了分块,并分配好了每个线程完成的任务(通过thread_id_x和thread_id_y):
1 | %5 = affine.apply affine_map<()[s0] -> (s0 * 16)>()[%thread_id_y] // y方向起始行 |
一个thread,通过(d0 floordiv 32)找到其属于的warp组,并通过*16找到其warp组负责的列。可以看到x方向总共可以分为两个warp,一个warp加载连续的16个列,符合coalesced memory优化。至于y,由于只有2个线程,难以构成warp,同时y方向也没法利用coalesced warp,直接每个线程处理连续16行即可。对这一部分具体细节不明白的,可以参考calculateDistributedTileSize源码或是深入理解coalesced memory优化。calculateDistributedTileSize计算每个thread或是warp对应的tile大小,具体函数如下:
1 | /// Return the tile size associated to one thread or warp based on the number of |
这里有个注意的地方,每一处tile优化,IREE都提供了规则化善后:
2
3
4
5
6
7
8
9
10
11
// Apply canonicalization patterns.
RewritePatternSet threadTilingCanonicalizationPatterns =
linalg::getLinalgTilingCanonicalizationPatterns(context);
populateAffineMinSCFCanonicalizationPattern(
threadTilingCanonicalizationPatterns);
if (failed(applyPatternsAndFoldGreedily(
funcOp, std::move(threadTilingCanonicalizationPatterns)))) {
return signalPassFailure();
}
}这段代码值得借鉴。
至此便是完整的tileAndDistribute流程。可以看到整个流程的逻辑其实是比较简单的,但在这里做了极其详细的分析,因为这个pass设计大量的tiling优化,其思想和具体实现是值得参考借鉴的。在前面的博客中已经详细讲过tiling优化,在各种异构架构(GPU/NPU)中,都有多层级缓存架构,tiling大有用武之地。
GPUMultiBufferingPass
在完成分块划分和面向GPU的并行负载分配工作后,IREE针对GPU的流水线特性做GPUMultiBufferingPass。这个pass代码量只有小一百行,但是要想真正弄懂这个pass,需要对GPU的流水线技术有一定了解。本博客只针对GPU软件流水线做简要介绍。在IREE GPUMultiBufferingPass解读博客中有这样一段话:
通过广泛使用软件流水线技术,CUTLASS 可以最大程度地利用 GPU 的计算资源,并提高矩阵乘法的性能。软件流水线阶段包括:
- 从全局内存加载数据
- 将数据拷贝至共享内存 / 进行必要的预处理
- 执行计算
- 将计算结果写回共享内存或全局内存
在软件流水线结构中,GPU 在使用共享内存的数据执行当前计算的同时,还应从全局内存中读取下一次计算所需数据。因此,从存储层次结构的角度看,在共享内存级别应使用多缓冲模式,保证在上游流水线阶段将数据写入共享内存的同时,下游流水线阶段可以从共享内存中加载数据到寄存器。换言之,循环中的不同迭代使用不同缓冲区,从而消除迭代间的数据依赖。多缓冲模式中应使用的缓冲数量取决于流水线深度(也称流水线阶段数量)。
如下图所示,是GPU软件流水线的示意图:
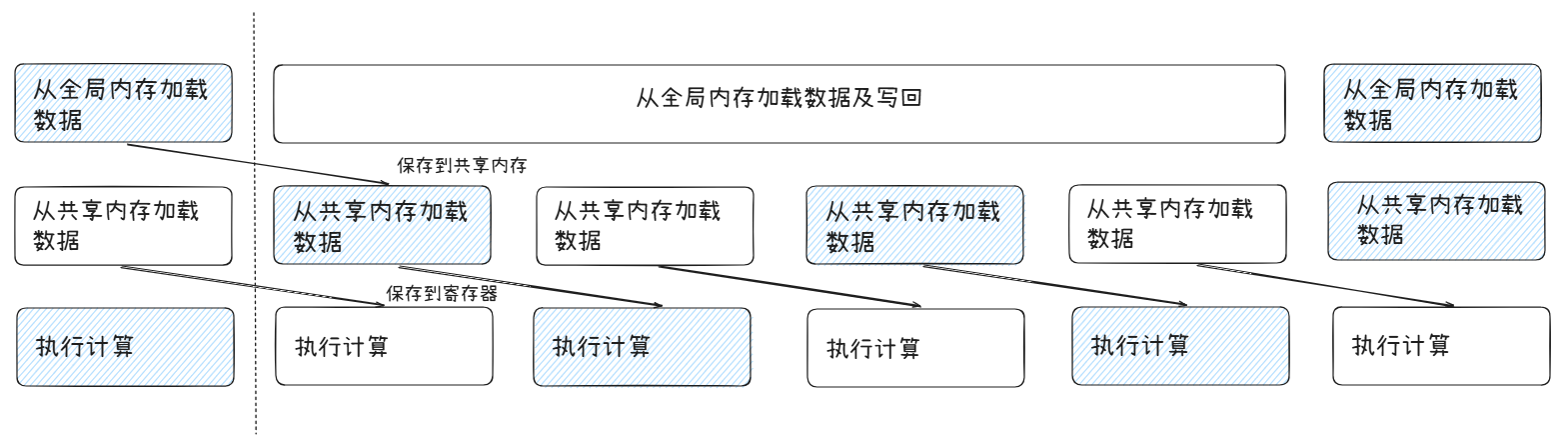
可以看到,GPU的流水线和CPU多级流水线本质原理一样,但是由于GPU的分支逻辑简单,流水线设计相比CPU已经是大大简化了。
相信到这里,大家对于GPU软件流水的作用有了基础的认知。接下来解读GPUMultiBufferingPass,这个pass的代码比较简洁,这里选择直接贴出源码:
1 | // Copyright 2022 The IREE Authors |
这个pass只有当GPU设定的流水线大于1的时候,才会启用,核心目的是通过multibuffer技术来overlap计算和数据传输的延迟开销。该pass的具体流程如下:
收集所有shared memory的开辟操作(allocOp),并提前到入口函数处,旨在方便后续优化
判断每个开辟的空间,是否在后续的循环中有使用,并且不存在loop carried依赖。
Loop Carried依赖 是指循环中不同迭代之间的数据依赖关系,即后续迭代的执行依赖于前面迭代的结果。这种依赖限制了循环的并行化能力,因为迭代无法独立执行,必须按顺序进行。
例如:
1
2
3for (int i = 1; i < N; i++) {
A[i] = A[i-1] + B[i]; // 第i次迭代依赖第i-1次的结果
}调用memref dialect的方法:
multiBuffer()完成多缓冲技术。
大体读完pass后,我们来思考一下multiBuffer()技术是如何优化GPU流水线的。首先通过debug手段直观感受一下这个pass给IR带来的变化。在pass执行之前,我们的IR代码如下:
1 | func.func @matmul_accumulate_512x128xf16_times_128x512xf16_into_512x512xf16_for_LLVMGPUMatmulTensorCore_32_32_16_64_2_1_dispatch_0_matmul_512x512x128_f16() attributes {translation_info = #iree_codegen.translation_info<pipeline = LLVMGPUMatmulTensorCore workgroup_size = [64, 2, 1], {pipeline_depth = 3 : i64, store_stage = 1 : i64}>} { |
经过该pass之后,中间代码变动如下:
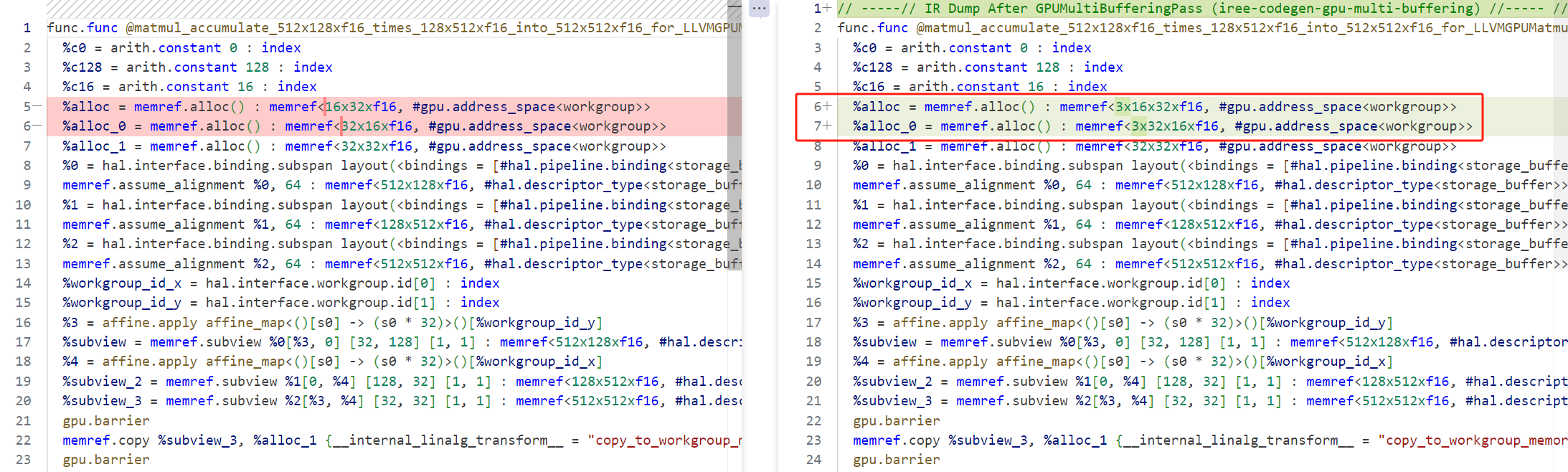
如上图所示将A和B矩阵buffer成三份。在tileAndDistributePass中,C矩阵的allo在循环外,并且没有在循环使用,所以不参与MultiBufferPass。而A和B矩阵,当workgroup比warp大,会针对warp做tiling,A和B矩阵的shared memory的alloc因此在tile循环中,可以参与multiBuffer优化。由于我们设置的 pipeline depth = 3,因此 Matrix A ,B对应的 shared memory 会进行 factor = 3 的 multi-buffering。
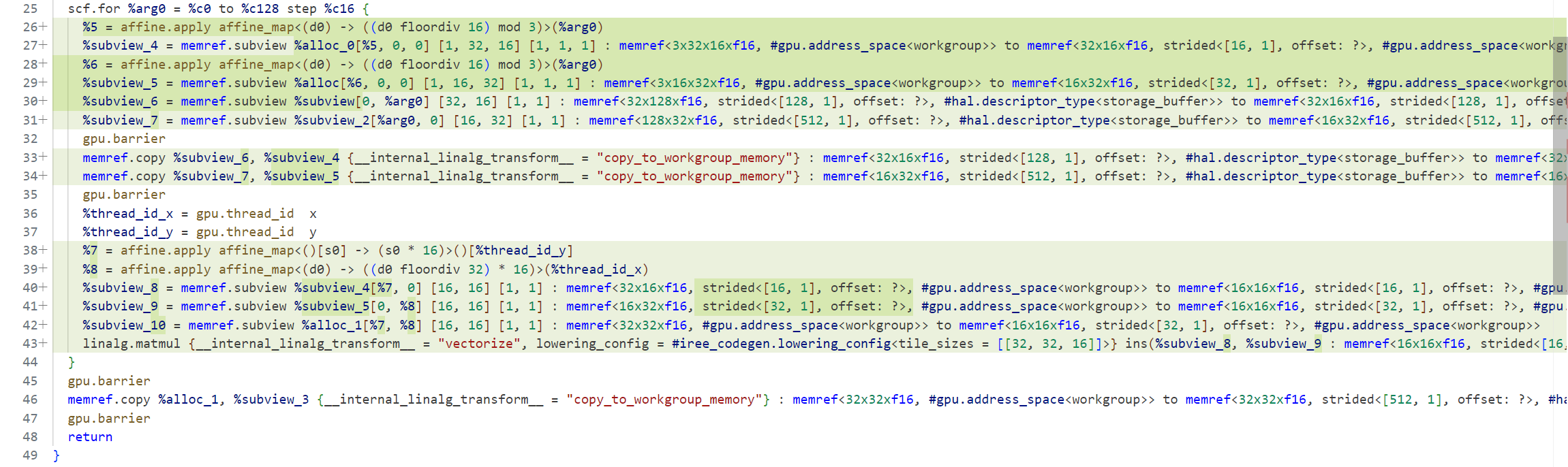
上图是内层k维度循环中的计算逻辑,也是MultiBuffer主要变换的代码逻辑。在矩阵乘法中,由于为了适配warp大小,做了warp分块(c0 to c128 step c16)。针对每一分块,先将work group mem拷贝入shared mem中,然后计算再拷贝出去。通过引入多缓冲机制,可以将每个循环的各个阶段overlap,以减少延迟,其可视化状态图如下:
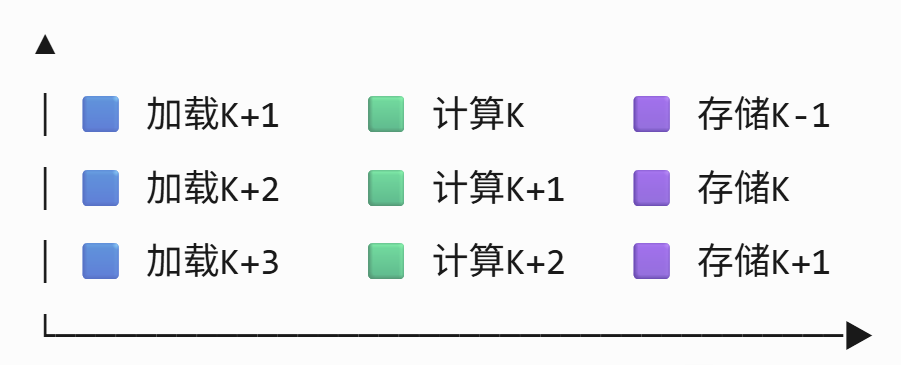
可以看到每个单元同一时间都不空闲,因此IREE该pass的多缓冲机制是make sense的。完成多缓冲人物的核心是MLIR提供的memref::multiBuffer(),由于篇幅原因不深入解读,仅仅提供一个流程图概括整个过程。感兴趣的可以结合源码以及IREE GPUMultiBufferingPass解读加深理解。该函数中很多可以复用的基础组件写法在此也简单罗列一下,以备以后自行实现组件时参考。
流程图
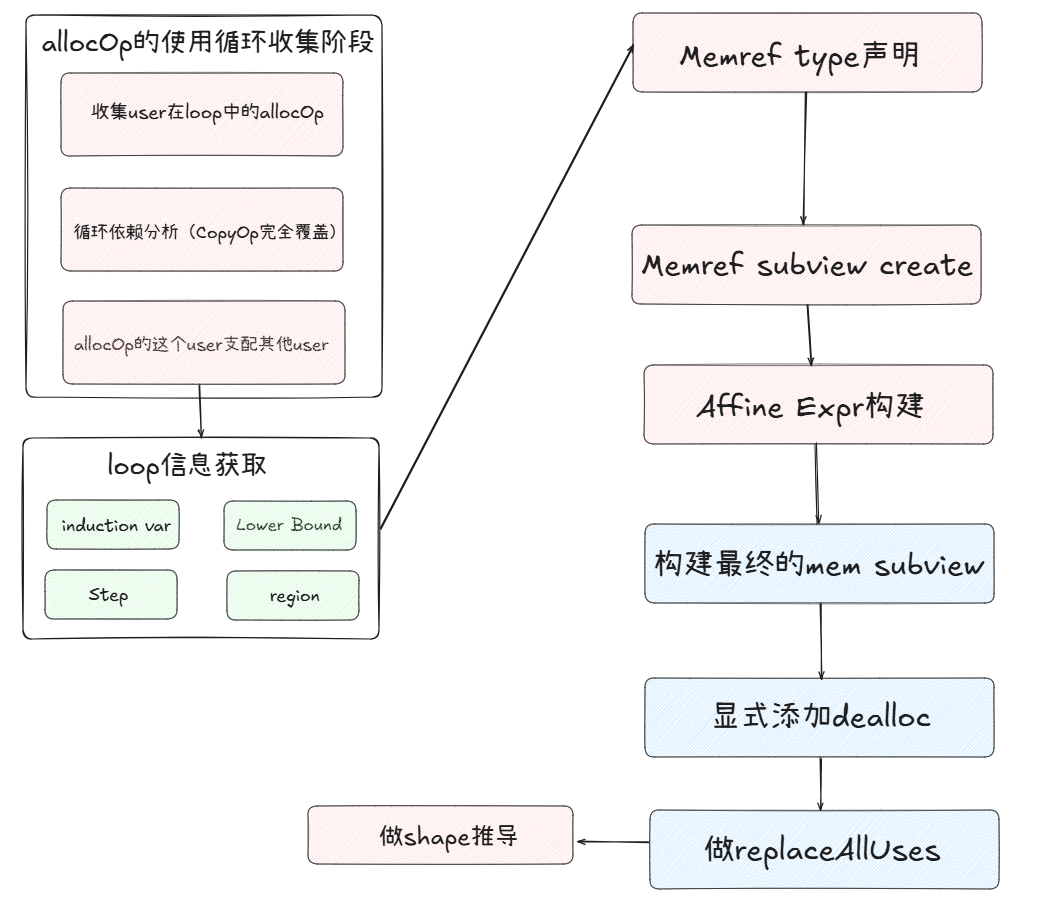
代码组件
1 | // ==================================== 获取loop信息 ======================================== |
1 | // 1. Construct the multi-buffered memref type. |
1 | // 2. Create the multi-buffered alloc. |
1 | // 3. Within the loop, build the modular leading index (i.e. each loop |
1 | // 4. Build the subview accessing the particular slice, taking modular |
1 | // 5. Due to the recursive nature of replaceUsesAndPropagateType , we need to |
LLVMGPUTensorCoreVectorizationPass

这个pass的主要作用,是将linalg方言下降到vector方言中。MLIR针对linalg.matmul算子提供vector.contract表示。
GPUDistributeSharedMemoryCopyPass
这个pass的作用是将共享内存的拷贝操作分配到各个线程中。
GPUReduceBankConflictsPass
这个pass是比较有趣的一个优化点,通过对memref.alloc添加padding的方式,消除GPU中的bank conflict。这个padding逻辑的一大问题是,均是通过用户手动来指定padding size。因此本pass仅仅做个流程图解读一下:
.png)