Compiler部分概览
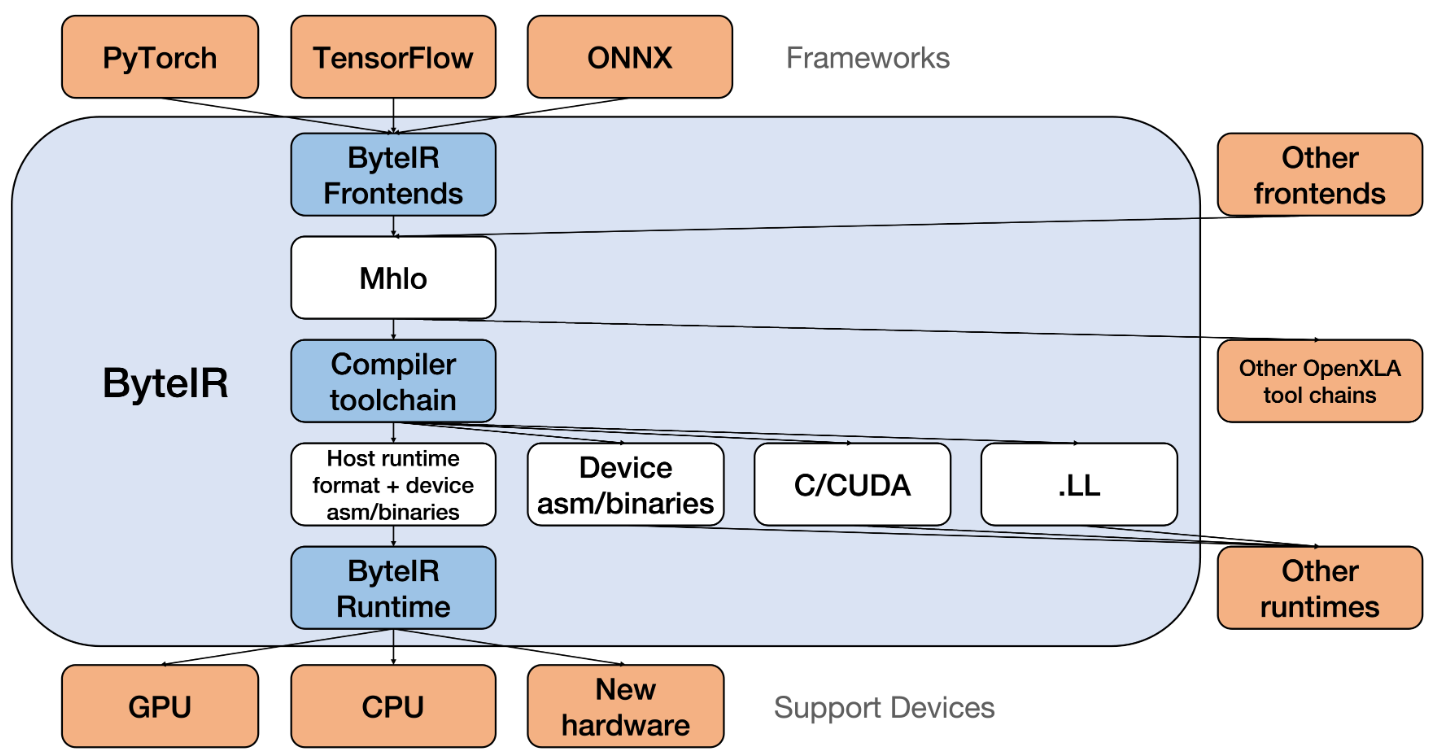
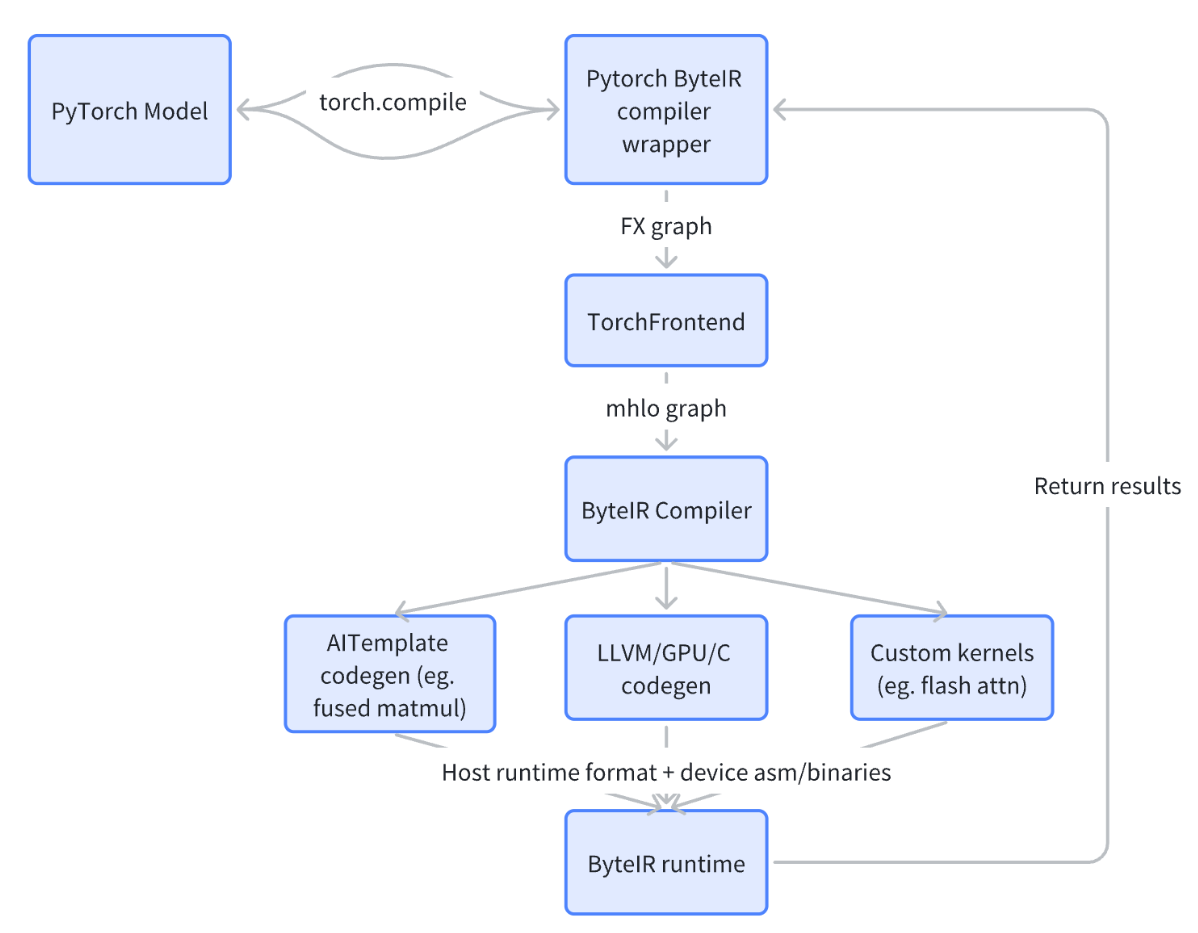
ByteIR的compiler部分设计遵循标准的mlir层级转换流程,上图所示是前端,中间compiler和后端runtime的架构图。compiler的输入是MHLO dialect(包含部分ByteIR针对特定算子的扩展),输出是mlir(host code)和ptx(默认的cuda device后端中间形式)。最终输出给到runtime做调度和GPU上执行。如下图所示是compiler的编译优化流水线架构图:
graph TD
A[Start: hlo-graph-opt] --> B[hlo-fusion-opt]
B --> C[linalg-tensor-opt]
C --> D[byre-tensor-opt]
D --> E[byteir-bufferize-opt]
E --> F[linalg-memref-opt]
F --> G[scf-opt]
G --> H[gpu-opt]
H --> I[inline + lccl-to-byre + gpu-launch-func-to-byre]
I --> J[set-op-space & set-arg-space]
J --> K[byre-opt]
K --> L[nvvm-codegenfor device]
K --> M[byre-hostfor host]
M --> N[remove-module-tag]
L --> O[translate_to_ptx]
N --> P[write host MLIR / MLIRBC]