这是算子优化系列的第一篇,主要聚焦于存储密集型算子的融合优化。探讨这一主题的动机源于 BladeDISC 编译器,这个由阿里云开发的编译器专注于解决动态 shape 问题,并在大模型业务中实现了显著的优化。BladeDISC 的一大亮点是复用了 astitch 论文中提出的多元访存算子融合方法,因此,本文将对这一问题展开深入讨论,从两方面来分析:XLA传统融合和BladeDISC使用的stich融合。
XLA代码解析
在阿里的bladedisc的ppt中,可以看到如下总结:
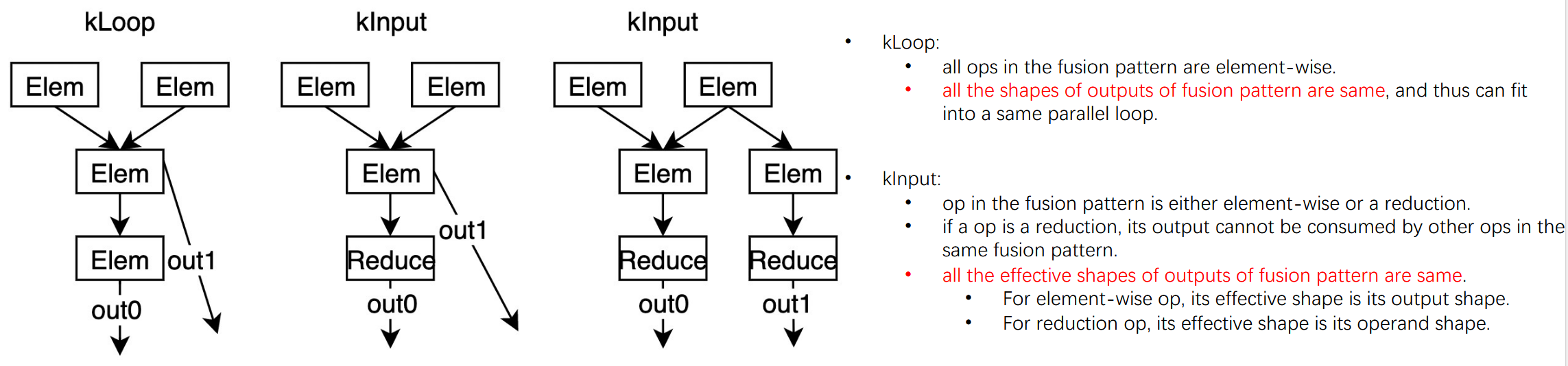
先考虑从mlir-hlo项目入手,理解xla alike的fusion是如何做的。具体代码在mhlo_fusion.cc中。上述图片其实已经总结了XLA可以做的两种kernel fusion方式:KLoop和KInput。可以看出,XLA还是重点关注的算子pattern是比较简单的。
Source Code源码分析
核心原理是通过形状约束分析和图论中的边收缩算法,动态识别可融合的操作组,并生成高效的融合计划。
形状约束是阿里团队提出的动态shape约束。
该代码是典型的两阶段code,第一阶段分析出fusion plan,第二阶段应用fusion plan做相应的fusion:
1 | void runOnOperation() override { |
上述代码段时整个pass的入口,也是整体流程控制。
FusionPlanner planner(op_list)针对一个block的oplist,初始化一个fusion plan。planner.Run()根据planner构建的图,做子图划分,生成潜在的fusion pattern集和。ApplyFusionPlan为第二阶段,将fusion pattern list用于代码改写,完成最终的fusion操作。
接下来分别展开这三个函数。
基础知识
下面先来介绍一些辅助函数:
首先,先明确
XLA Fusion的几个基本数据结构概念:1
2using FusionPattern = std::vector<Operation*>;
using FusionPlan = std::vector<FusionPattern>;FusionPattern是可融合的operation集和。FusionPlan是FusionPattern集和。
XLA针对memory-intensive的算子,主要考虑如下两个算子:ReduceOp和element-wiseOp。分别有如下可能的融合方案:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// reduceOp主要判断,其operand的define point的op是否shape相同
// 如果相同,reduceOp考虑的模式是operand融合
bool IsFusibleWithOperand(Operation* op) {
// 相比IsFusibleWithConsumer,支持reduce op
return IsMhlo(op) &&
(op->hasTrait<::mlir::OpTrait::Elementwise>() || isa<ReduceOp>(op));
}
// element-wise操作或是常量操作,可以考虑是否可以和consumer融合
bool IsFusibleWithConsumer(Operation* op) {
// 必须是MHLO操作,并且是elementwise操作,或是常量操作
return IsMhlo(op) && (op->hasTrait<::mlir::OpTrait::Elementwise>() ||
matchPattern(op, m_Constant()));
}
// 全局的isFusible判断
bool IsFusible(Operation* op) {
// 只有常量操作或是能和consumer融合的操作才是可融合的,或是能和operand融合的操作
return matchPattern(op, m_Constant()) || IsFusibleWithConsumer(op) ||
IsFusibleWithOperand(op);
}针对
FusionPattern和其他block的交互:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54SmallVector<Value, 4> GetInputsOfFusionPattern(const FusionPattern& pattern) {
SmallVector<Value, 4> inputs;
DenseSet<Value> input_set;
DenseSet<Operation*> op_set;
// 收集一个fusion pattern里的所有operation
for (Operation* op : pattern) {
bool inserted = op_set.insert(op).second;
(void)inserted;
assert(inserted && "FusionPattern contains duplicate operations");
}
for (Operation* op : pattern) {
for (Value operand : op->getOperands()) {
Operation* operand_op = operand.getDefiningOp();
// 如果defining op在pattern里,则跳过
// 否则加入到inputs中,表示是该潜在的fusion pattern的输入
if (op_set.find(operand_op) != op_set.end()) {
// skip if defining op is in the pattern
continue;
}
if (input_set.insert(operand).second) {
inputs.push_back(operand);
}
}
}
return inputs;
}
// 收集融合操作中所有被外部使用的输出,作为融合后的输出
SmallVector<Value, 4> GetOutputsOfFusionPattern(const FusionPattern& pattern) {
SmallVector<Value, 4> outputs;
DenseSet<Operation*> op_set;
for (Operation* op : pattern) {
// 检查是否有重复的operation
bool inserted = op_set.insert(op).second;
(void)inserted;
assert(inserted && "FusionPattern contains duplicate operations");
}
// 尝试做融合的operation
for (Operation* op : pattern) {
for (Value result : op->getResults()) {
// 判断该operation是否result有被外部使用
bool has_external_user = llvm::any_of(
result.getUses(),
[&](OpOperand& use) { return !op_set.count(use.getOwner()); });
// 显示收集被外部使用的output
if (has_external_user) {
outputs.push_back(result);
}
}
}
return outputs;
}上述两个函数支持获取FusionPattern的外部输入和输出。
合并两个
FusionPattern,这个函数比较重要,其实就是发现可以合并融合的operation list,扩大单个fusion region:1
2
3
4
5
6FusionPattern MergeFusionPattern(const FusionPattern& lhs,
const FusionPattern& rhs) {
FusionPattern pattern(lhs);
pattern.insert(pattern.end(), rhs.begin(), rhs.end());
return pattern;
}并查集用于做shape推导,注意,XLA的fusion中,shape 推导是比较简单的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64class ShapeConstraintAnalysis {
public:
explicit ShapeConstraintAnalysis(const SmallVectorImpl<Operation*>& op_list) {
PropagateEquality(op_list);
}
// Returns true is `lhs` and `rhs` are supposed to have same shape.
bool HasSameShape(Value lhs, Value rhs) {
// 单纯判断两者在unionfind中的位置是否相同
return impl_.isEquivalent(ValueWrapper(lhs), ValueWrapper(rhs));
}
private:
// shape equality propagation based on the shape constrains of
// elementwise ops.
// 针对elementwise操作,做shape相等传播
void PropagateEquality(const SmallVectorImpl<Operation*>& op_list) {
bool converged = true;
do {
converged = true;
// 显示对两个value做unionfind
auto update = [&](Value lhs, Value rhs) {
if (!impl_.isEquivalent(ValueWrapper(lhs), ValueWrapper(rhs))) {
// 有更改,说明还没有完全收敛
converged = false;
impl_.unionSets(ValueWrapper(lhs), ValueWrapper(rhs));
}
};
for (Operation* op : op_list) {
// 只对有InferShapeEqualityOpInterface trait的operation做shape相等传播
auto op_fusibility = dyn_cast<InferShapeEqualityOpInterface>(op);
if (!op_fusibility) continue;
int numInput = op->getNumOperands();
int numOutput = op->getNumResults();
// shape equality propagation between inputs.
for (int input1 = 0; input1 < numInput; ++input1)
for (int input2 = input1 + 1; input2 < numInput; ++input2)
// 通过op_fusibility.inferInputsShapeEquality函数判断两个input是否shape相等
if (op_fusibility.inferInputsShapeEquality(input1, input2))
update(op->getOperand(input1), op->getOperand(input2));
// shape equality propagation between outputs.
for (int output1 = 0; output1 < numOutput; ++output1)
for (int output2 = output1 + 1; output2 < numOutput; ++output2)
// 同理,判断两个output是否shape相等
if (op_fusibility.inferOutputsShapeEquality(output1, output2))
update(op->getResult(output1), op->getResult(output2));
// shape equality propagation between input and output.
for (int input = 0; input < numInput; ++input)
for (int output = 0; output < numOutput; ++output)
// 最关键的步骤,判断input和output是否shape相等
if (op_fusibility.inferInputOutputShapeEquality(input, output))
// 如果相等,则调用lambda函数,将两者做unionfind
update(op->getOperand(input), op->getResult(output));
}
} while (!converged);
}
// a UnionFind set
// 使用LLVM提供的内置UF集和
EquivalenceClasses<ValueWrapper> impl_;
};
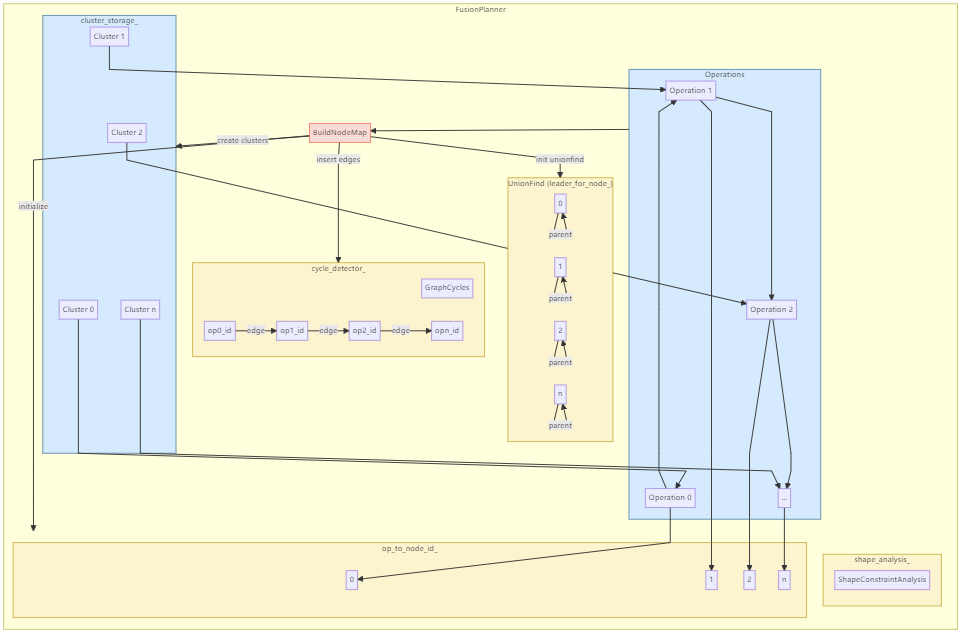
planner的初始化
FusionPlanner的初始化逻辑是比较简单的:
1 | class FusionPlanner { |
主要干了如下事情:
- 初始化op_list_,用于后续的fusion
- 初始化shape_analysis_工具,用于知道fusion的shape compatible analysis
- 初始化cycle detector,
XLA的fusion中,一个条件是不能引入loop
最后构建一个nodemap,构建一个cluster图,用于后续子图生成,op遍历。
成员变量如下:
1 | const SmallVectorImpl<Operation*>& op_list_; |
构建图的逻辑如下:
1 | void BuildNodeMap() { |
- 遍历每一个op,在unionfind中,每一个op为一个cluster,后续fusion操作才会融合cluster。
- 初始化op_to_node_id_等的映射方式,unionfind中存储的是该op的node_id,即在当前fusionplan中的次序号。
- operand的define op和当前op,在cycle_detector中显示插入依赖链条。
上述整体逻辑是十分清楚的。
在FusionPlanner中,有一个私有类是Cluster:
1 | // Represent a (partial) fused pattern |
上述cluster最主要的功能,就是可以对于cluster中的operation,显示记录他们可以应用的FusionPattern。同时还支持merge操作,将cluster之间进行fusion。该原理是将另一个cluster的pattern拷贝入当前cluster,并清空另一个cluster的pattern。
planner运行
核心部分,主要作用是构建cluster融合,并给对应cluster赋予fusion pattern。
主函数如下:
1 | // Returns a fusion plan if success, otherwise none. |
这里需要理解一个重要的点:每一个cluster都有一个list,该list存储所有的fusion Pattern,一个cluster是否可以做融合,其实就是看发现了多少个fusion Pattern。
- 如果fusion pattern > 1,则其内部可以融合。
- 如果cluster之间有兼容的fusion pattern,则intra cluster 融合是ok的。
识别出潜在的fusion后,构造fusion plan:一个fusion pattern的vector存储结构。
上述code可以分为两大阶段:RunEdgeContractionLoop()和融合pattern收集。
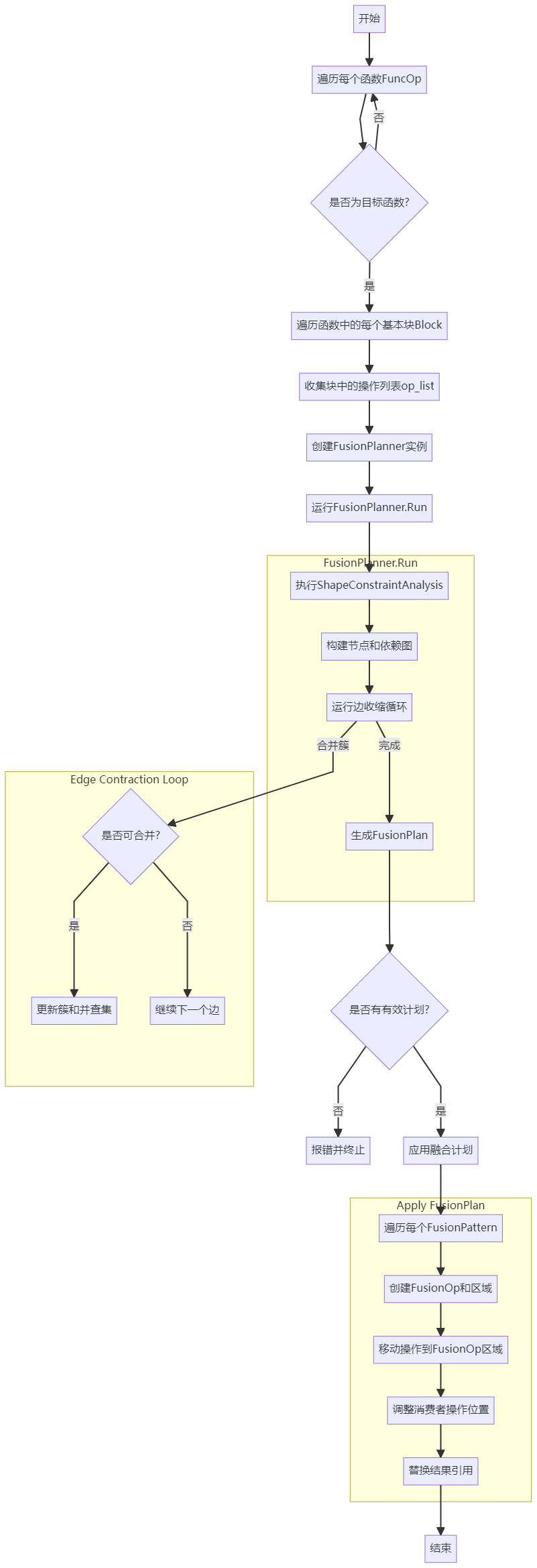
上述是一个完整的流程图。可以看出,run()函数最重要的function是RunEdgeContractionLoop()。
1 | // Greedily fuse connected node. |
对于graph做后序遍历,并贪心引用边收缩算法。
1 | // 按照后序遍历的顺序,对每一个edge执行fn函数 |
该逻辑是,后续访问每个node,并尝试对后续的每个op尝试引用fn函数,即TryToContractEdge函数。
1 | // This function check if fusing `from` with `to` is valid and if so perform |
注意,如果op是reduceOp,则其只能是to,不能是from,所以reduceOp一定在sub graph的end point。
判断from和to是否可fuse:isfusable()
GetResultsOfFusedPattern:1
2
3
4
5
6
7// returns the outputs if two cluster were merged
SmallVector<Value, 4> GetResultsOfFusedPattern(Cluster* from, Cluster* to) {
// 将两个cluster的fused_pattern合并
FusionPattern fused_pattern =
MergeFusionPattern(from->fused_pattern(), to->fused_pattern());
return GetOutputsOfFusionPattern(fused_pattern);
}尝试强行融合两个cluster的pattern,并获取一个fusion厚的output。
显示做shape 判断,来判断前一步的fusion是否是合法的:
1
2
3
4
5
6
7Value ref = InferEffectiveWorkloadShape(results[0]);
if (!llvm::all_of(results, [&](Value result) {
Value val = InferEffectiveWorkloadShape(result);
return shape_analysis_.HasSameShape(ref, val);
})) {
return false;
}这个inferworkload逻辑如下:
1
2
3
4
5
6
7
8
9// 根据value的类型,判断workload的shape的推导方式
// 主要针对reduce op做特殊化处理
Value InferEffectiveWorkloadShape(Value v) {
Operation* op = v.getDefiningOp();
// 如果是reduce op,则返回operand的shape
// 否则,v本身用于推导shape
return isa_and_nonnull<ReduceOp>(op) ? op->getOperand(0) : v;
}取融合后第一个输出的“有效工作负载形状”作为参考。
对普通操作,有效形状即输出本身的形状;对
ReduceOp,有效形状是操作数的形状(因为融合需基于其输入数据的形状)。对融合后的所有输出结果,逐一检查它们的有效形状是否与参考形状一致。
若存在任意一个输出形状不匹配,返回
false,拒绝合并。
这背后的原理如下:
kLoop 融合:要求所有输出形状一致,以放入同一并行循环。
kInput 融合:
允许包含
ReduceOp,但其有效形状需与其他输出的有效形状一致(即ReduceOp的输入形状需与其他输出形状一致)。例如,若融合模式包含一个reduceOp和elementwiseOp,做如下操作:ReduceOp的有效形状是其输入(操作数)的形状。ElementWise的有效形状是其输出的形状。两者必须相同才能融合。
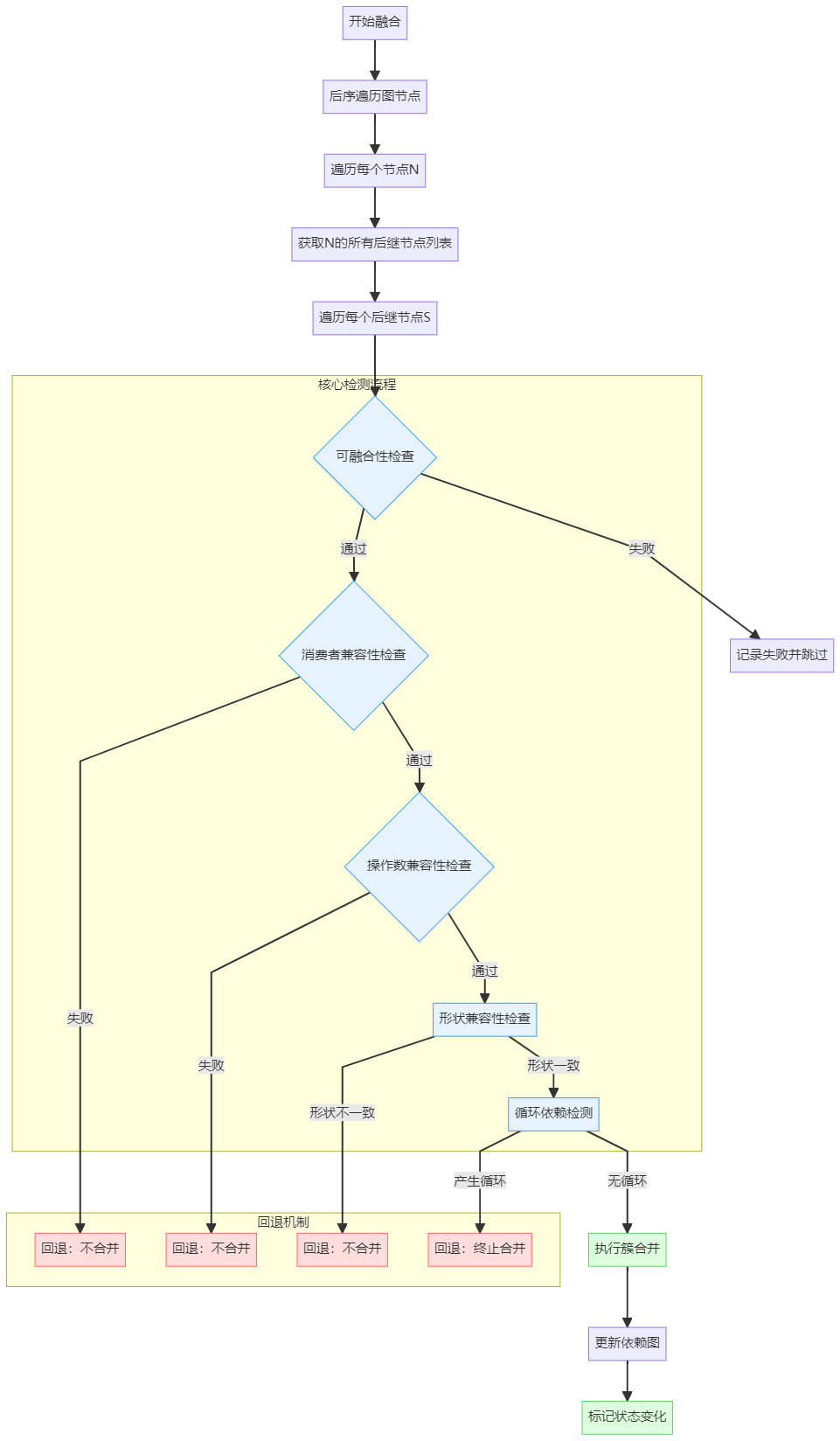
ApplyFusionPlan
源码如下:
1 | bool ApplyFusionPlan(const FusionPlan& plan) { |
如下是ApplyFusionPlan的流程图
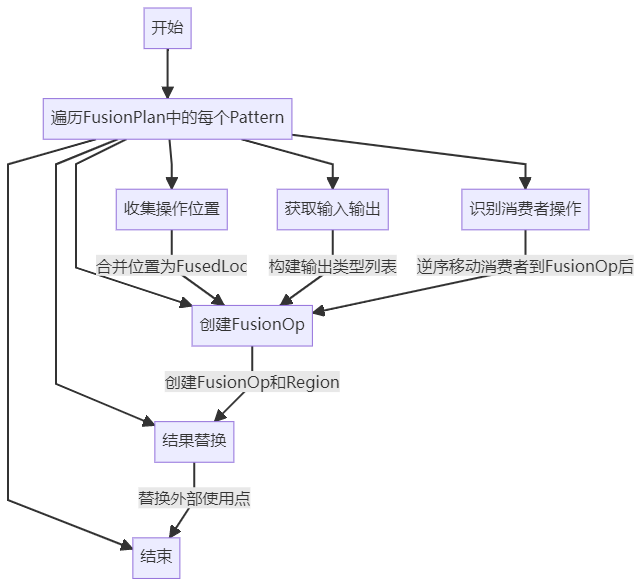
其中比较核心的是识别消费者操作,该consumer要求是直接或间接依赖fusion里的operation,但本身并不是fusion operation,并且其location在fusionOp的范围内,因此需要显示地移动。
BladeDISC source code分析
BladeDISC的kernel 融合主要参考AStitch和titch fusion。
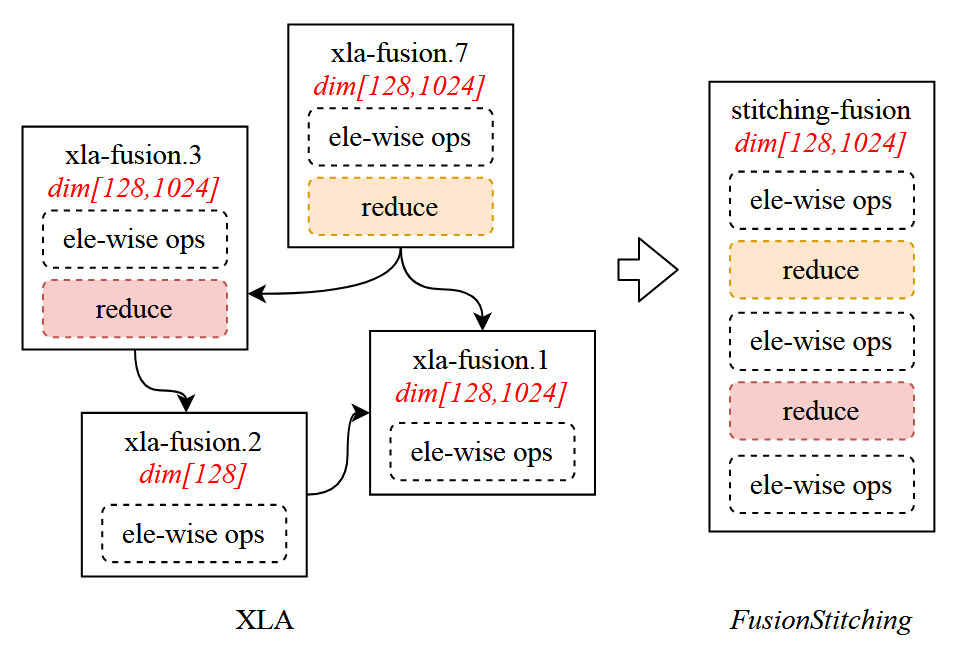
上述很好地阐述了应用XLA和fusion stitich技术的差异。XLA编译器无法对middle reduce操作做fusion,fusion stitch划分四类memory intensive op融合方式,起到有效扩展作用:
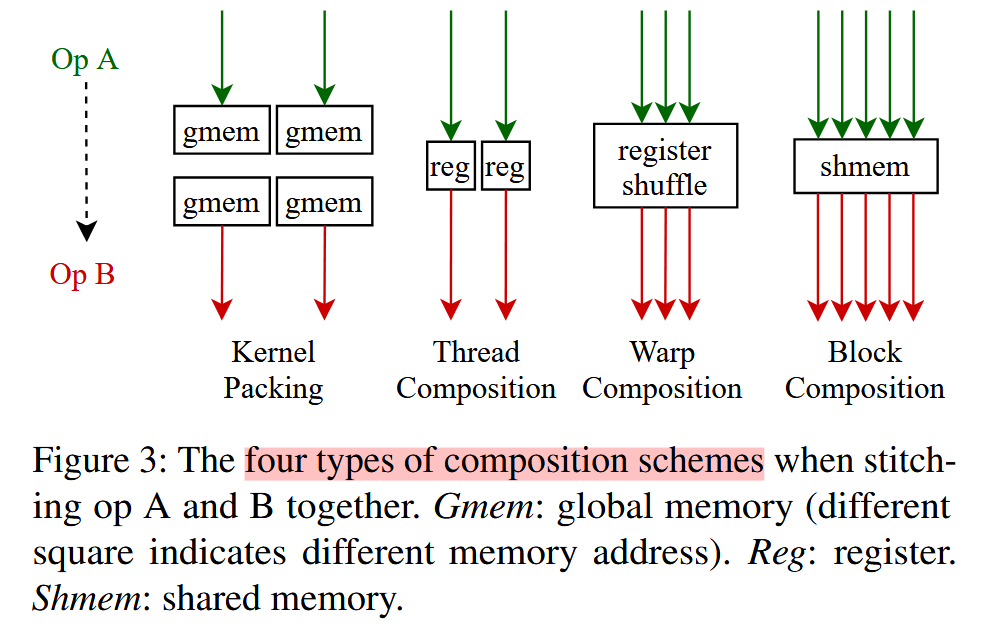
Source code解读
一个总的框架:
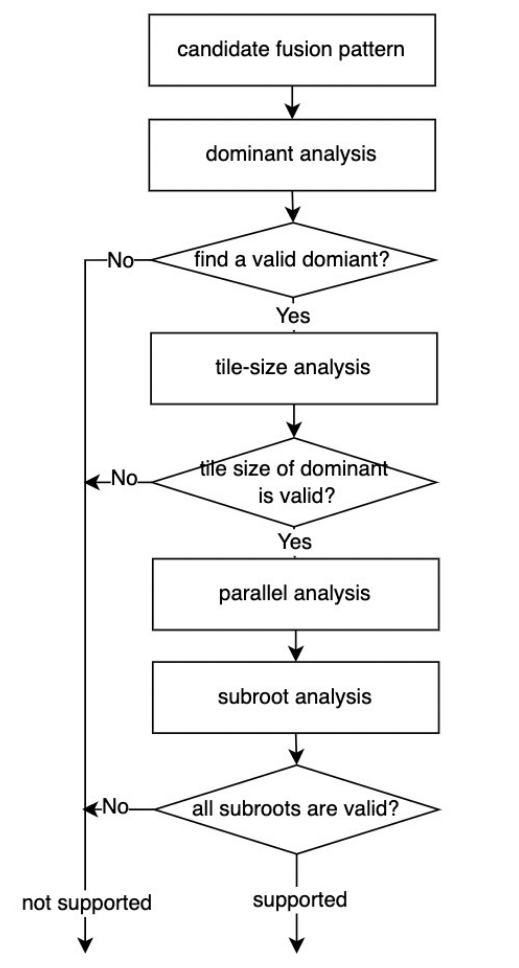
上述详情参考BladeDISC slide。
节点类型划分
stich的fusion pattern中,相比xla,其重点是将node划分为不同的类:
1 | // Represents a list of lmhlo ops that are going to be fused. |
上述注释中详细解读了node的分类:
- Root op:
fusion-pattern的output node,即fusion的边界。 - Sub-root op:通过shared-memory fuse的op。
- xroot op:在astich论文中,每个op的thread感知分配信息,都是通过分析sub-root或是root,然后反向传播到整个fusion区域。xroot op是分析出thread信息的root或sub-root
- Irregular xroot:没有分析出thread信息的sub root或是root op。
- Skeleton op:负责构建动态shape的并行循环骨架,是GPU kernel代码生成的模板基础。通过选择具有典型计算特征的子根操作(如行归约)作为骨架,能够自动推导出循环维度、分块策略等关键参数。主要负责codegen部分。
Shape analysis
GPU Stitch策略
1 | // 重点关注如何将stitch技术用在gpu上 |
整体的流程框架如下:
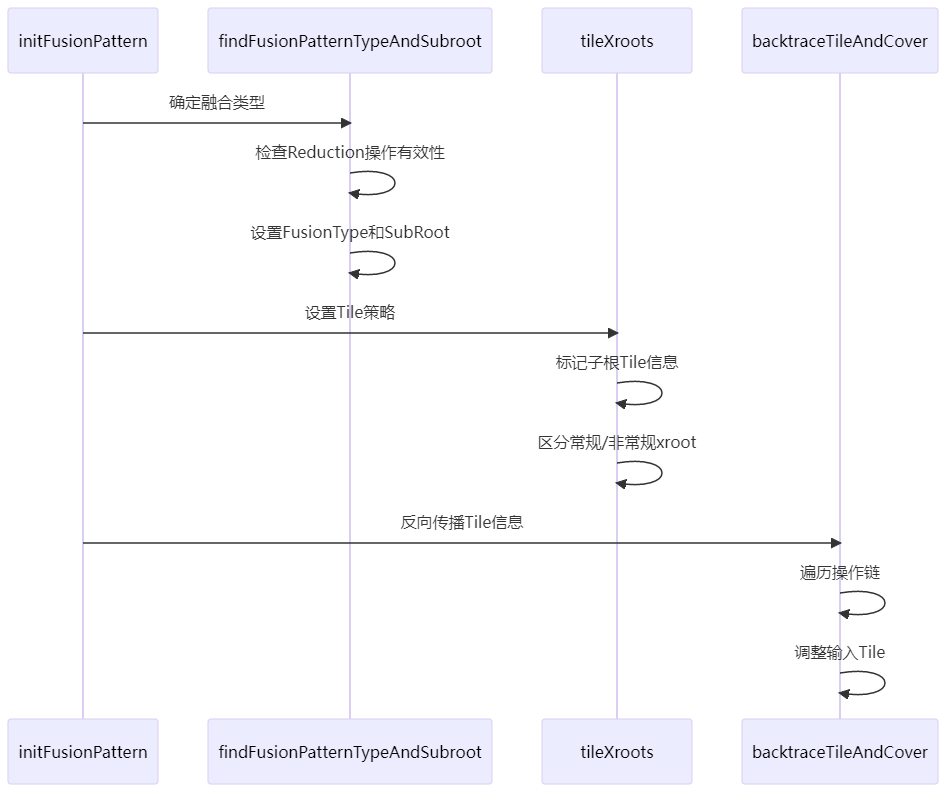
上述流程图很好的表达了整个流程框架:
initFusionPatter负责初始化fusion的option信息findFusionPatternTypeAndSubroot负责引用fusion,找寻subroot等特殊节点,其整体逻辑如下: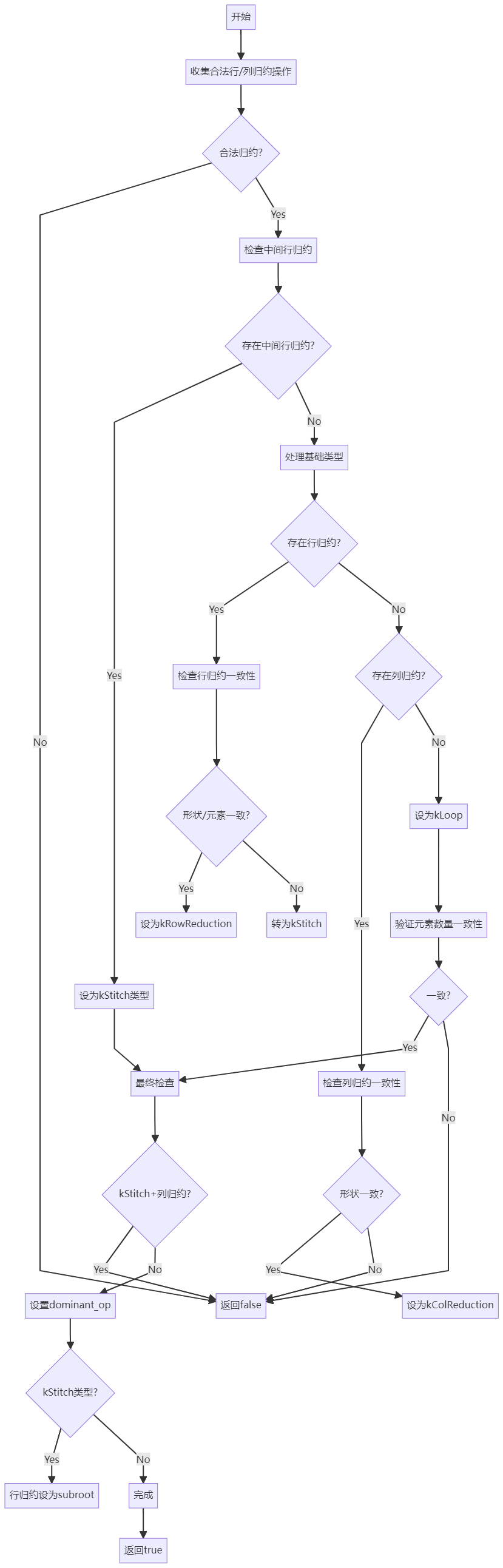
tileXroots针对sub root做线程分配算法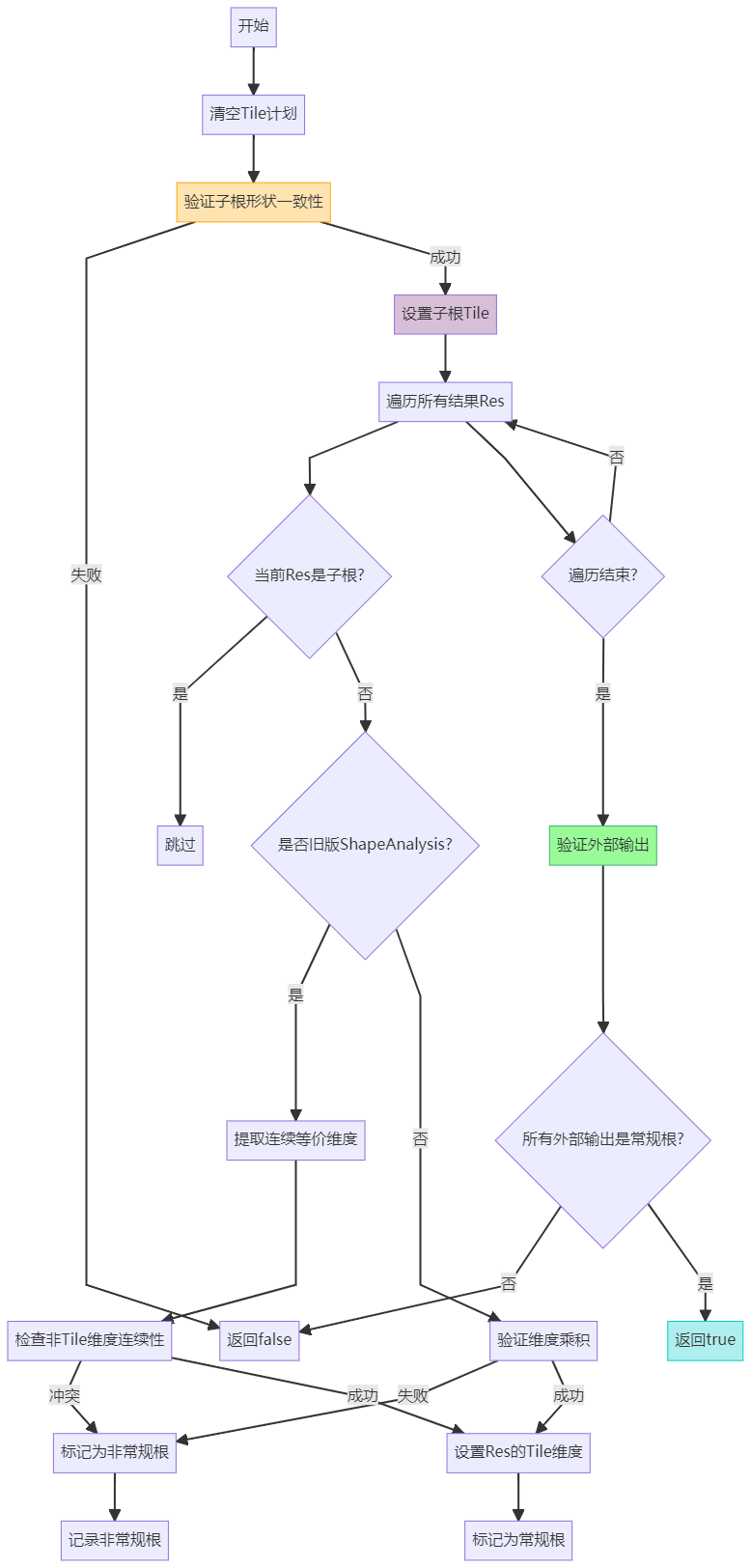
backtraceTileAndCover在一个fusion中,从不同sub root出发,做反向thread分配推导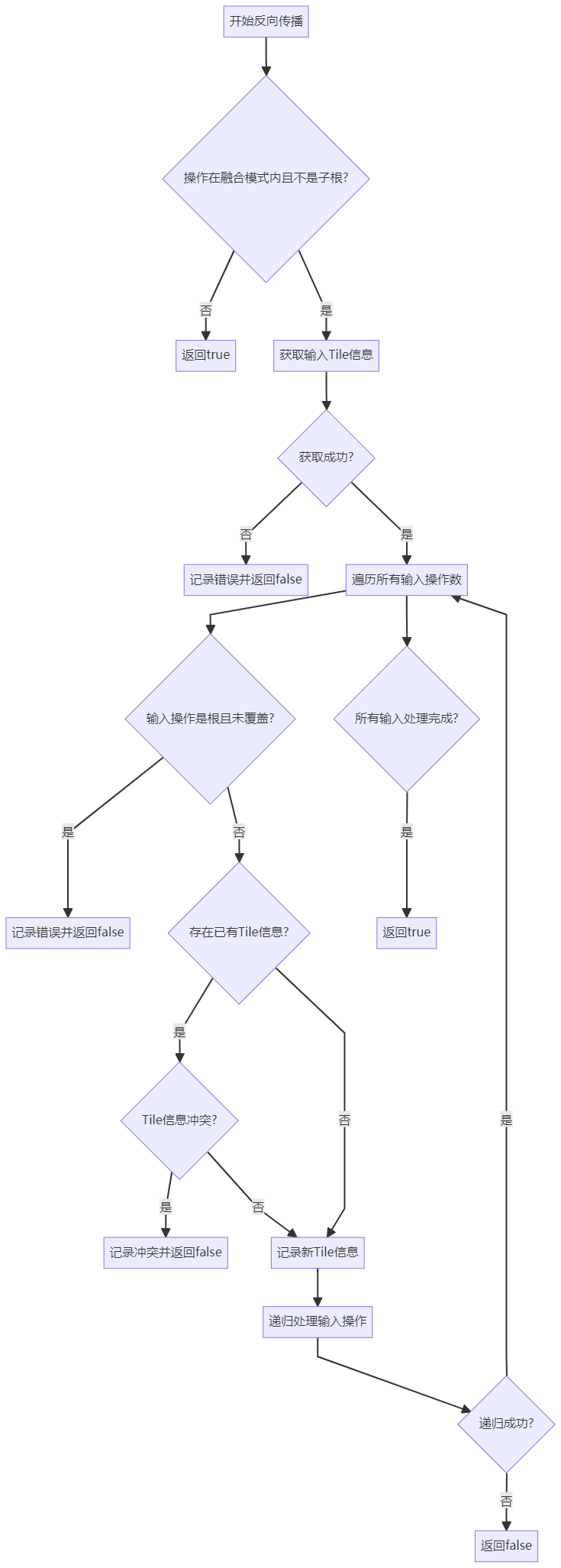
对应论文中的图片:
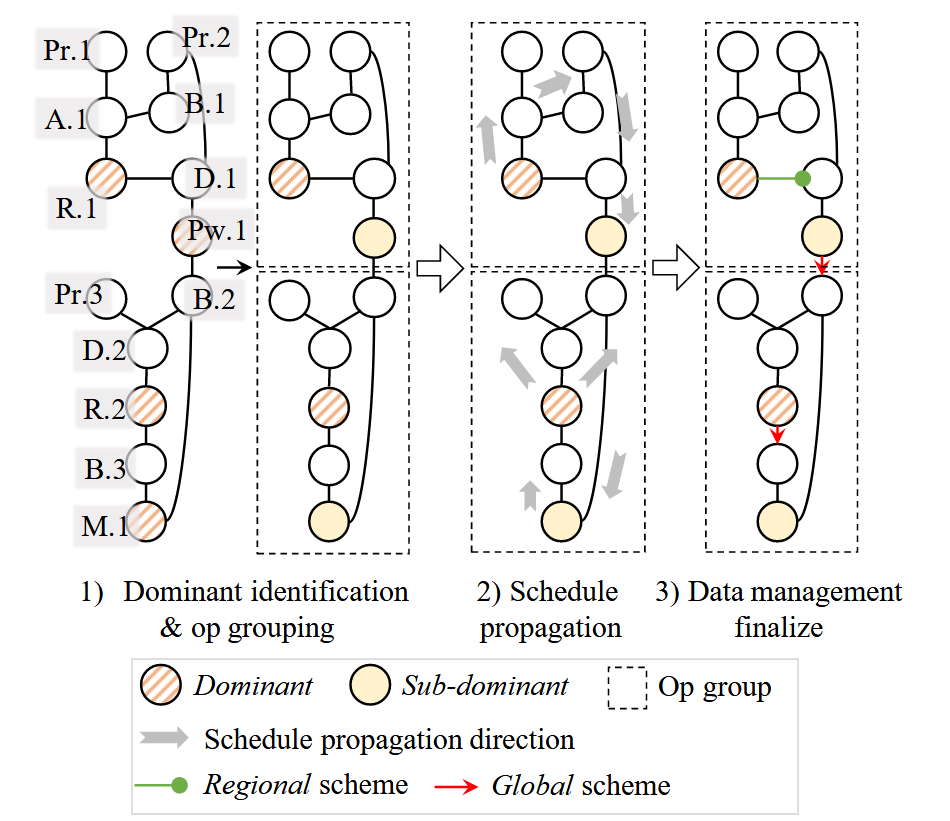
上述source code和论文中的对应描述参考论文中的chapter4.3的steps。