在完成minitorch的task1部分的过程中,发现自己对于计算图以及自动反向求导仅仅停留在纸面公式上,难以转换为代码实现。本文章重点解读计算图的自动反向求导机制,从原理出发,最终分析minitorch中如何用代码实现该机制。
自动反向求导原理
这一部分主要参考Auto Differentiation slide。求导系统,可以分为前向求导和反向求导。
前向求导 vs. 反向求导
如下图所示是两种求导机制的对比:
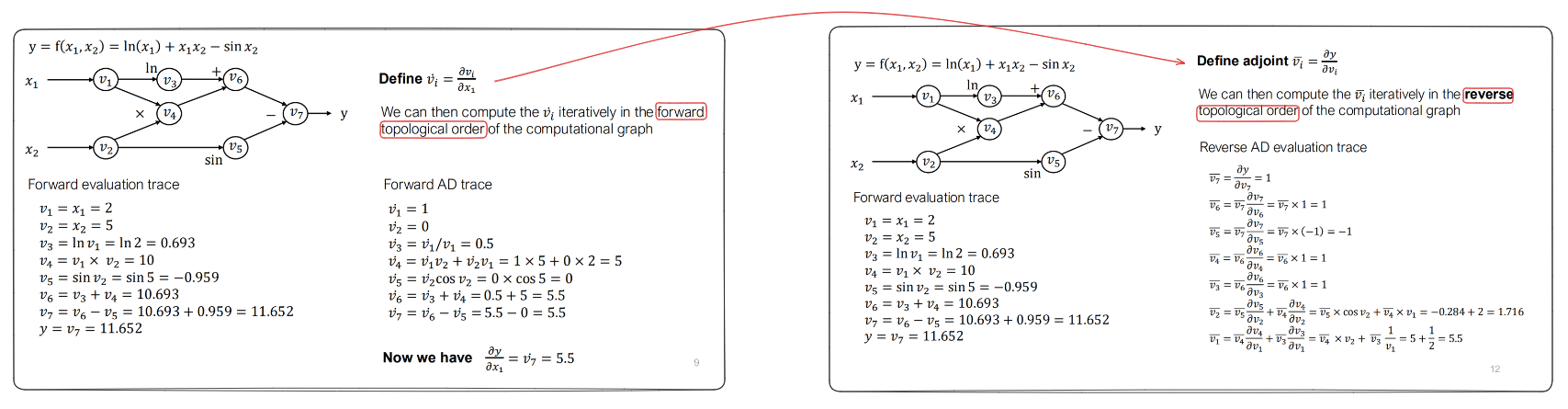
可以总结为两点:
- 传播顺序,一个是正向的拓扑序,一个是反向拓扑序。
- 计算的逻辑不一样,前向求导求的是中间结果关于叶子节点的偏导(符合数学计算逻辑),反向求导求的是结果节点关于中间结果的偏导(slide中称为伴随变量,表征某个中间结果对最终结果的偏导)。
仔细思考,反向求导相比前向求导最大的优势,是前向求导针对不同的变量,需要个走一个拓扑序完成求导过程,时间复杂度更高。并且,一般的计算图都是多输入少输出,因此反向求导相比前向求导计算量更小。
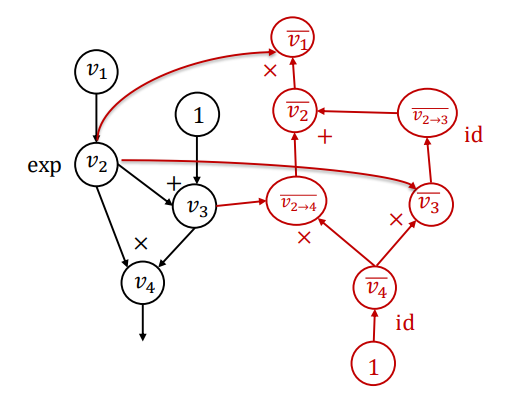
在反向求导的过程中,以上图为例,v2节点由于同时是v4和v5的输入,因此在求v2节点的伴随变量的时候,需要做加法运算来讲v4和v5的伴随变量一块传播。具体的数学理论支撑见下图:
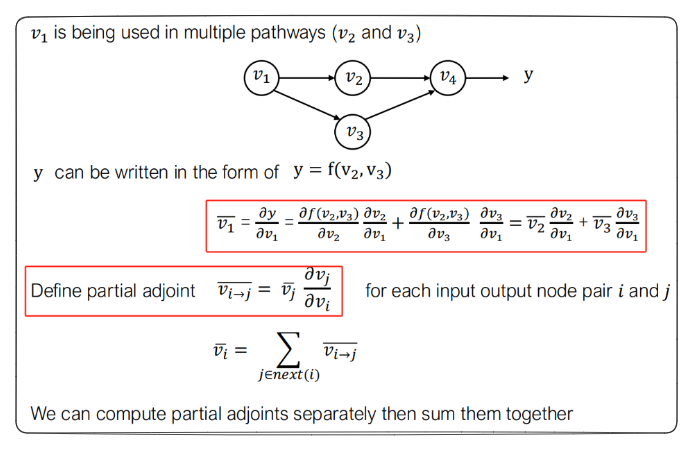
反向求导计算公式 & 反向计算图
这一小节主要讲两件事:反向求导的计算公式,以及实际的机器学习系统中,如何通过构造计算图的方式加速反向求导的效率。这两点是紧密结合的,前者为理论支撑,后者为工程实现。
计算公式

这个伪代码整体逻辑比较清晰,再次不过多赘述。
反向计算图
有了上述公式,我们需要思考实际工程中,怎样实现能够尽量高效。一种想法是结合partial disjoint手动计算,而目前常用的机器学习系统都是在正向传播的过程中(遍历正向图),同时构建一个反向传播图。
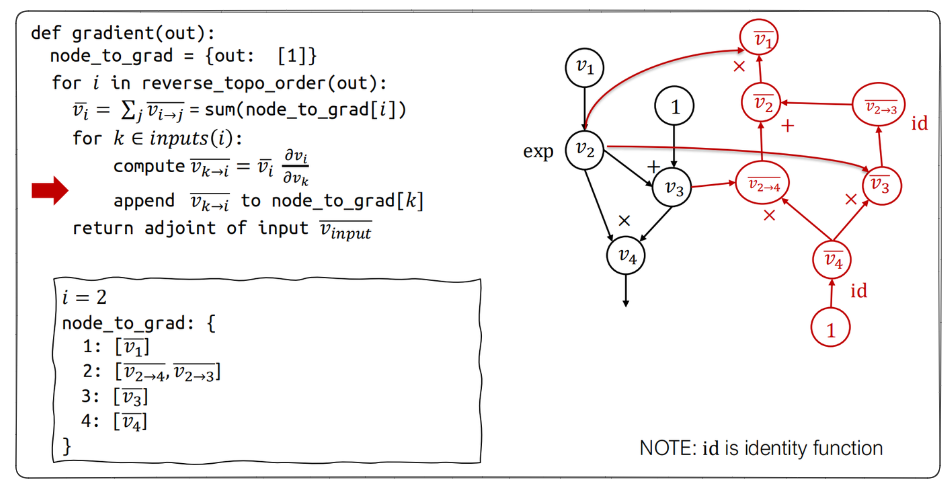
上图摘自Deep Learning System课程的slide,在课程中提供了一个完整示例,揭示如何在运行反向计算算法的同时,构建反向计算图。强烈建议读者参考学习该课程的反向求导章节加深理解。

上图摘自Pytorch Internal 博客,下面摘抄一些博客中的话辅助理解:
请花一点时间学习上面这张图。有一些东西需要展开来讲;下面列出了哪些东西值得关注:
- 首先请忽略掉那些红色和蓝色的代码。PyTorch实现了reverse-mode automatic differentiation (反向模式自动微分),意味着我们通过反向遍历计算图的方式计算出梯度。注意看变量名:我们在红色代码区域的最下面计算了loss;然后,在蓝色代码区域首先我们计算了grad_loss。loss 由 next_h2计算而来,因此我们计算grad_next_h2。严格来讲,这些以grad_开头的变量其实并不是gradients;他们实际上是Jacobian矩阵左乘了一个向量,但是在PyTorch中我们就叫它们grad,大部分人都能理解其中的差异。
- 即使代码结构相同,代码的行为也是不同的:前向(forwards)的每一行被一个微分计算代替,表示对这个前向操作的求导。例如,
tanh操作符变成了tanh_backward操作符(如上图最左边的绿线所关联的两行所示)。前向和后向计算的输入和输出颠倒过来:如果前向操作生成了next_h2,那么后向操作取grad_next_h2作为输入。
至此,我们来总结一下反向传播和自动求导反向传播(构建反向图)两种方式得优缺点。
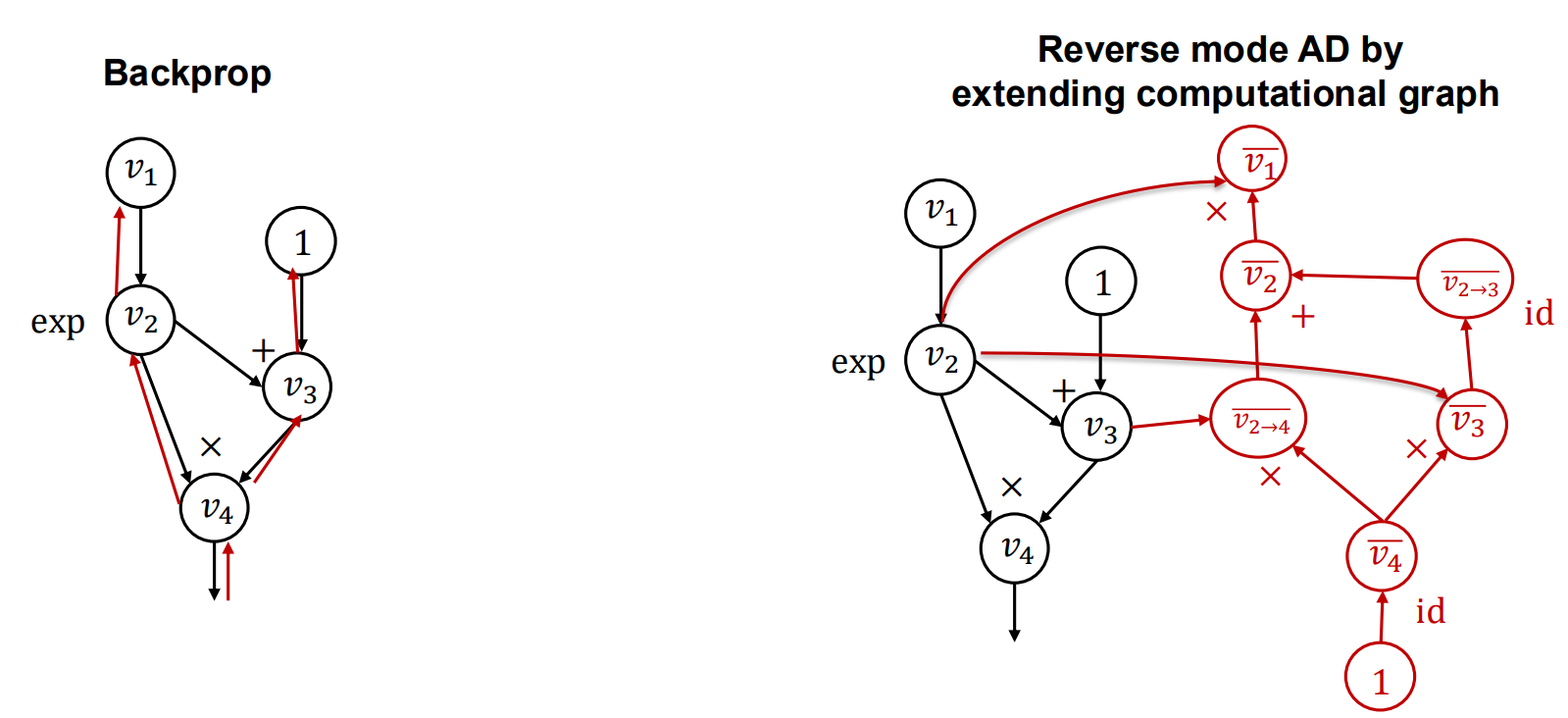
朴素的反向传播时间复杂度高(不同变量均需要遍历),但是图存储量小。而构建反向图图存储量会变大(反向节点:Partial Disjoint节点和Disjoint节点),但是只用跑一遍反向图即可完成所有计算,并且如果添加计算逻辑,可扩展性也更强。目前的主流机器学习框架:PyTorch,TensorFlow和JAX均使用反向图,朴素的反向传播可见于早期的Caffe系统中。
MiniTorch工程实现
这一部分主要是记录完成minitorch assign1过程中的学习心得。该实验仅仅是将Minitorch的反向传播系统最核心的组件挖空留给学生进行编写,如何完成这个实验可以参考minitorch 学习攻略。本章节重点解读minitorch的反向传播系统的架构设计。
本章节将按照如下逻辑展开:
- 类之间的关系和类的详细解读
- Pytorch内部机制
类的解读
在初阅读minitorch的底层代码,会迷失在眼花缭乱的各种类实现中。我们要去把握的,是自动反向求导过程中,最核心的功能是什么?在构造反向计算图中,我们需要知道一个值(output)是如何由输入(inputs)计算得到的,即需要跟踪函数内部计算,而这也是目前python系统无法支持的事情。因此本质上,minitorch的类系统设计,就是完成如下三件事:
- 用代理类(Variables)替换所有python值
- 把所有数学运算符替换为代理运算符(Functions)
- 把Variables功能增强以记住过去应用于它们的Functions
在assign1中,只是完成标量的反向求导系统,后续assign会扩展。因此本章节主要面向Scalar讲述。
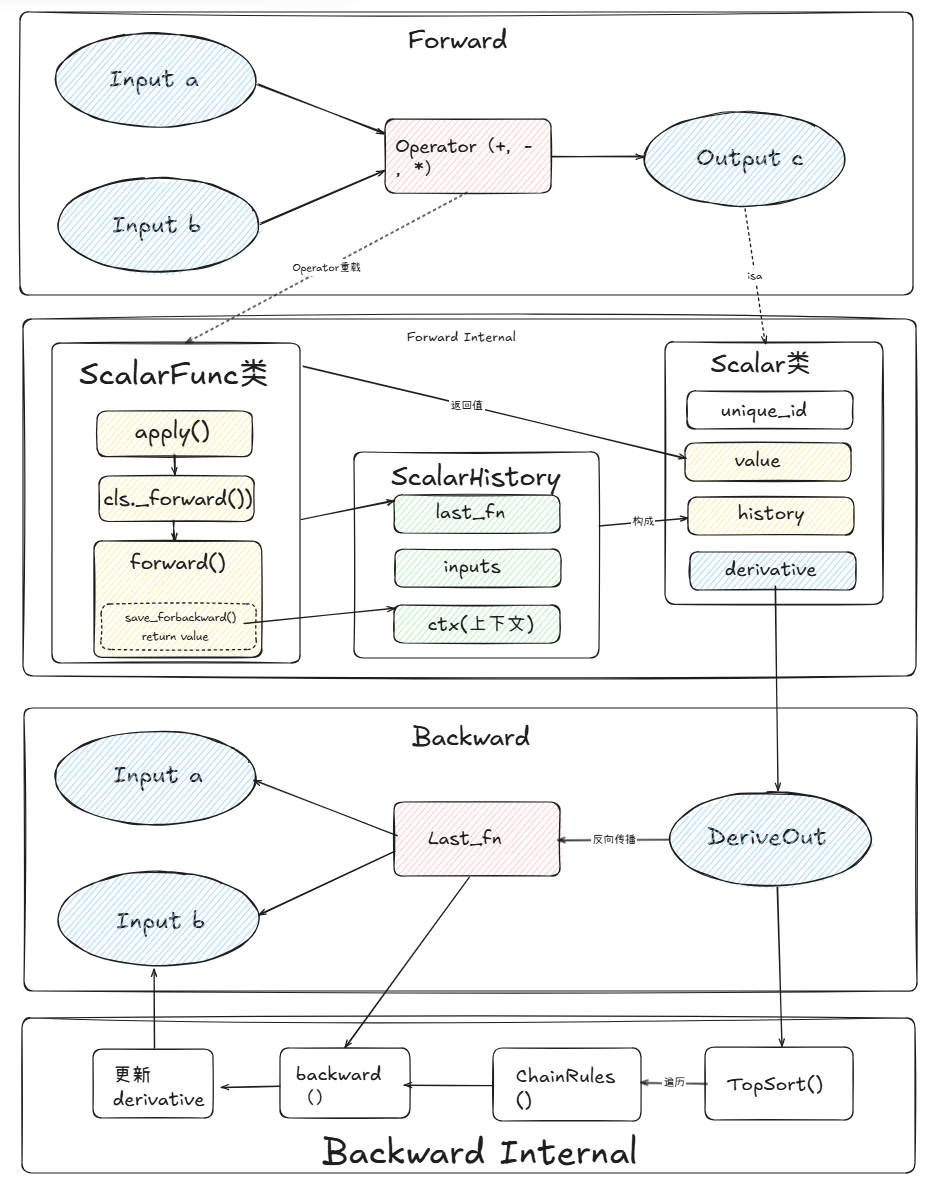
如上图所示,是整个minitorch的从前向计算到反向传播的一个完整的流程图。Scalar是代理类替换python值,ScalarFn替换数学运算法,包含forward和backward方法,辅助Scalar类的上下文记录环节。ScalarHistory类则是每个Scalar用来记录上下文的辅助类。整个流程是比较清晰的,结合流程图和源码可以方便理解全貌。
Pytorch的自动微分设计
由于Pytorch系统源码极其复杂,这里仅仅参考Pytorch Internal的talk,概括性分享自动微分设计,比对minitorch的具体实现学习。后续可能会开一篇文章着重讲解PyTorch系统,包括PyTorch2.0提出的一些新特性(TorchDynamo等)。
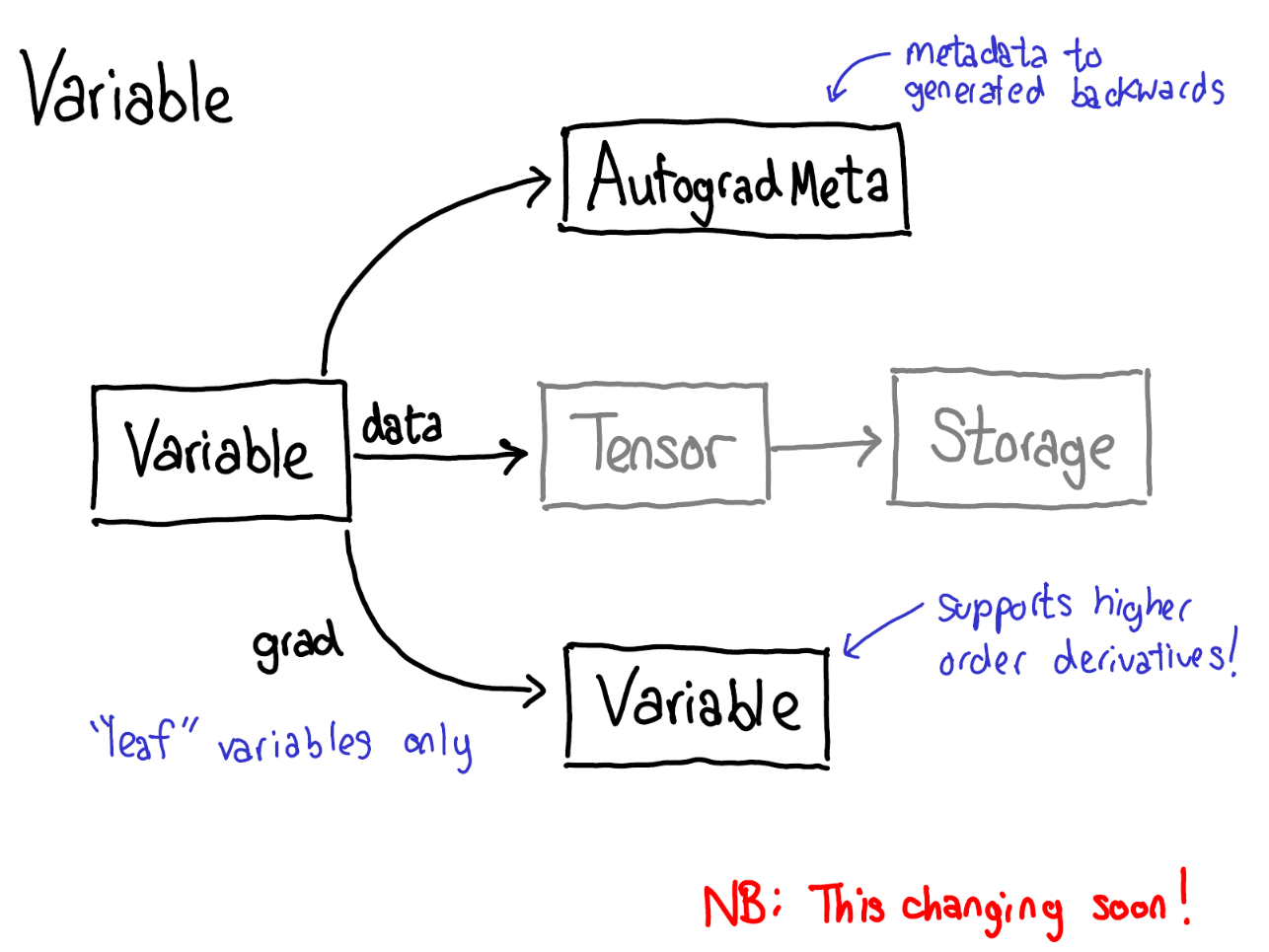
当我们在tensor上调用各种operations的时候(forward前向过程),一些元数据(metadata)也需要被记录下来。让我们调整一下tensor数据结构的示意图:现在不仅仅单单一个tensor指向storage,我们会有一个封装着这个tensor和更多信息(自动微分元信息(AutogradeMeta))的变量(variable)。这个变量所包含的信息是用户调用loss.backward()执行自动微分所必备的。