本篇博客重点阐述MLIR的自动向量化技术的原理,并结合实际项目(如IREE项目)探索实现细节。
MLIR Vector dialect引言
这一部分讲清楚亮点:
- vector dialect在整个pipeline的位置
- vector dialect的逐层抽象下降逻辑
首先,我们需要明晰vector dialect在一个端到端编译器的lower过程中,所处的位置。

由上图所示,vector dialect一般在affine和linalg dialect之后,在LLVM等底层dialect之前。此时编译器已经完成了高层的一些算子优化:多面体优化,tiling优化,循环融合优化,在vector层面则主要完成数据并行优化(主要针对SIMD架构做优化)。
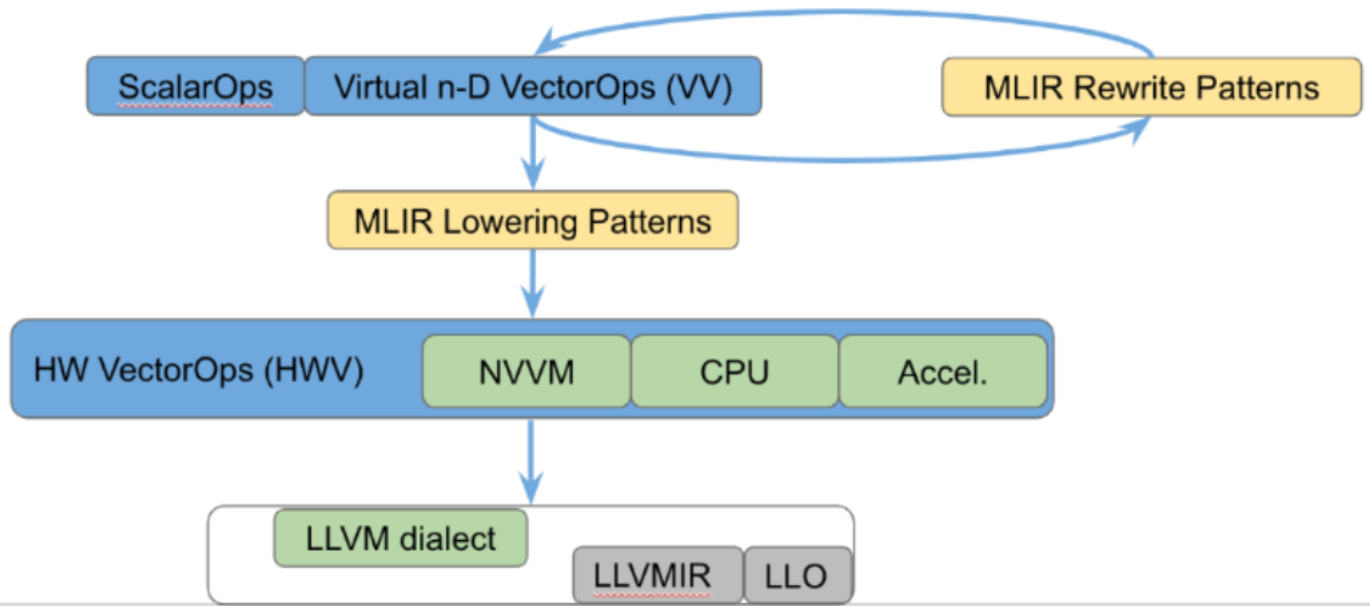
在vector dialect的内部,也可以进行分层划分,主要逻辑是自底向上,从指令层级(LLVMIR)到硬件强相关操作(NVVM dialect)到虚拟硬件无关操作三个层级。具体的例子如下图所示:

在高层的虚拟vector dialect中,和硬件无关,适合完成自动并行化等优化。然后通过MLIR的pattern rewrite机制逐层转换成硬件相关向量。以CUDA为例,MLIR社区提供NVVM dialect,可以抽象cuda的tensor core操作,编译器可以尝试将虚拟向量转为tensor core向量处理。最终将硬件相关vector转为LLVM做代码生成。
设计思考
向量化粒度思考
首先,我们要思考在高层vector逐层转向LLVM IR的过程中,其vector的粒度由什么决定。整个vector系统的设计逻辑是要将高层vector逐层转换为可以在硬件上高效利用数据并行的指令,因此最小粒度由硬件决定。该最小粒度在硬件相关vector层级就会暴露出来:

对于非最小粒度的倍数的vector,要么在高层转换成功,要么损失性能,或是在一些特定硬件会直接不合法而导致编译失败。
这一部分其实也是vectorization优化的一个重难点,如何针对硬件进行合理的向量化优化。后续会围绕这一点重点分析已有的编译器的硬件相关向量化。
Automatic Vectorization
不同于前面对于向量化降级粒度的思考,这一部分主要讨论如何将标量转换为向量表示。自动向量化的核心思想是,从一段代码中提取出结构化信息(数据并行性)并重组,本质是lowering的反面:raising操作。由于MLIR的多层级结构,因此自动向量化一般在linalg等高层ir就完成,而非affine层循环表示中完成,这样可以节省大量开销和优化复杂度。这一部分后续会结合代码详细解读。
Lowering to LLVM tradeoff
在LLVM中,其ir只支持1-D vector,因此需要将高层mlir vector降级到1-D vecctor。该过程有如下选项:

一般选择最内维做flatten,方便simd优化,外维选择嵌套类型。
明白我们有哪些选择后,下一步是理解LLVM的vector有什么约束条件,在原文中大概翻译如下:
LLVM对多维向量的限制
- 原生仅支持1D向量:LLVM的向量操作(如
extractelement、insertelement、shufflevector)直接支持动态索引,但仅适用于1D向量。- 聚合类型的静态性:多维向量需降维为聚合类型(如结构体或数组),但相关操作(
extractvalue/insertvalue)仅允许静态索引,动态索引需通过内存指针(getelementptr)间接实现,效率较低。
MLIR中的两种实现方案
方案一:嵌套聚合(Nested Aggregate)
原理:将n维向量编码为多层嵌套的1D向量(如
vector<4x8x16x32xf32>视为[4 x [8 x [16 x <32xf32>]]])。优点:
- 保留维度层次,无需额外线性化逻辑。
- 静态索引操作(如提取子向量)天然适配硬件寄存器结构。
缺点:
- 动态索引非最内层维度时,需将数据写入内存再通过指针操作,性能损耗大。
- 无法直接使用LLVM针对1D向量的优化指令(如SIMD指令)。
方案二:扁平化1D向量(Flattened Vector)
- 原理:将n维向量展平为单一大尺寸1D向量(如
vector<4x8x16x32xf32>转为vector<4 * 8 * 16 * 32=16384xf32>)。- 优点:
- 支持全维度动态索引(
insertelement/extractelement)。- 兼容LLVM的1D向量优化指令和硬件指令。
- 缺点:
- 引入复杂线性化/反线性化逻辑,代码生成复杂度高。
- 掩盖实际硬件向量边界(如固定128位SIMD),可能导致非对齐访问或低效向量拆分。
核心权衡:抽象灵活性与硬件效率
- 嵌套聚合更贴近硬件物理结构(如多级寄存器),利于静态代码优化,但牺牲动态索引能力。
- 扁平化向量提供编程灵活性,但需在代码生成阶段隐式处理维度映射,可能阻碍硬件针对性优化。
折中方案
通过显式维度转换操作(如
vector.cast)按需展平部分维度,例如将vector<4x8x16x32xf32>局部转为vector<4x4096xf32>,既保留外层静态索引优化空间,又允许内层使用动态索引或SIMD指令。
上述关于extractvalue操作不支持动态索引这点,刚开始会感觉比较难以理解。其本质原因是现代处理器(CPU/GPU)的寄存器文件(Register File) 是硬件直接操作的超高速存储单元,访问索引的时候存在物理设计约束:
- 固定寄存器数量:每个线程/核心可用的寄存器数量是硬件固定的(如NVIDIA GPU每个线程最多255个寄存器)。
- 静态寄存器分配:寄存器在编译时由编译器分配,操作寄存器的指令直接编码寄存器编号(如
R0,R1)。 - 无动态索引支持:硬件指令无法通过运行时变量选择寄存器(如无法生成
MOV R%idx, 42这样的指令)。
由于上述三个物理设计约束,寄存器难以支持动态索引,也导致嵌套聚合的动态索引局限。将眼光从mlir编译放远来看,其实众多编程模型对于寄存器的动静态问题早有讨论:
通过循环展开,化动态为静态。
split memory,内存可以动态索引,但是带来访存开销问题。
vector实际实现机制
Implication on codegen
MLIR的n维向量类型在降级到LLVM时被表示为(n-1)维数组包裹的1维向量,这导致静态索引和动态索引的分层限制:仅最内层1维向量支持动态索引(通过insertelement/extractelement),外层(n-1)维只能静态访问,否则需显式内存操作(load/store)。代码生成需权衡循环展开与内存访问,动态索引需通过内存指针实现,而硬件寄存器分配和溢出问题则推迟到LLVM后端处理,MLIR层通过抽象成本模型指导优化选择。
Implication on Lowering to Accelerators
针对支持高维向量的加速器,MLIR通过vector.cast将最内层维度展平为1维向量(如vector<Kxf32>),直接对接LLVM-IR或加速器特定指令。这一过程需在加速器专用方言中定制转换规则,例如处理不规则维度时的掩码或数据重组逻辑,而标准化的展平操作(如K=K1*K2*…*Kn)近乎无开销。目标是实现跨CPU/GPU/加速器的统一代码生成框架,通过模式重写和成本模型灵活适配硬件特性。
这一条在各种机器学习编译器中都有大量代码实现
Implication on calling external functions that operate on vectors
调用外部向量函数时,可能需要线性化多维向量以匹配ABI接口。MLIR需在调用边界隐式插入维度转换逻辑,确保数据布局与目标函数兼容。例如,将vector<4x4xf32>转为连续内存块或1D向量,避免因多维结构导致调用约定冲突。
Relationship to LLVM matrix type proposal
LLVM矩阵提案(支持2D矩阵及专用指令)与MLIR多维向量设计存在互补性。MLIR更高维的通用向量抽象可降级为LLVM矩阵或原生1D向量,而MLIR的vector.cast机制为CPU/加速器提供了统一接口。未来MLIR可能成为跨硬件向量化策略的枢纽层,LLVM矩阵则作为特定场景的子集实现。
Conclusion
**MLIR选择“嵌套聚合1D向量”作为核心抽象,因其明确区分内存与寄存器语义,同时通过vector.cast兼容硬件特定指令。**这种设计支持粗粒度向量操作(如跨多硬件向量的模式匹配),并通过显式维度转换平衡灵活性与性能,而非依赖LLVM隐式线性化。尽管LLVM矩阵提案适合硬件专用场景,MLIR的高维模型更适配跨平台代码生成需求,成为连接算法与硬件优化的桥梁。
向量化流程
主要参考Lei chat blog。下述内容大量摘自博客以及一些个人总结。


上图是vetorization的流程图。对于每一步,可以参考Spirv的向量化处理源码。
