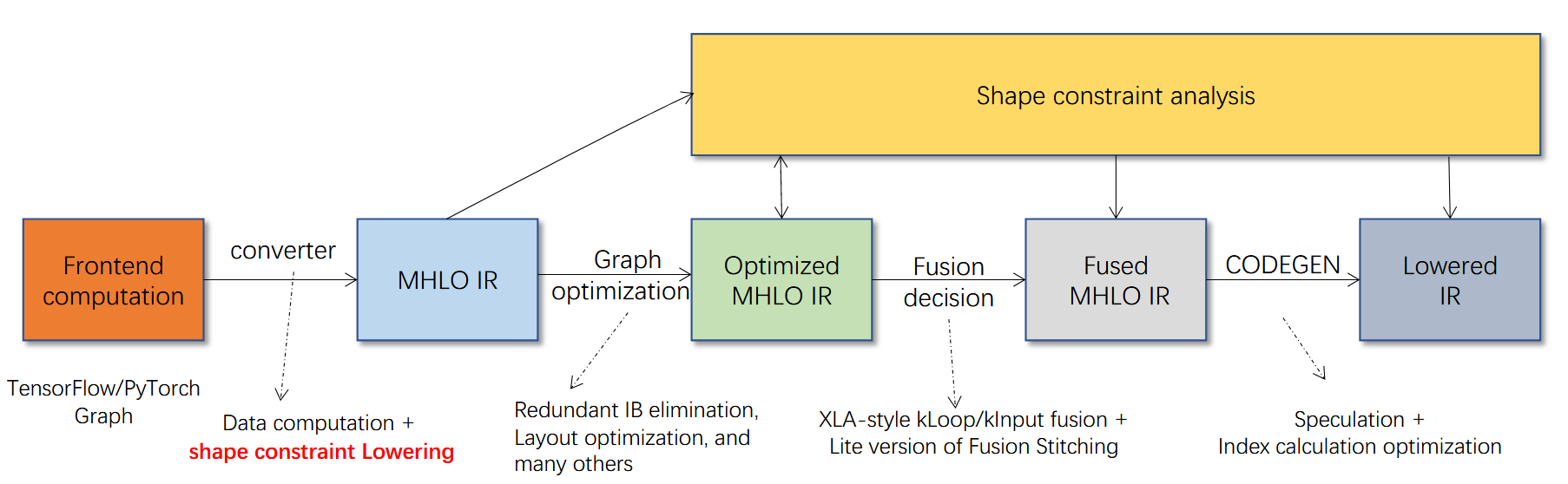
在大模型训练推理场景中,一个十分大的瓶颈是动态shape问题。比如nlp领域,处理的句子长短不一,tensor的shape是动态变化的,到runtime才能确定。这给机器学习编译器带来很大的困扰,以XLA为首的sota编译器均是静态shape的,在性能上会有一定损失。BladeDISC是阿里提出的针对动态shape的机器学习编译器,并且经过大量实验和实际生产检验。本文重点关注BladeDISC的构建,pytorch使用方式以及基础架构解读。后续文章会讲解优化流程和论文解读。
源码构建
Build from source
下载BladeDisc镜像
1
docker pull bladedisc/bladedisc:latest-devel-cu118
- 使用cu118版本
运行该镜像
1
docker run --gpus all -it -v $PWD:/disc bladedisc/bladedisc:latest-devel-cu118 bash
修改一下
pytorch_blade/scripts/build_pytorch_blade.sh里面的TORCH_BLADE_CI_BUILD_TORCH_VERSION。修改为存在的requirements.txt即可。构建过程中,onnx由于带宽等问题,可能会报error,添加-i https://pypi.tuna.tsinghua.edu.cn/simple指定pypi镜像即可。
pytorch版本构建
1
2
3cd pytorch_blade && bash ./scripts/build_pytorch_blade.sh
python setup.py bdist_wheel
pip install ./pytorch_blade/dist/torch_blade-0.2.0+2.0.1.cu118-cp38-cp38-linux_x86_64.whl
错误处理
如果报错没有安全git,在docker中用:
1 | git config --global --add safe.directory /disc |
quick install
Pytorch部署BERT模型
Hugging Face模型下载
手动下载模型(适合服务器联网不稳定的情况使用)
找到Bert sentiment inference 模型,主要手动下载如下几个文件:
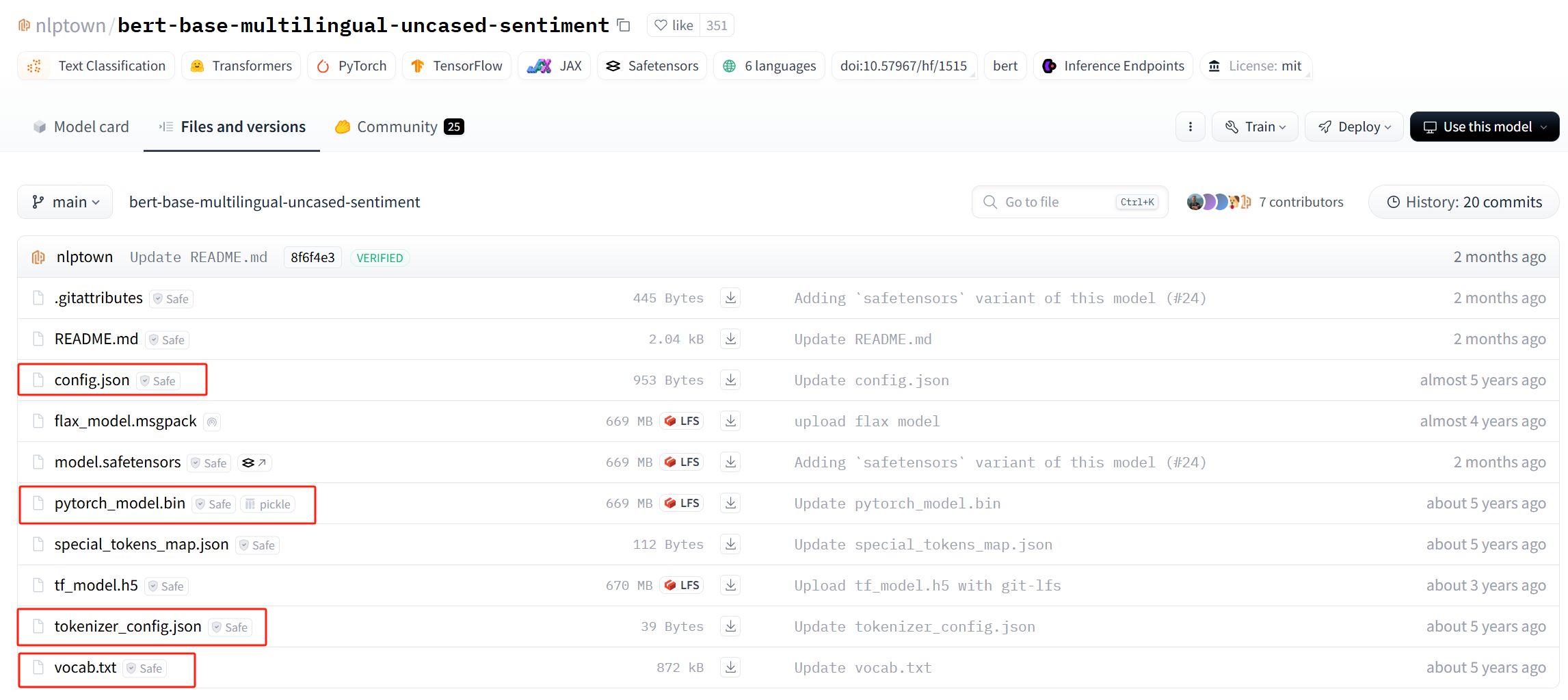
在python代码中使用离线下载的模型:
1
2
3model_path = "./model"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path).cuda().eval()直接通过transformers 包下载,该下载方式通过huggingface对应模型网页的
use this model获取1
2
3
4
5# Load model directly
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")
model = AutoModelForSequenceClassification.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")确保环境有transformers包即可
通过
huggingface-cli下载1
huggingface-cli download nlptown/bert-base-multilingual-uncased-sentiment
做BERT Inference的testbench
我的测试codes如下:
1 | import torch |
上述codes中,BladeDISC的核心如下:
1 | with torch.no_grad(), torch_config: |
通过编译手段,生成优化后的pytorch script,注意:目前pytorch仅仅支持inference,尚不支持train。对于HuggingFace模型的pipeline有更深层兴趣的,参考HuggingFace quick tour。

可以看到对比pytorch,有1.7倍左右的加速。
Pytorch WorkFlow

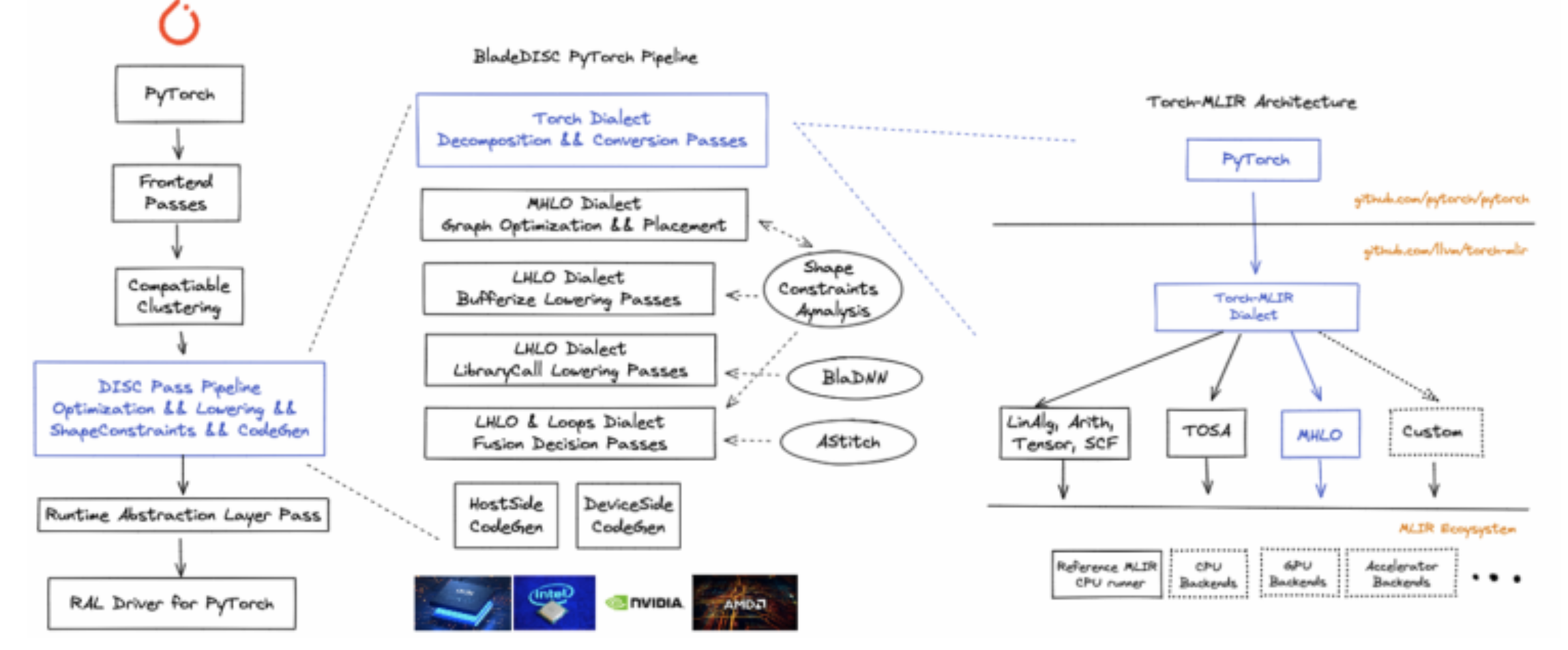
参考Torch-Blade教程即可。