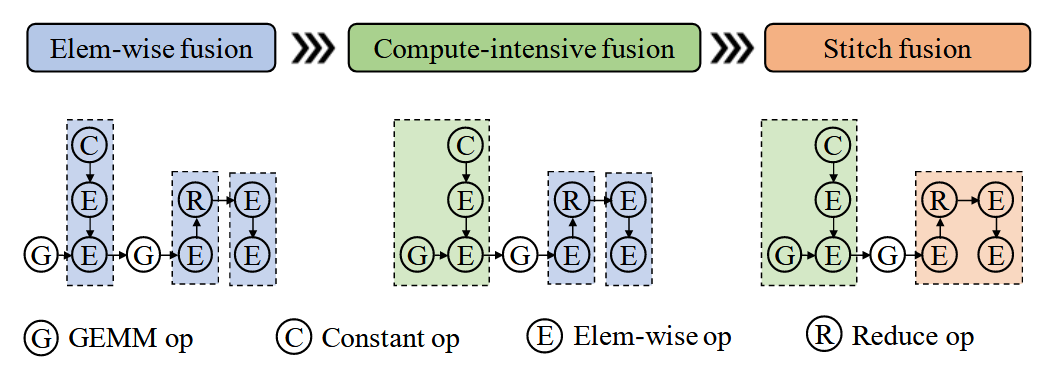
机器学习中算子可以分为计算密集算子和访存密集算子,之前的博客已经讲解了访存密集算子融合技术,本文重点解读计算密集算子融合,即针对gemm等算子的计算优化。本文主要结合BladeDISC和Rammer等文章加以解读
BladeDISC的计算密集算子融合
计算密集算子融合pipeline overview
在BladeDISC项目的pipeline中,涉及计算密集算子融合有三处:
针对简单的mhlo_dot算子做融合

具体流程图如下:
flowchart TD
A[开始: DiscDotMergePass] --> B[执行共享操作数合并]
B --> C[执行批量合并]
C --> D{合并成功?}
D -->|是| E[结束]
D -->|否| F[标记失败]
subgraph 共享操作数合并流程
B1[遍历所有基本块] --> B2[初始化ShareOperandMap]
B2 --> B3[遍历block中的DotGeneralOp]
B3 --> B4[提取共享操作数和维度信息]
B4 --> B5[构建聚类映射]
B5 --> B6[检测循环依赖]
B6 --> B7[尝试合并聚类]
B7 --> B8[应用合并操作]
B8 --> B9[清理原始操作]
end
subgraph 批量合并流程
C1[形状分析] --> C2[构建MergingShapeMap]
C2 --> C3[检测可合并聚类]
C3 --> C4[维度扩展操作]
C4 --> C5[创建批量concat]
C5 --> C6[生成批量dot]
C6 --> C7[切片替换原始操作]
C7 --> C8[清理原始操作]
end
B -->|核心操作| B1
C -->|核心操作| C1
B9 -->|清理后| C
C8 --> D
混合精度优化
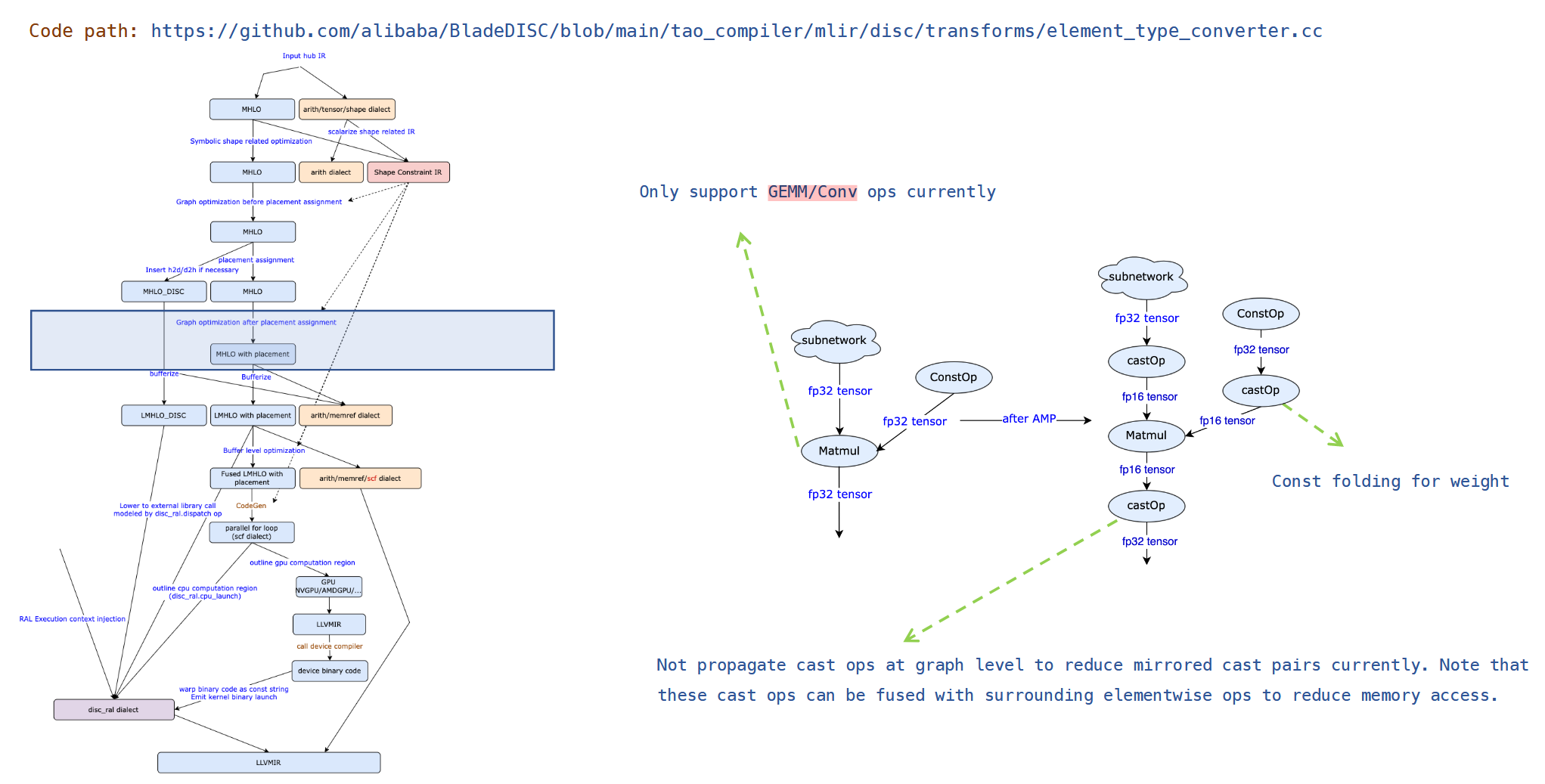
针对GEMM做layout优化
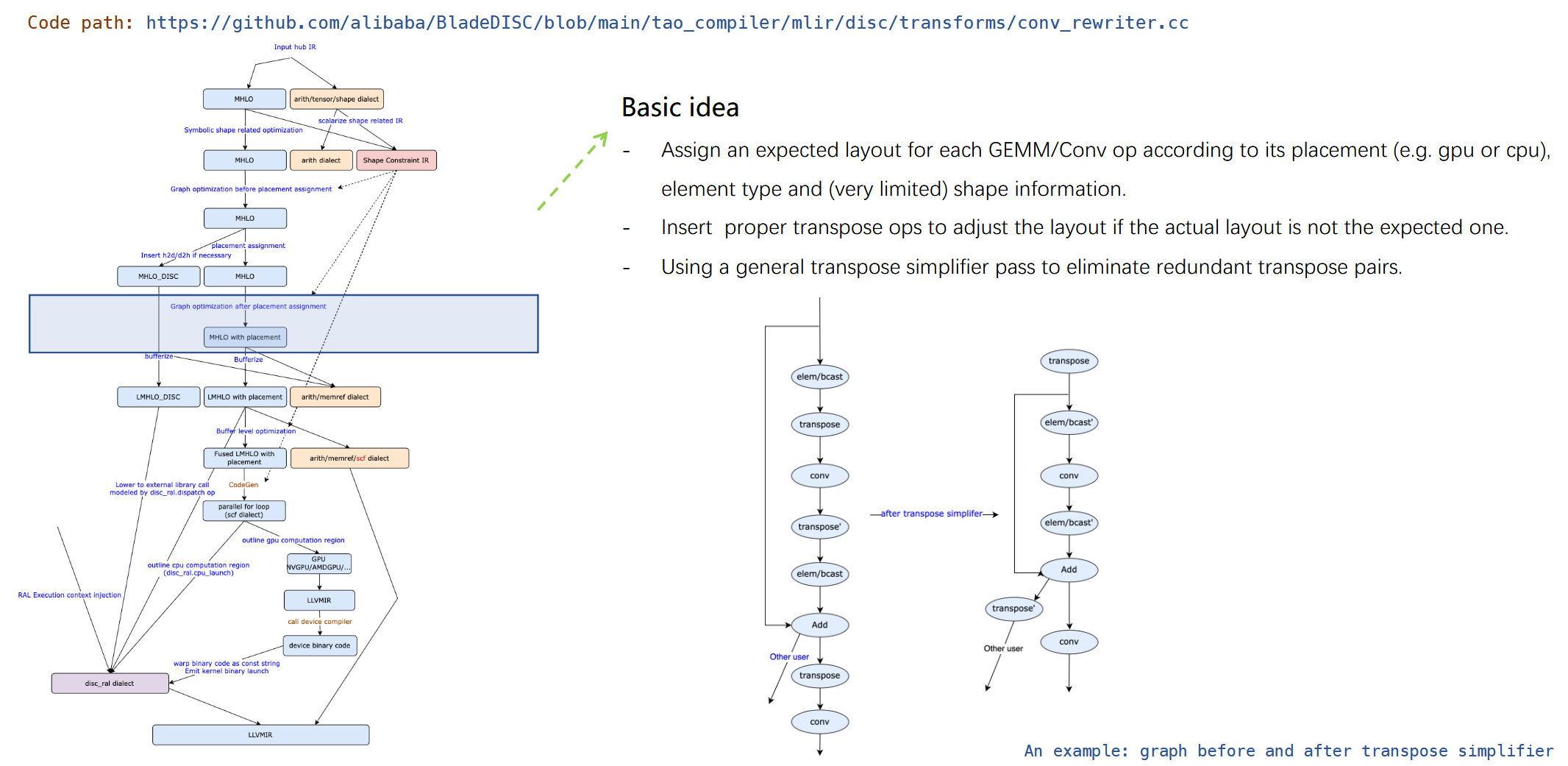
具体流程图如下:
graph TD
A[原始卷积操作 mhlo::ConvolutionOp] --> B[转换为 DynamicConvOp]
B --> C[提取卷积参数]
C --> D[推断预期布局]
D --> E{当前布局符合预期?}
E -->|是| F[保持原布局]
E -->|否| G[插入转置操作调整布局]
G --> H[输入布局调整]
G --> I[滤波器布局调整]
G --> J[输出布局调整]
H --> K[更新输入布局]
I --> L[更新滤波器布局]
J --> M[更新输出布局]
K --> N[更新卷积属性]
L --> N
M --> N
N --> O[优化后的卷积操作]
P[量化卷积操作 QuantizedDynamicConvOp] --> C
Q[GPU/CUDA环境] --> D
R[CPU环境] --> D
style A fill:#f9d,stroke:#333
style P fill:#f9d,stroke:#333
style B fill:#bbf,stroke:#333
style C fill:#cfc,stroke:#333
style D fill:#cfc,stroke:#333
style E fill:#ffd,stroke:#333
style G fill:#fcc,stroke:#333
style N fill:#cfc,stroke:#333
style O fill:#9f9,stroke:#333