
BladeDISC编译器是一个完整的端到端机器学习编译器,其整个流水线的亮点是动态shape支持和大尺度计算密集和内存密集算子融合支持。整个流水线参考XLA的设计,本博客结合实际测试case讲解BladeDISC的流水线设计。
Pass Pipeline日志
1 | ===-------------------------------------------------------------------------=== |
1 | ===-------------------------------------------------------------------------=== |
Pipeline罗列
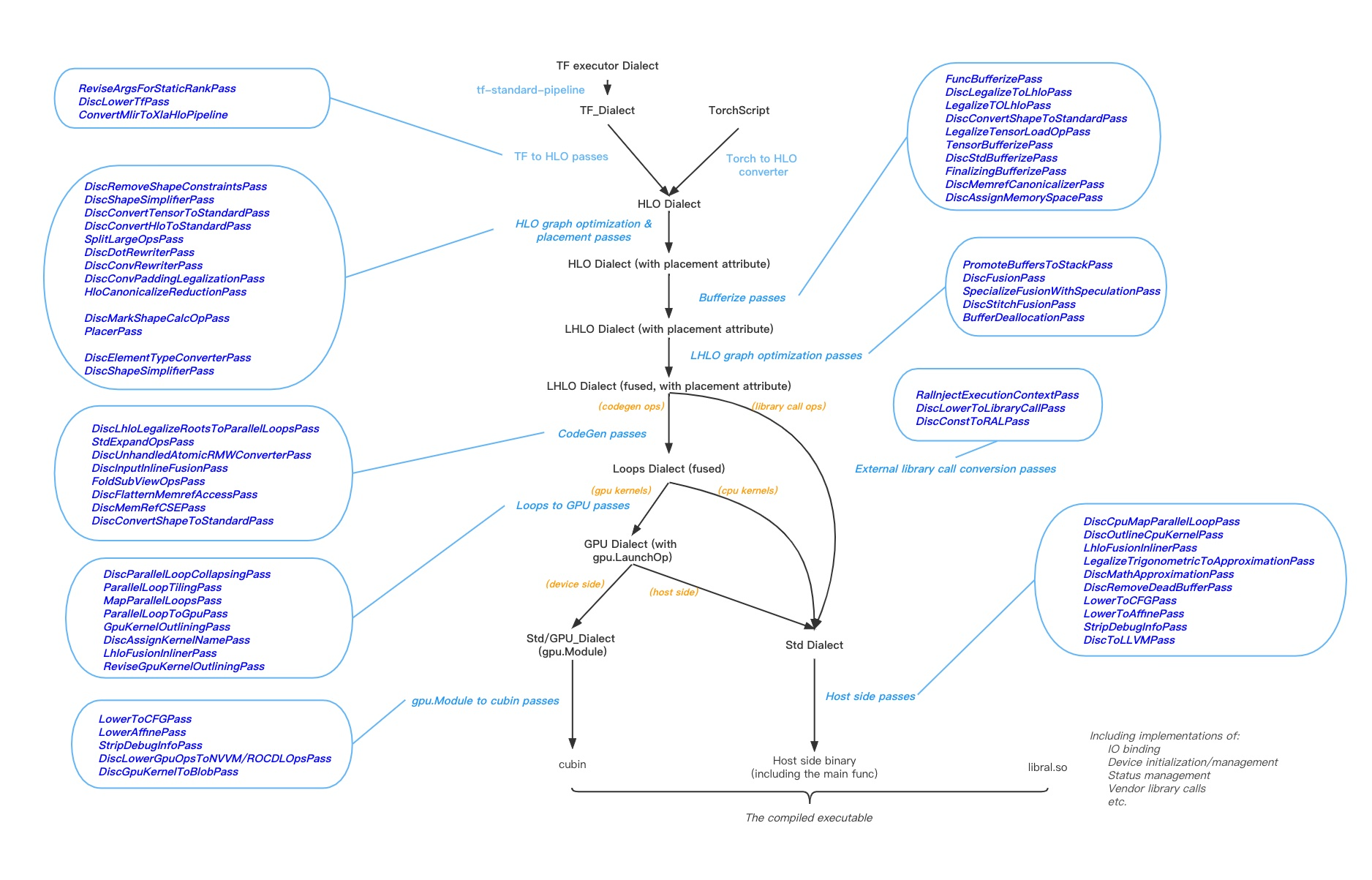
以下是DISC动态形状编译器Pass管道的阶段划分及对应Passes:
1. TF-to-HLO转换阶段
| Pass名称 | 功能描述 |
|---|---|
-disc-tf-revise-args-for-static-rank |
为静态秩编译器修订参数,处理动态形状但静态秩的约束 |
-disc-lower-tf |
将TensorFlow操作转换为MHLO操作,处理自定义调用(如RandomUniform和TopK) |
-tf-shape-inference |
执行形状推断,优化静态形状语义 |
-xla-legalize-tf |
将TensorFlow操作合法化为XLA/HLO操作,分阶段处理部分/完全转换 |
2. HLO图优化阶段
(1) 形状简化与约束
| Pass名称 | 功能描述 |
|---|---|
ShapeSimplifierPass |
传播已知形状信息,消除不必要的未知维度(支持静态秩约束) |
InsertTieShapePass |
插入disc_shape.tie_shape操作,显式表达形状约束 |
(2) 放置(Placement):key:
DiscMarkShapeCalculationPassgraph TD A[开始] --> B[获取Module和主函数main] B --> C{主函数存在?} C -->|是| D[初始化标记集合shape_calc_ops] C -->|否| E[Pass失败终止] D --> F[直接标记阶段] F --> G[遍历基本块所有操作] G --> H{是否目标操作?} H -->|是| I{是GetDimensionSizeOp/FromElementsOp/ExtractOp?} H -->|否| G I -->|是 且 非WhereOp输入| J[加入标记集合] I -->|否| K[查表获取操作数索引] K --> L[遍历所有需标记的操作数] L --> M{操作数有效且符合条件?} M -->|是| N[加入标记集合] M -->|否| L F --> O[逆向传播阶段] O --> P[逆序遍历基本块操作] P --> Q{已标记操作?} Q -->|是| R[遍历所有操作数] R --> S{操作数有效且符合条件?} S -->|是| T{是DimOp/ShapeOfOp?} T -->|否| U{静态张量且元素>64?} U -->|否| V{来自WhereOp?} V -->|否| W[加入标记集合] O --> X[属性设置阶段] X --> Y[遍历标记集合中的操作] Y --> Z{输出是元组类型?} Z -->|是| AA[设置数组属性] Z -->|否| AB[设置布尔属性] X --> AC[Pass完成] style A fill:#90EE90,stroke:#333 style E fill:#FF6347,stroke:#333 style J fill:#87CEEB,stroke:#333 style N fill:#87CEEB,stroke:#333 style W fill:#87CEEB,stroke:#333 style AA fill:#FFD700,stroke:#333 style AB fill:#FFD700,stroke:#333 style AC fill:#90EE90,stroke:#333PlaceOpsPassgraph TD A[开始] --> B[初始化输入输出放置信息] B --> C[处理CustomCallV2操作] C --> D[处理i64标量返回操作] D --> E[处理形状计算操作] E --> F[处理i32类型操作] F --> G[设置默认设备放置] G --> H[插入内存拷贝节点] H --> I[结束] subgraph 初始化 B[解析入口函数的输入输出属性
填充input_placements_和output_placements_] end subgraph 规则处理 C[遍历CustomCallV2Op
根据device属性设置CPU/GPU] D[标记返回的i64标量操作
向上标记相关操作数] E[遍历所有操作
根据kDiscShapeCalcAttr标记CPU] F[遍历所有操作
处理32位整数相关操作规则] end subgraph 默认处理 G[遍历所有未标记操作
设置默认GPU/CPU放置] end subgraph 跨设备处理 H[遍历所有操作和返回节点
分析输入输出设备差异
插入H2D/D2H转换操作] end
| Pass名称 | 功能描述 |
|---|---|
DiscMarkShapeCalculationPass |
标记形状计算操作(如tensor.dim) |
PlaceOpsPass |
将形状计算操作显式分配到CPU,插入内存拷贝操作 |
(3) 图优化
| Pass名称 | 功能描述 |
|---|---|
| 代数简化器 | 执行通用代数优化(如常量折叠、冗余消除) |
(4) 其他转换
| Pass名称 | 功能描述 |
|---|---|
RemoveShapeConstraintsPass |
移除不再需要的形状约束操作 |
DotRewriterPass |
将mhlo.dot转换为mhlo.dot_general以支持更灵活的代码生成 |
3. 缓冲化(Bufferization)阶段
| Pass名称 | 功能描述 |
|---|---|
HLO-to-LMHLO转换 |
将MHLO操作转换为LMHLO(内存缓冲区形式) |
ShapeRelatedOpsBufferization |
处理形状相关操作的缓冲化(如tensor.from_elements) |
DiscAssignMemorySpacePass |
显式分配内存空间(CPU/GPU) |
PromoteBuffersToStack |
将小型CPU缓冲区提升为栈分配 |
BufferDeallocation |
插入显式的memref.dealloc操作 |
4. LHLO图优化阶段:key:
(1) 融合(Fusion)
这一部分内容,详情参考先前的一篇存储密集算子融合博客。
| Pass名称 | 功能描述 |
|---|---|
DiscFusionPass |
基础融合策略(类似XLA的输入/循环融合) |
DiscStitchFusionPass |
激进融合策略(利用共享内存或缓存优化) |
(2) 推测优化(Speculation)
-
DiscSpecializeFusionWithSpeculationPass
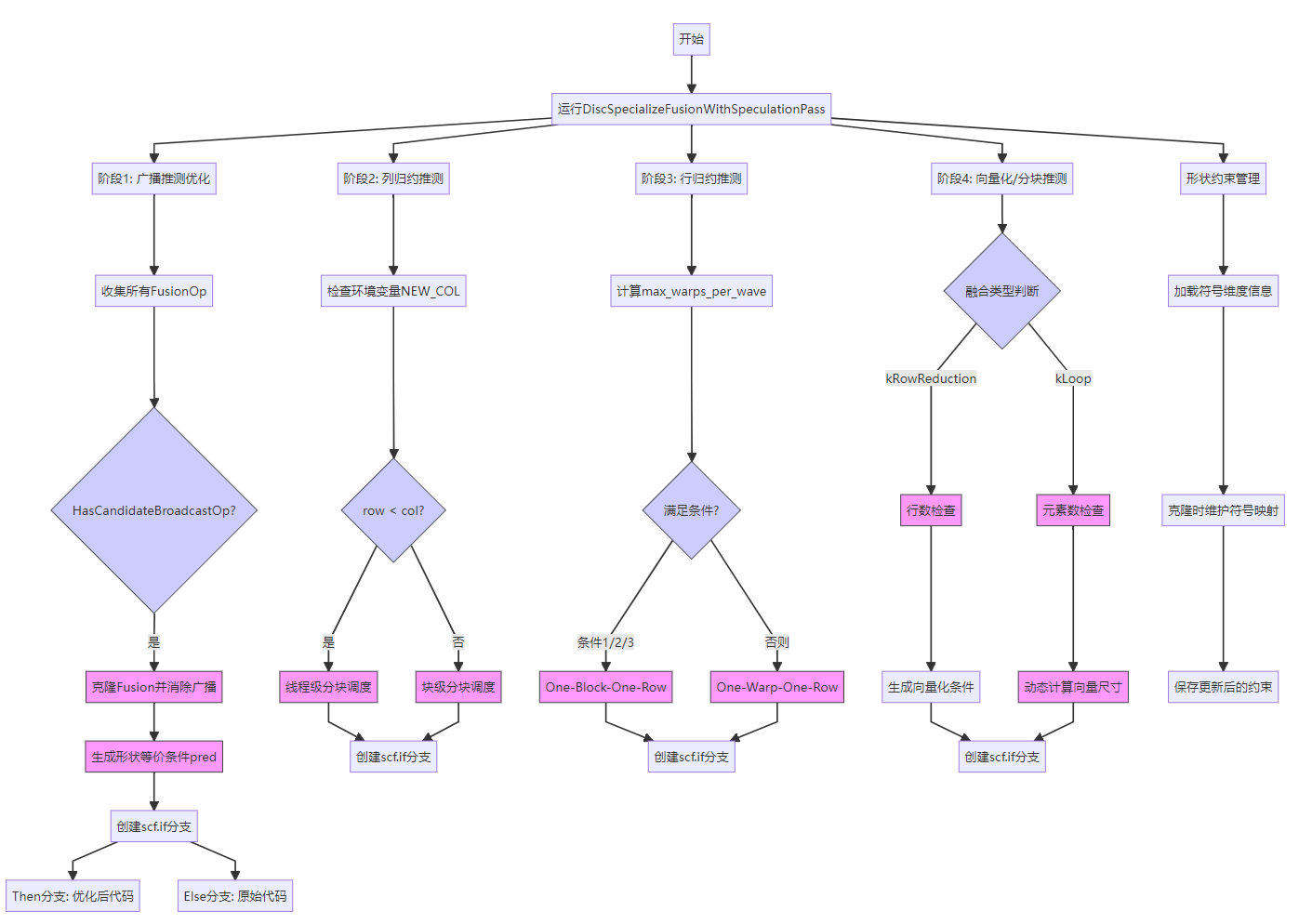
| Pass名称 | 功能描述 |
|---|---|
DiscSpecializeFusionWithSpeculationPass |
生成多版本内核以适配不同运行时形状 |
5. 运行时与库调用相关阶段:key:
RalInjectExecutionContextPass(这个pass比较简单,所以看过代码即可)DiscLowerToLibraryCallPass:fire:这个pass比较重要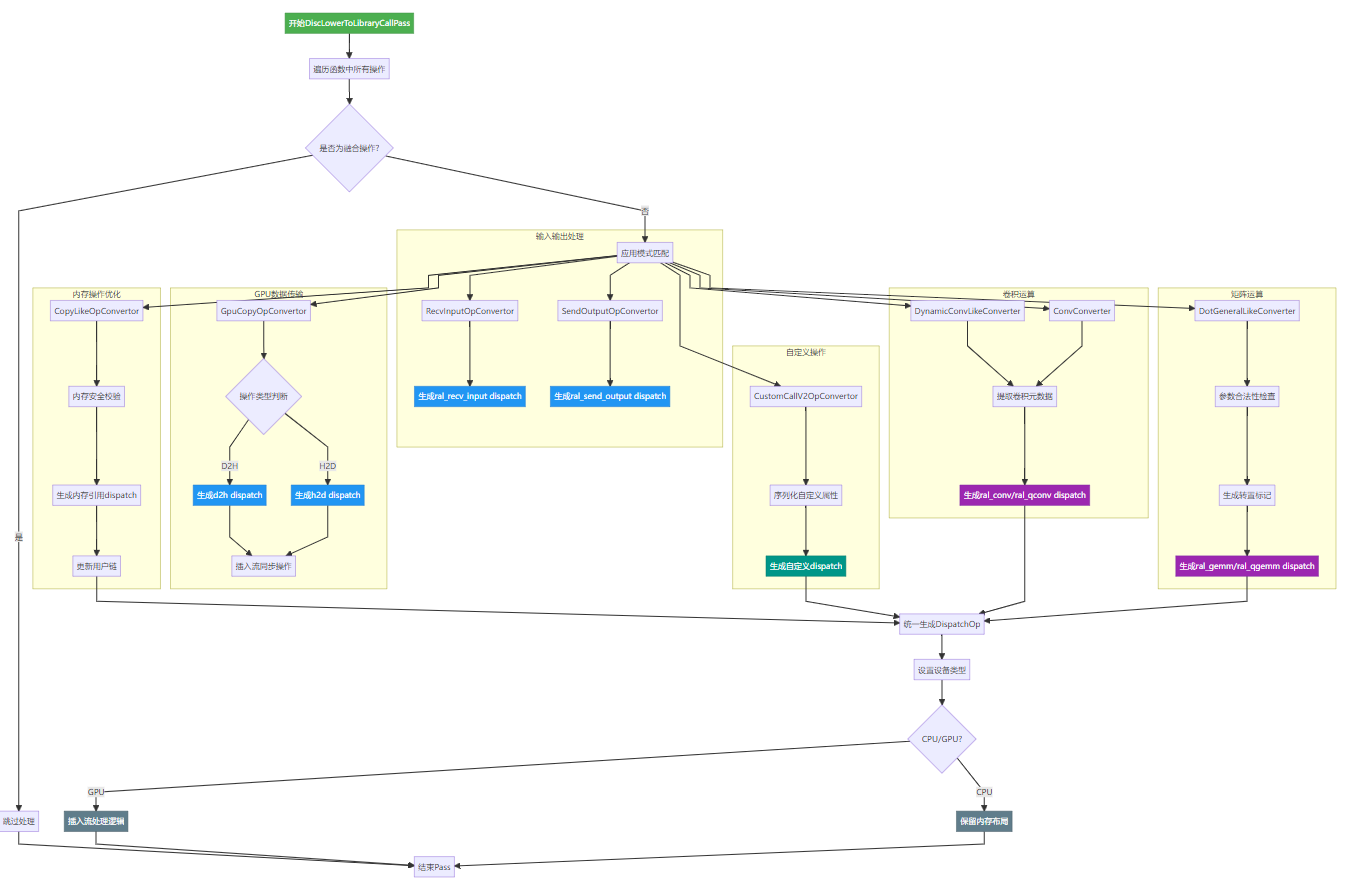
这个pass有几个比较有趣的改写过程,接下来详细解读。
CUDA GPU copy操作
首先是代码中对于gpu copy的处理。在cuda中,gpu copy可能有两个方向:H2D和D2H。cuda为了支持数据传输和kernel执行的并行性,引入
cuda stream这个概念。可以参考CUDA stream blog来加强理解。首先结合下面的图理解传输和kernel计算并行是如何带来性能收益的:
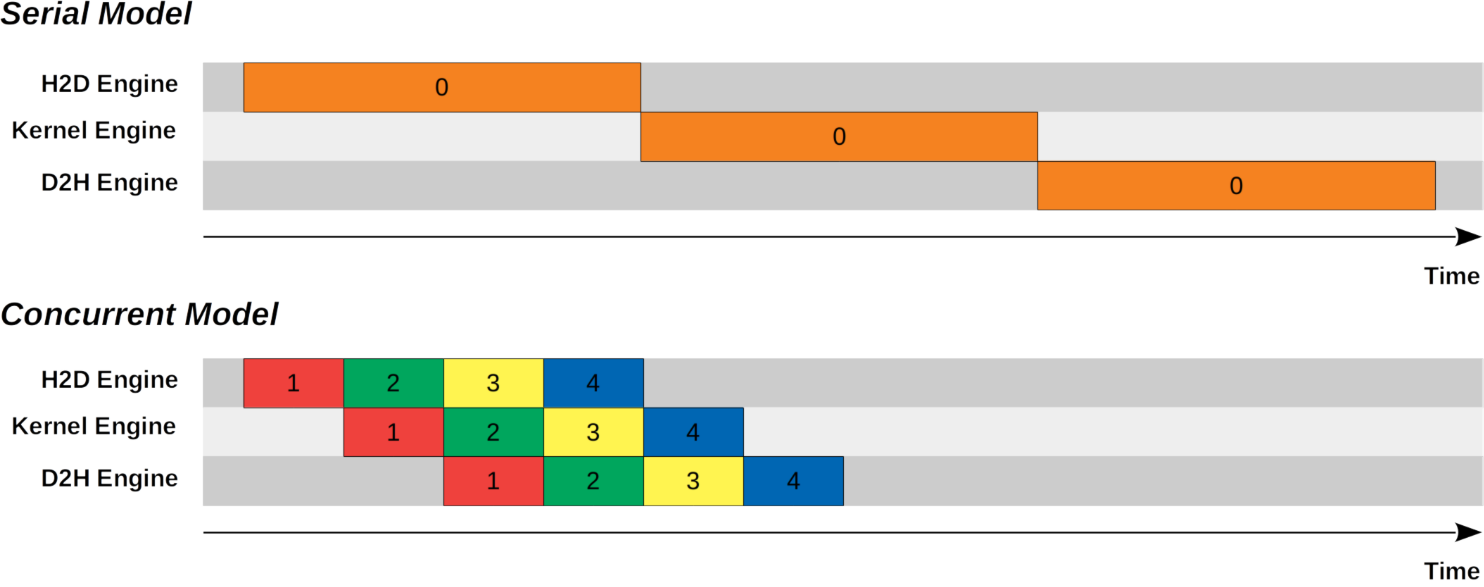
在cuda中,通过stream这个概念来指导并行执行:
According to the CUDA programming guide, a stream is a sequence of commands (possibly issued by different host threads) that execute in order. Different streams, on the other hand, may execute their commands out of order with respect to one another or concurrently.
在cuda的默认模式中,不论是kernel执行,h2d的内存拷贝还是d2h的内存拷贝,都使用的默认stream(null stream或是0stream)。在早期版本中,default stream必须等待已经launch的stream完成才能开始,并在其他stream开始之前完成。显然,default stream是顺序模型。
如下是一段sample code:
1 |
|
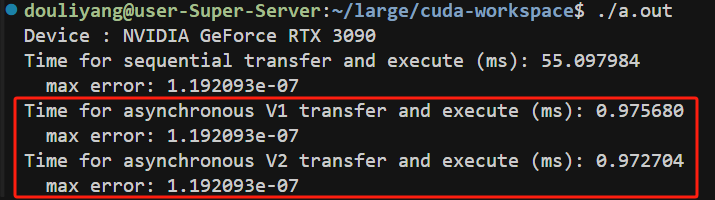
从结果来看,stream有效提高并行性,降低等待延迟。至于V2相比V1,由于V1中的每个stream的H2D,kernel计算和D2H必须顺序执行,因此计算资源和dma带宽利用率不如V2。
注意,目前的BladeDISC只支持单个stream(没有多流支持),因此性能上BladeDISC的传输效率有缺失。这里mark住,后续可以尝试改进。
#### ConvolutionOp Convertor
这个convertor干的事情十分简单:将卷积操作变成显示的lib call。其主要完成的工作如下:
提取出convolution操作的输入(两个)和输出(一个)
根据输出,判断该kernel是在cpu上计算还是gpu上计算
计算padding大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25Value GetPadding(ConvolutionOp op, PatternRewriter& rewriter) const {
// 构建padding的type
Location loc = op.getLoc();
Type field_type = rewriter.getI32Type();
// 获取卷积维度信息,用来判断padding的数量
// <?x?x?x?>四维矩阵,则需要填充宽高两个维度,并左右各一,所以是(rank-2)* 2
int rank = op.getOutput().getType().template cast<ShapedType>().getRank();
int num_metadata_fields = (rank - 2) * 2;
Value metadata_value = rewriter.create<memref::AllocaOp>(
loc, MemRefType::get({num_metadata_fields}, field_type,
MemRefLayoutAttrInterface()));
// padding
auto padding = disc_ral::ConvertDenseIntAttr(op.getPadding());
for (const auto&& en : llvm::enumerate(padding)) {
Value value =
rewriter.create<arith::ConstantIntOp>(loc, en.value(), field_type);
Value offset = rewriter.create<arith::ConstantIndexOp>(loc, en.index());
SmallVector<Value, 1> ivs(1, offset);
rewriter.create<memref::StoreOp>(loc, value, metadata_value, ivs);
}
// 返回[1,1,1,1]
return metadata_value;
}获取卷积操作的metadata,有如下重要参数:
- 维度布局:输入、核、输出的维度顺序
- 步长(Stride):卷积核移动的步幅
- 膨胀(Dilation):卷积核元素的间隔
- 核常量标记:指示核数据是否编译期常量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 元数据内存布局(i32数组)
[
# 输入布局
0, # N维度位置
3, # C维度位置
1, 2, # 空间维度H、W的位置
# 核布局
2, # 输入通道(I)位置(HWC中的C)
3, # 输出通道(O)位置
0, 1, # 空间维度H、W的位置
# 输出布局
0, # N维度位置
3, # C维度位置
1, 2, # 空间维度H、W的位置
# 步长(H方向步长2,W方向步长1)
2, 1,
# 膨胀(H方向膨胀1,W方向膨胀1)
1, 1,
# 核常量标记
1 # 假设核是常量
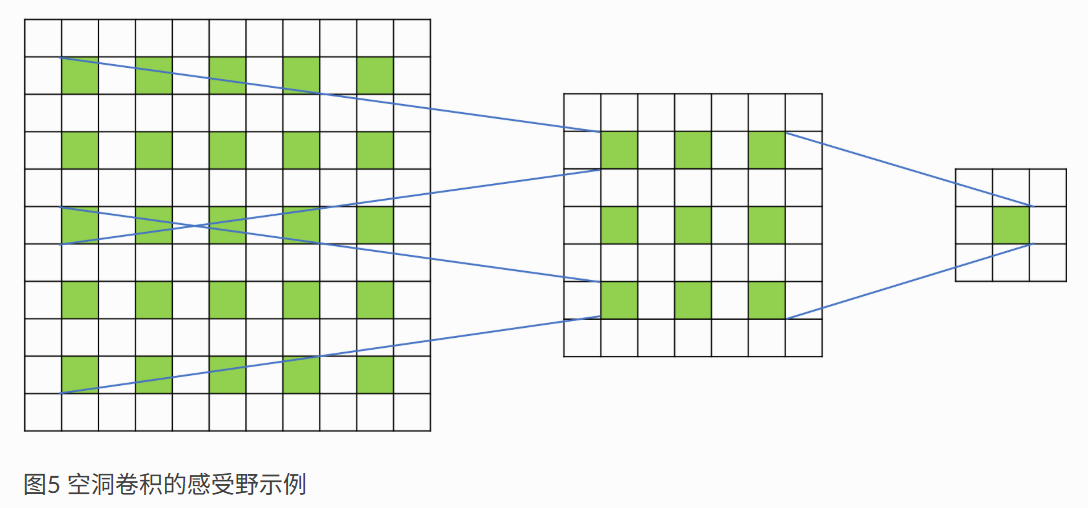
]其中膨胀这个概念比较陌生。其动机是为了扩大感受野的同时不增加计算量,具体地自行参考文献,不是本文重点:
构建operation
完整的流程如下:
1 | LogicalResult matchAndRewrite(ConvolutionOp op, |
DiscConstToRALPass- 跨平台兼容:通过
on_host标志区分主机/设备常量 - 零冗余存储:相同常量数据只保存一份
- 运行时高效查找:通过预生成索引加速常量加载
- 类型安全:在名称中编码数据类型和形状信息
该Pass成功将编译期常量转换为运行时加载机制,为支持动态常量更新和跨模型常量共享奠定了基础。具体作用目前尚不能理解清楚
这个pass的流程图如下所示:
graph TD A[开始] --> B[获取ModuleOp] B --> C[初始化元数据文件emitter] C --> D[遍历模块收集ConstantOp] D --> E{是否在Fusion或特定函数中?} E --> |是| F[跳过] E --> |否| G[加入工作列表] G --> H[遍历工作列表处理每个ConstantOp] H --> I[调用convertConstantOp] I --> J[生成唯一名称和元数据] J --> K[写入元数据文件] K --> L[创建全局字符串符号] L --> M[构建RAL调用DispatchOp] M --> N[替换原常量并删除] N --> O{全部处理完成?} O --> |否| H O --> |是| P[写入元数据尾部] P --> Q{成功?} Q --> |否| R[报错终止] Q --> |是| S[结束] subgraph convertConstantOp子流程 I --> I1[转换i1类型到i8] I1 --> I2[提取常量数据] I2 --> I3[生成MD5哈希名称] I3 --> I4[判断主机/设备类型] I4 --> I5[更新元数据索引] I5 --> I6[创建LLVM全局符号] I6 --> I7[构建DispatchOp参数] end- 跨平台兼容:通过
| Pass名称 | 功能描述 |
|---|---|
RalInjectExecutionContextPass |
注入RAL执行上下文参数 |
DiscLowerToLibraryCallPass |
将非代码生成操作(如GEMM/Conv)转换为disc_ral.dispatch调用 |
DiscConstToRALPass |
将常量操作转换为RAL库调用,管理常量生命周期 |
6. 代码生成阶段:key:
这个阶段的最主要工作是将mhlo操作下降到嵌套循环中。BladeDISC pass pipeline guide中指明代码生成阶段的设计思路:

(1) 主干代码生成
这两个pass在文档中称之为backend bone passes。
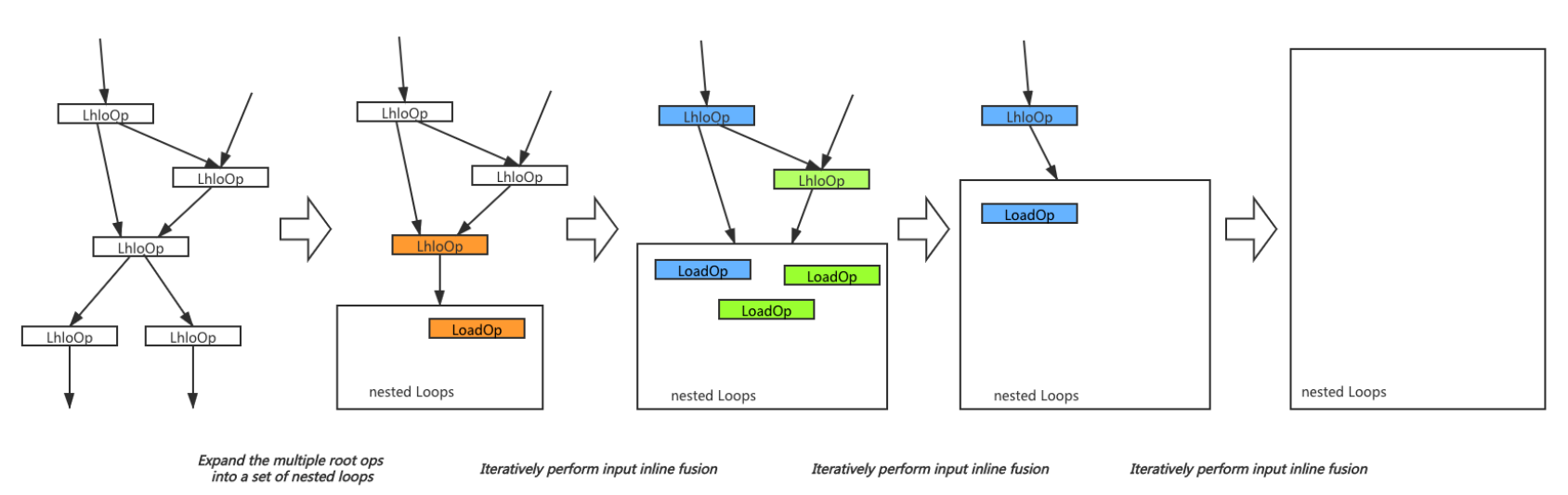
如上图所示,第一个pass负责将root操作变为并行循环function。第二个pass负责不断地把producer op做融合。
第一个pass的并行循环涉及到调度策略,具体地调度策略见下表:
- RowReductionSchedule1:使用两轮Warp Shuffle,适用于较大的归约维度(如行归约维度较大时,减少线程同步开销)。
- RowReductionSchedule2:使用一轮Warp Shuffle,适用于较小的归约维度(减少计算步骤,提升速度)。
- ColReductionSchedule:基于原子操作的列归约,兼容其他行归约调度(灵活性高,但性能可能受限)。
- ColReductionBlockTileSchedule:高性能列归约调度,无法与其他行归约调度共存(专为性能优化,牺牲兼容性)。
- LoopSchedule:普通循环融合调度,通用性强,可与其他调度组合。
若同时存在行和列归约,优先选择行归约调度,列归约退化为原子操作实现,可能生成独立的初始化内核(避免数据竞争)。这一段代码比较有意思,下面重点分析(涉及代码生成的调度选择问题,是gpu launch比较有意思的话题)。
GPU并行调度选择算法
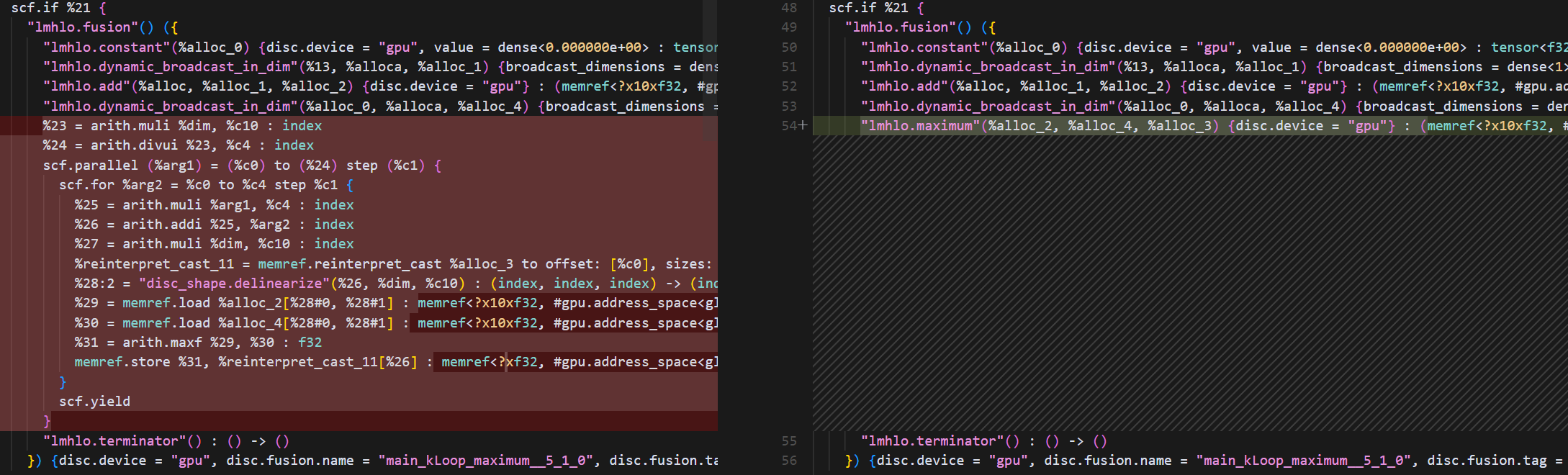
从test case来看:
将
lmhlo.fusion操作的root操作做了循环展开,用scf.parallel来表示可并行的点,在后续的后端特定pass中会变成threadIdx.x和blockIdx.x的gpu访问模型。这里比较有趣的点是scf.parallel内部还嵌套一个scf.for循环,维度为4。这个分支是当维度为4的倍数时做的向量化,一个thread可以并行处理4的SIMD。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110// -----// IR Dump After DiscMemRefLoadStoreSimplifierPass (disc-memref-load-store-simplifier) //----- //
func.func @main(%arg0: !disc_ral.context) attributes {tf.entry_function = {input_placements = "gpu", inputs = "input.1_", output_placements = "gpu", outputs = "8"}} {
%c3_i32 = arith.constant 3 : i32
%c2_i32 = arith.constant 2 : i32
%c1_i32 = arith.constant 1 : i32
%c0_i32 = arith.constant 0 : i32
%0 = llvm.mlir.constant(0 : i32) : i32
%false = arith.constant false
%true = arith.constant true
%c1 = arith.constant 1 : index
%c4 = arith.constant 4 : index
%c10 = arith.constant 10 : index
%c0 = arith.constant 0 : index
%1 = "disc_ral.dispatch"(%arg0, %c0) {backend_config = "", call_target_name = "ral_recv_input", device = "cpu", has_side_effect = false} : (!disc_ral.context, index) -> memref<?x10xf32,
%dim = memref.dim %1, %c0 : memref<?x10xf32,
%2 = llvm.mlir.addressof @__global_const_0 : !llvm.ptr<array<43 x i8>>
%3 = llvm.getelementptr %2[0, 0] : (!llvm.ptr<array<43 x i8>>) -> !llvm.ptr<i8>
%4 = llvm.inttoptr %0 : i32 to !llvm.ptr<i8>
%5 = "disc_ral.dispatch"(%arg0, %4, %3, %c0_i32) {backend_config = "", call_target_name = "ral_const", device = "gpu", has_side_effect = false} : (!disc_ral.context, !llvm.ptr<i8>, !llvm.ptr<i8>, i32) -> memref<10x10xf32,
%6 = llvm.mlir.addressof @__global_const_1 : !llvm.ptr<array<43 x i8>>
%7 = llvm.getelementptr %6[0, 0] : (!llvm.ptr<array<43 x i8>>) -> !llvm.ptr<i8>
%8 = llvm.inttoptr %0 : i32 to !llvm.ptr<i8>
%9 = "disc_ral.dispatch"(%arg0, %8, %7, %c1_i32) {backend_config = "", call_target_name = "ral_const", device = "gpu", has_side_effect = false} : (!disc_ral.context, !llvm.ptr<i8>, !llvm.ptr<i8>, i32) -> memref<10x10xf32,
%10 = llvm.mlir.addressof @__global_const_2 : !llvm.ptr<array<40 x i8>>
%11 = llvm.getelementptr %10[0, 0] : (!llvm.ptr<array<40 x i8>>) -> !llvm.ptr<i8>
%12 = llvm.inttoptr %0 : i32 to !llvm.ptr<i8>
%13 = "disc_ral.dispatch"(%arg0, %12, %11, %c2_i32) {backend_config = "", call_target_name = "ral_const", device = "gpu", has_side_effect = false} : (!disc_ral.context, !llvm.ptr<i8>, !llvm.ptr<i8>, i32) -> memref<10xf32,
%14 = llvm.mlir.addressof @__global_const_3 : !llvm.ptr<array<40 x i8>>
%15 = llvm.getelementptr %14[0, 0] : (!llvm.ptr<array<40 x i8>>) -> !llvm.ptr<i8>
%16 = llvm.inttoptr %0 : i32 to !llvm.ptr<i8>
%17 = "disc_ral.dispatch"(%arg0, %16, %15, %c3_i32) {backend_config = "", call_target_name = "ral_const", device = "gpu", has_side_effect = false} : (!disc_ral.context, !llvm.ptr<i8>, !llvm.ptr<i8>, i32) -> memref<10xf32,
%reinterpret_cast = memref.reinterpret_cast %1 to offset: [0], sizes: [%dim, 10], strides: [10, 1] {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%alloc = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%18 = llvm.inttoptr %0 : i32 to !llvm.ptr<i8>
"disc_ral.dispatch"(%arg0, %18, %reinterpret_cast, %9, %alloc, %false, %false, %true) {backend_config = "", call_target_name = "ral_gemm", device = "gpu", has_side_effect = false} : (!disc_ral.context, !llvm.ptr<i8>, memref<?x10xf32,
memref.dealloc %9 : memref<10x10xf32,
%alloca = memref.alloca() {alignment = 64 : i64} : memref<2xindex>
memref.store %dim, %alloca[%c0] : memref<2xindex>
memref.store %c10, %alloca[%c1] : memref<2xindex>
%19 = arith.muli %dim, %c10 : index
%20 = arith.remui %19, %c4 : index
%21 = arith.cmpi eq, %20, %c0 : index
%alloc_0 = memref.alloc() : memref<f32,
%alloc_1 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%alloc_2 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%alloc_3 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%alloc_4 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
scf.if %21 {
"lmhlo.fusion"() ({
"lmhlo.constant"(%alloc_0) {disc.device = "gpu", value = dense<0.000000e+00> : tensor<f32>} : (memref<f32,
"lmhlo.dynamic_broadcast_in_dim"(%13, %alloca, %alloc_1) {broadcast_dimensions = dense<1> : tensor<1xi64>, disc.device = "gpu"} : (memref<10xf32,
"lmhlo.add"(%alloc, %alloc_1, %alloc_2) {disc.device = "gpu"} : (memref<?x10xf32,
"lmhlo.dynamic_broadcast_in_dim"(%alloc_0, %alloca, %alloc_4) {broadcast_dimensions = dense<> : tensor<0xi64>, disc.device = "gpu"} : (memref<f32,
"lmhlo.maximum"(%alloc_2, %alloc_4, %alloc_3) {disc.device = "gpu"} : (memref<?x10xf32,
"lmhlo.terminator"() : () -> ()
}) {disc.device = "gpu", disc.fusion.name = "main_kLoop_maximum__5_1_0", disc.fusion.tag = "Vec4", disc.fusion_type = "kLoop", disc_vectorize_or_tile_hint = 4 : i32} : () -> ()
} else {
"lmhlo.fusion"() ({
"lmhlo.constant"(%alloc_0) {disc.device = "gpu", value = dense<0.000000e+00> : tensor<f32>} : (memref<f32,
"lmhlo.dynamic_broadcast_in_dim"(%13, %alloca, %alloc_1) {broadcast_dimensions = dense<1> : tensor<1xi64>, disc.device = "gpu"} : (memref<10xf32,
"lmhlo.add"(%alloc, %alloc_1, %alloc_2) {disc.device = "gpu"} : (memref<?x10xf32,
"lmhlo.dynamic_broadcast_in_dim"(%alloc_0, %alloca, %alloc_4) {broadcast_dimensions = dense<> : tensor<0xi64>, disc.device = "gpu"} : (memref<f32,
"lmhlo.maximum"(%alloc_2, %alloc_4, %alloc_3) {disc.device = "gpu"} : (memref<?x10xf32,
"lmhlo.terminator"() : () -> ()
}) {disc.device = "gpu", disc.fusion.name = "main_kLoop_maximum__5_1_0", disc.fusion_type = "kLoop", disc_vectorize_or_tile_hint = 1 : i32} : () -> ()
}
memref.dealloc %alloc_4 : memref<?x10xf32,
memref.dealloc %alloc_2 : memref<?x10xf32,
memref.dealloc %alloc_1 : memref<?x10xf32,
memref.dealloc %alloc_0 : memref<f32,
memref.dealloc %alloc : memref<?x10xf32,
memref.dealloc %13 : memref<10xf32,
%alloc_5 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%22 = llvm.inttoptr %0 : i32 to !llvm.ptr<i8>
"disc_ral.dispatch"(%arg0, %22, %alloc_3, %5, %alloc_5, %false, %false, %true) {backend_config = "", call_target_name = "ral_gemm", device = "gpu", has_side_effect = false} : (!disc_ral.context, !llvm.ptr<i8>, memref<?x10xf32,
memref.dealloc %alloc_3 : memref<?x10xf32,
memref.dealloc %5 : memref<10x10xf32,
%alloc_6 = memref.alloc() : memref<f32,
%alloc_7 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%alloc_8 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%alloc_9 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
%alloc_10 = memref.alloc(%dim) {kDiscSymbolicDimAttr = [@S0, @C10]} : memref<?x10xf32,
scf.if %21 {
"lmhlo.fusion"() ({
"lmhlo.constant"(%alloc_6) {value = dense<0.000000e+00> : tensor<f32>} : (memref<f32,
"lmhlo.dynamic_broadcast_in_dim"(%alloc_6, %alloca, %alloc_7) {broadcast_dimensions = dense<> : tensor<0xi64>, disc.device = "gpu"} : (memref<f32,
"lmhlo.dynamic_broadcast_in_dim"(%17, %alloca, %alloc_8) {broadcast_dimensions = dense<1> : tensor<1xi64>, disc.device = "gpu"} : (memref<10xf32,
"lmhlo.add"(%alloc_5, %alloc_8, %alloc_9) {disc.device = "gpu"} : (memref<?x10xf32,
"lmhlo.maximum"(%alloc_9, %alloc_7, %alloc_10) {disc.device = "gpu"} : (memref<?x10xf32,
"lmhlo.terminator"() : () -> ()
}) {disc.device = "gpu", disc.fusion.name = "main_kLoop_maximum__5_1_1", disc.fusion.tag = "Vec4", disc.fusion_type = "kLoop", disc_vectorize_or_tile_hint = 4 : i32} : () -> ()
} else {
"lmhlo.fusion"() ({
"lmhlo.constant"(%alloc_6) {value = dense<0.000000e+00> : tensor<f32>} : (memref<f32,
"lmhlo.dynamic_broadcast_in_dim"(%alloc_6, %alloca, %alloc_7) {broadcast_dimensions = dense<> : tensor<0xi64>, disc.device = "gpu"} : (memref<f32,
"lmhlo.dynamic_broadcast_in_dim"(%17, %alloca, %alloc_8) {broadcast_dimensions = dense<1> : tensor<1xi64>, disc.device = "gpu"} : (memref<10xf32,
"lmhlo.add"(%alloc_5, %alloc_8, %alloc_9) {disc.device = "gpu"} : (memref<?x10xf32,
"lmhlo.maximum"(%alloc_9, %alloc_7, %alloc_10) {disc.device = "gpu"} : (memref<?x10xf32,
"lmhlo.terminator"() : () -> ()
}) {disc.device = "gpu", disc.fusion.name = "main_kLoop_maximum__5_1_1", disc.fusion_type = "kLoop", disc_vectorize_or_tile_hint = 1 : i32} : () -> ()
}
memref.dealloc %alloc_9 : memref<?x10xf32,
memref.dealloc %alloc_8 : memref<?x10xf32,
memref.dealloc %alloc_7 : memref<?x10xf32,
memref.dealloc %alloc_6 : memref<f32,
memref.dealloc %alloc_5 : memref<?x10xf32,
memref.dealloc %17 : memref<10xf32,
"disc_ral.dispatch"(%arg0, %c0, %alloc_10) {backend_config = "", call_target_name = "ral_send_output", device = "cpu", has_side_effect = false} : (!disc_ral.context, index, memref<?x10xf32,
return
}如上是整个代码段,该IR代码实现了一个包含两个全连接层(矩阵乘法)和ReLU激活函数的神经网络前向计算流程。具体数学表达式为:
output = ReLU(ReLU(input * W1 + b1) * W2 + b2)。同时由于BladeDISC的编译speculation,runtime选择机制,针对是否可以向量化(<?x10>的维度是否可以乘除4),做了多版本代码生成。
| Pass名称 | 功能描述 |
|---|---|
DiscLhloLegalizeRootsToParallelLoopsPass |
将LMHLO根操作转换为并行循环 |
InputInlineFusionPass |
内联融合生产者操作到循环中 |
(2) 后端特定优化
| Pass名称 | 功能描述 |
|---|---|
DiscLowerGpuOpsToNVVMOpsPass |
将GPU操作转换为NVIDIA CUDA后端操作 |
DiscLowerGpuOpsToROCDLOpsPass |
将GPU操作转换为AMD ROCm后端操作 |
DiscOutlineCpuKernelPass |
生成CPU多线程内核包装函数 |
(3) 内存访问优化
| Pass名称 | 功能描述 |
|---|---|
DiscFlattenMemrefAccessPass |
扁平化内存访问模式 |
DiscMemRefCSEPass |
消除冗余内存访问 |
7. GPU模块到二进制阶段
| Pass名称 | 功能描述 |
|---|---|
GpuKernelOutlining |
将gpu.launch分离为gpu.launch_func和gpu.module |
GpuKernelToBlobPass |
将LLVM IR编译为GPU二进制(CUBIN/HSACO) |
ReviseGpuKernelOutliningPass |
处理主机-设备内存参数传递 |
8. 主机侧编译阶段
| Pass名称 | 功能描述 |
|---|---|
DiscToLLVMPass |
将操作最终转换为LLVM Dialect |
DiscCpuMapParallelLoopPass |
将scf.parallel映射到CPU多线程执行 |
关键特征总结
| 阶段 | 核心目标 | 关键技术 |
|---|---|---|
| TF-to-HLO | 统一前端语义 | 静态秩约束处理 |
| HLO优化 | 形状传播与融合 | 代数简化与约束分析 |
| 缓冲化 | 内存管理 | 显式内存空间分配 |
| 运行时集成 | 跨平台抽象 | RAL上下文隔离 |
| 代码生成 | 动态形状代码生成 | 推测多版本内核生成 |
| 后端适配 | 硬件优化 | GPU循环映射与CPU多线程 |